What Is PCA?
Principle Component Analysis (PCA) can be defined as a method that uses Associate orthogonal transformation that converts a group of related variables to a group of unrelated variables. PCA may be a most generally used tool in beta knowledge analysis and in machine learning for prophetical models. Moreover, Principle Component Analysis is Associate in unattended applied math techniques and will examine the interrelations among a group of variables. It’s additionally called a general correlational analysis wherever regression determines a line of best work.
Why Principle Component Analysis?
- We might want to cut back the dimension of our options if we’ve got a great deal of redundant knowledge.
- To do this, we discover 2 extremely correlative options, plot them, and create a brand new line that appears to explain each option accurately. We have a tendency to place all the new options on this single line.
- Doing spatial property reduction can cut back the whole knowledge we’ve got to store in storage devices and can speed up our learning rules.
- It is harsh to check information that’s quite 3 dimensions. We are able to cut back the scale of our information to three or less so as to plot it.
- We need to seek out new options which will effectively summarize all the feature options.
Example: many options associated with a country’s national economy might all be combined into one feature that you just need to decide is “Economic Activity.”
Then, when?!
- Do you need to cut back the quantity of variables, however aren’t ready to establish variables to utterly take away from consideration?
- Do you need to make sure your variables are free of one another?
- Are you comfy creating your independent variables less interpretable?
If you answered “yes” to all or any 3 queries, then PCA could be a smart methodology to use 😉 . If you answered “no” to question three, you ought to not use Principle Component Analysis.
How does Principle Component Analysis work then ?!
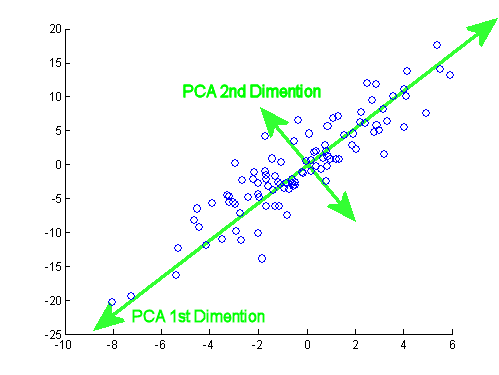
Given 2 options, x1 and x2, we wish to search out one line that effectively describes each option quickly. We have a tendency to then map our recent options onto this printing operation to induce a replacement single feature.
The same may be finished in 3 features, wherever we have a tendency to map them to a plane.
The goal of PCA is to scale back the typical of all the distances of each feature to the projection line. This is often the projection error.
Generalization can be done as:
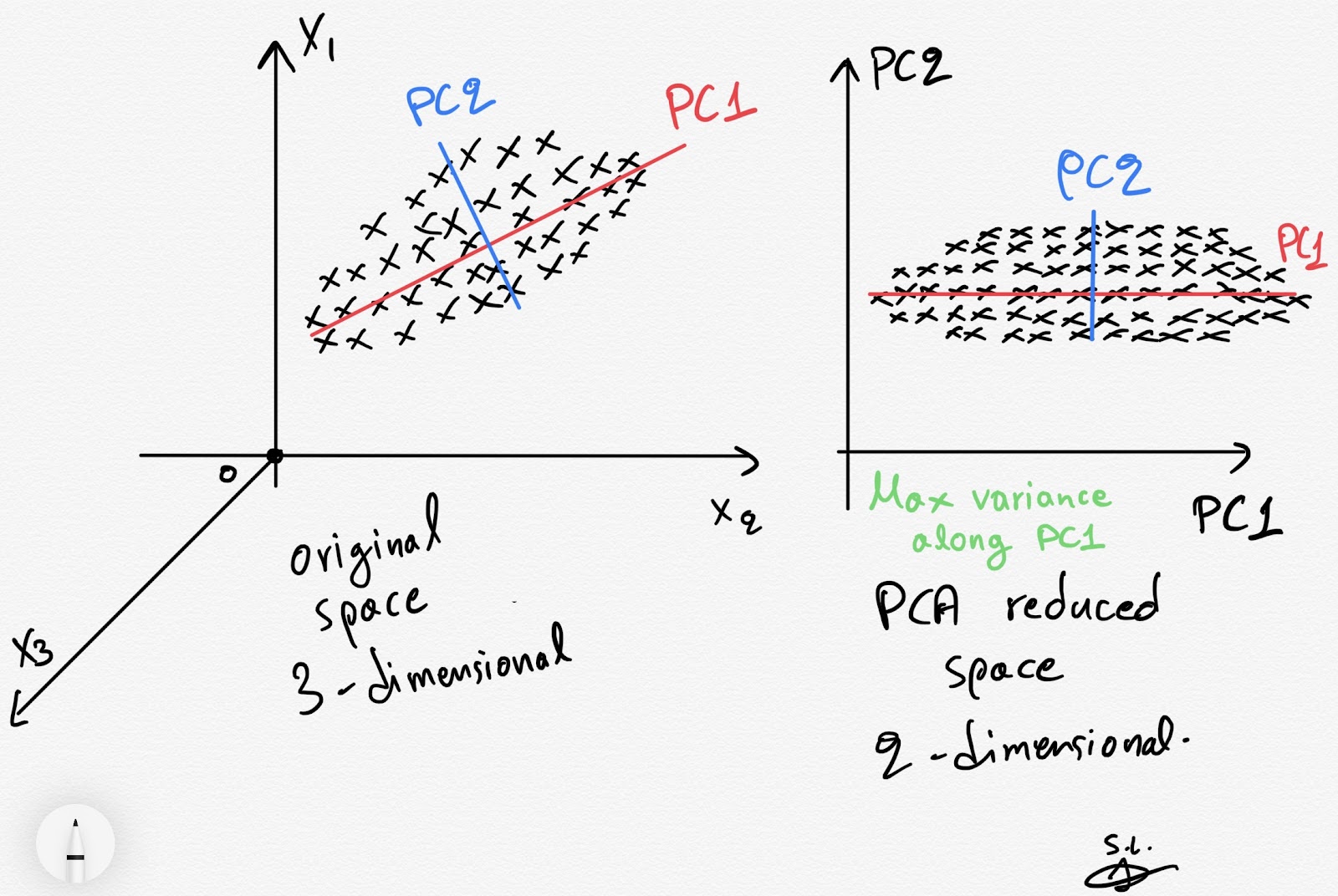
Reduce from n-dimension in dimension to k-dimension: Find k vectors u(1),u(2),u(3),u(4)…..u(k) onto which to project the data so as to minimize the projection error.
If we are converting from 3d to 2d, we will project our data into two directions (a plane), so k will be 2.
Wait!! Caution!!
Note that there is a lot of difference between PCA( Principle Component Analysis ) and Linear Regression because In statistical regression, we have a tendency to minimize the square error from each purpose to our predictor line. These are vertical distances.
In PCA, we have a tendency to minimize the shortest distance, or shortest orthogonal distances, to our information points.
More usually, in statistical regression we have a tendency of taking all our examples in x and applying the parameters in Θ to predict y.
Steps to Follow while Principle Component Analysis:
1.)Compute “covariance matrix” , let us assume our matrix as sigma-
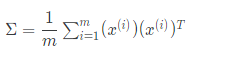
We denote the covariance matrix with a capital sigma (which happens to be the same symbol for summation, confusingly—they represent entirely different things).
2.)Compute “eigenvectors” of covariance matrix-
So we have some built-in functions accordingly to compute the eigenvectors and can be achieved by using respective functions in respective programming languages and let, for instance consider eigenvectors as U
3. Take the first k columns of the U matrix and compute z-
We’ll assign the first k columns of U to a variable called ‘Ureduce’. This will be an n×k matrix. We compute z with:
z(i) = (UreduceT)(x(i))
So the matrix has dimensions k×n while x(i) will have dimensions n×1 and the product will have a dimension of k x 1. So we are able to produce the required number dimension from the above process and could bring down the dimensions to the desired number.
Summary and Farewell:
I hope you found this article helpful! Check out some of the resources below for more in-depth discussions of PCA. The most common use of PCA is to speed up supervised learning.
And finally it is always better know the bad side (bad use) of PCA:
trying to prevent overfitting. We might think that reducing the features with PCA would be an effective way to address overfitting. It might work, but is not recommended because it does not consider the values of our results y. Using just regularization will be at least as effective.
Don’t assume you need to do PCA. Try your full machine learning algorithm without Principle Component Analysis first. Then use Principle Component Analysis if you find that you need it.
Finally , Hope this blog brings a greater insight for applying and grabbing a wholesome knowledge regarding PCA(Principle Component Analysis).
written by: Naveen Reddy
reviewed by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs