

In a lot of business analytics problems, the estimators are trained with a huge dataset. Such types of data might have high dimensions.
The high dimensional data can consume a lot of computational time and some unwanted patterns tend to overfit. Decomposition of this sort of data would lead to better performance and results.
The decomposing of data extracts brand new data features or patterns from the given initial data. Feature selection (check out my previous blog on Feature Selection) eliminates the unwanted features but decomposition Of Signals techniques design new features from given.
so, few widely used methods in the matrix factorization problem are essentially “Principal Component Analysis, Latent Dirichlet Allocation”.
Principal Component Analysis | Decomposition Of Signals:
PCA constructs a set of artificial sets of variables that accounts for the maximum variance in original data, making the data more visible by interchanging the axis. These artificial sets of variables are also known as principal components. The data should be normalized before doing PCA because it is very sensitive to outliers.
Considering data with p components, PCA selects the first k components which exhibit maximum variance. The remaining p-k components are lost in the projection. Having said that, we have chosen first k components, not simply some random k components. The purpose of selecting those first k components is to retrieve the lost information from p-k components.

The rotation of the axis is done based upon the direction which explains the most variance in the data. The direction of components is based on the eigenvectors and eigenvalues. Insignificant variables or components might be lost during the transformation of components. so, By this transformation, high dimensional data can be easily interpretable and compilable.
Latent Dirichlet Allocation:
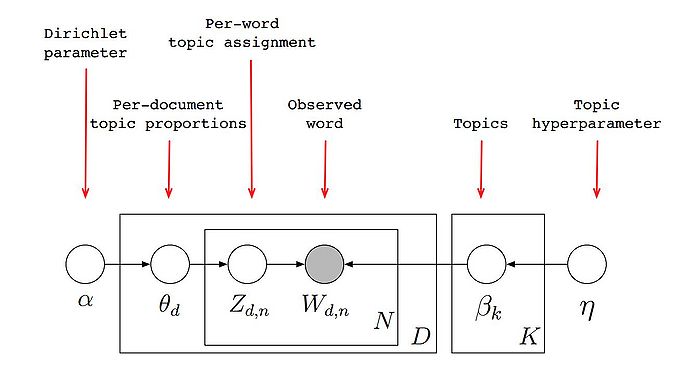
LDA represents identifying the topic for a given document with the Dirichlet distribution of sampling a topic of the document and also sampling the words of the document individually. This method is also named the “generative probabilistic model”. Latent Dirichlet Allocation is widely used because of its ability to reduce the number of parameters to solve the topic modeling problems.
Latent Dirichlet Allocation is mostly used in Natural Processing Language for the topic modeling. I will give my intuition on LDA with a real-time application of the topic modeling. Considering there are 500 documents and 1000 words and 10 topics, the task is to determine the topic of the document. thus, Based on the words in a document, the topic of a document can be explained.
To do this with the bag of words method we would have required 500*1000=500,000 parameters, but the LDA does this with only 500*10+1000*10=15,000 parameters by decomposing matrices. This concept can easily interpretable with the below figure.
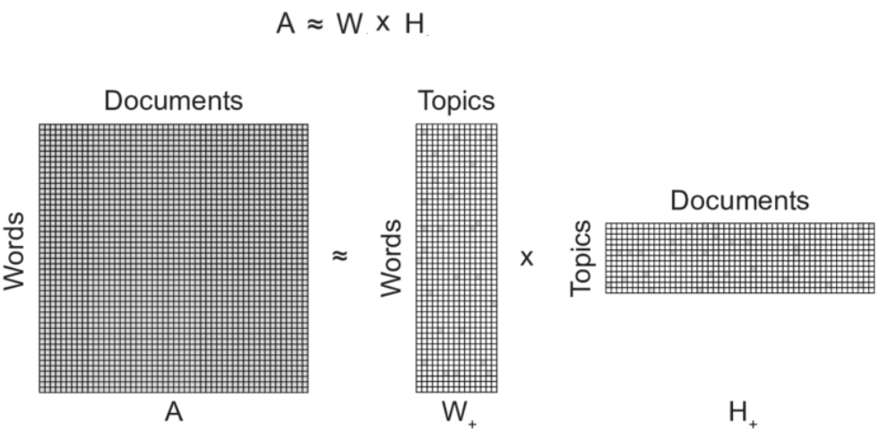
We have discussed the overlook of the LDA, let’s look deeper with the distribution of data. The topic of the document is estimated with the Dirichlet Distribution, here each document(Doc1)is given with probabilities(Ө) based on how close the document is to each topic ( EX:0.4 for sports, 0.2 for politics, 0.4 for science). Notice the H+ matrix in the above diagram, where all the rows are mentioned with the probability of the document.
The same process is applied for the word-topic relation with the distribution of higher dimensions, the probability of word belongs to each topic is given with parameter(β), observe the matrix(W) in the above diagram.
For a given “words-document” matrix, the LDA splits that matrix into words-topic and topic-document matrices. Please visit this page for the implementation of LDA in sci-kit learn.
Summary:
so, The decomposition Of Signals of data is complete by extracting the new featured data with matrix factorization methods. These methods are often also called feature extraction techniques. however, The high dimensional data is familiar with Machine Learning. To visualize and understand the data completely the above methods are advisable. To know more about Matrix Factorization methods refer to this page.
Written by: Yeswanth chowdary
Reviewed By: Savya Sachi\
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs