
We have already covered Collaborative based filtering used in the recommender systems. In any case, the scenario is as follows:
You are at home on a Friday night after an exhausting week, and you’re in the mood to relax with some food. However, your lack of decisiveness coupled with an infuriating number of options to choose from.
for both the food and the movies, leave you feeling completely drained. Soon after you realize that you’ve hardly got any time left before hitting the bed.
Afterward, decide to just pick a movie you’ve seen dozens of times and eat the usual food. A rather unexpectedly boring start to your weekend!

Recommender systems come in handy in such situations. They do all the work for us and make the weekends far more enjoyable!

Types of Recommender Systems
The most frequently used methods – commonly called Filtering methods, are
o Collaborative Filtering – relies on the similarity between different users
o Content-based Filtering – relies on the similarity between the content of items (user-specific)
This post covers the latter.

Content-Based Recommender System:
using the example of the movie to explain the process, we explain the technique applies to any situation that requires recommendations.
The system makes recommendations based on the similarity of items in a user’s profile. A User Profile contains information on their preferences, past views or ratings, etc. An item here refers to movies but in general, refers to the content of the service provided. for example, cuisine in a food delivery app. The key calculation here is that for the similarity of items in the profile. The measurement concerns the similarity of the content of the movies – hence the name Content-based filtering.
Note: content does not refer to the actual content or script of the movies themselves. rather it describes the characteristics like genre, category, tags etc.

The system notices the user’s activity – meaning what movies the user left ratings for and the content of those movies are. As seen in the image, the user likes the movies The Avengers and Spiderman. The algorithm working on the background checks the content of these movies and recommends those that are most similar – i.e. Fantastic Four
Let’s analyse what goes on in the background!
Assume that we have access to a dataset of a random user. Additionally, it has 6 examples or data points. The dataset is merely a collection of what the user has already watched and their genres.
Let’s also assume that the user has left ratings for three movies on that list. Our model – i.e. the algorithm or system, will now have to predict the possible ratings that the user leaves. Until the remaining three movies and accordingly recommend them.

Although there are several methods to perform these calculations, vectorisation is a highly efficient one and as such, it tends to be used more often.
The ratings provided by the user first convert them into vectors. Then, to differentiate between the genres of the movies with the ratings, we use the One Hot Encoding method. This creates a matrix of binary representation for the various genres and enables the algorithm to numerically describe the movies.

We now have a User rating vector and a Movie Matrix. If we were to multiply the values of the rows of the matrix with their corresponding rating value, we would obtain the Weighted matrix for the movie genre.
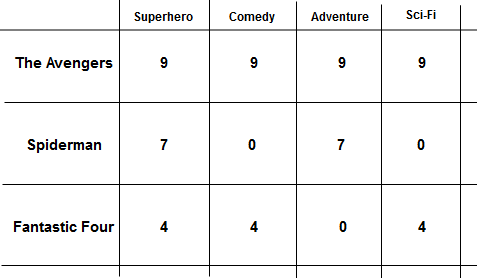
The matrix is generally mapped into a vector by aggregating (summation) the column values and normalising them. This indicates the preferred genre for that particular user. The vector is commonly called the User Profile.

From the calculations, we can conclude that the user has the strongest preference for Superhero movies.
So, we have in hand the user’s profile in a normalised numeric format and we also have a bunch of movies that we need to predict ratings for. What do we do next?
One Hot Encode
We take those remaining movies from the dataset and One Hot Encode them just as we did above. This matrix is then multiplied element-wise by the User Profile vector to obtain a weighted representation of the movies and their genres.

The final step is to aggregate the row values and obtain the final weights corresponding to each movie – which forms the Recommendation Vector. This indicates the preferences for the user. The vector element with the highest value is the movie that is recommended to the user.
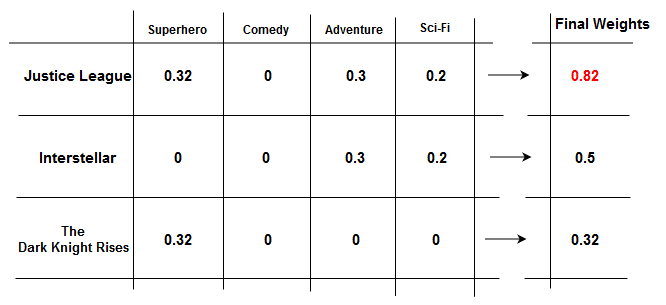
From our calculations, we can conclude that Justice League would be given the highest rating by the User and hence recommend the same to them.

The process appears far less complicated than the Collaborative approach, right?
While that may be true, this method is not as robust. The major drawback here is with how the algorithm deals with items that are not part of the User Profile. The profile is built using movies that have been watched and/or rated by the user and as such, it can only recommend movies with similar characteristics (genres).
For example, if a user has only watched and rated science-fiction movies in the past and has never come across a horror movie, then the algorithm will never suggest the horror genre to that user.
Observations | Recommender Systems
This wouldn’t be a problem if the person doesn’t prefer horror movies, but it exposes the lack of flexibility in the system. If the same user inexplicably finds themselves in the mood for a good horror or thriller movie, they would yet again be stuck with a myriad of options to choose from – rather than being provided with the best ones on a silver platter.
This is where collaborative filtering methods exhibit their superiority. Since the similarity measures in that approach take into consideration the actions of various users and their relationships rather than the user-specific content itself, there is a greater chance of users being provided with diverse recommendations.
Drawbacks Of Recommender Systems
Another drawback in our implementation above is the use of One Hot Encoding. While it does provide a satisfactory solution, it can prove to be computationally expensive and inefficient at times. In our example, we had only dealt with four distinct genres and six different movies. There are numerous genres available and most people tend to be diverse in their selections. As a user’s diversity and watched movie list increases, the size of the matrices increases as well.
Hence, This can lead to very large matrices being processed which could in turn drastically reduce the performance of our model. Although the vectorisation method was introduced to prevent this very problem, there are limitations to it as well, especially considering our choice of encoding.
We can, however, use different encoding techniques to improve our model’s performance. Although mostly used for text mining, the TF-IDF or term frequency-inverse document frequency encoding method is very popular in this field. Recent developments in the field of Deep Learning have led to the use of Neural Networks to perform the same processes. Neural Networks have impeccable efficiency and performance levels, and as such it is becoming increasingly common to come across their implementation.
Conclusion:
These methods are used in almost every service offered these days. From Facebook or Instagram’s follower’s suggestions to food recommendations and even products to buy on e-commerce websites. It is impossible not to come across Recommender Systems.
Article By: Shivaadith Anbarasu
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs