
The likeliness of an event to occur or the proposition to be true is known as the probability of an event. Bayesian learning is that part of probability which deals with partial beliefs. Bayesian Estimate, on the other hand, calculates the validity of a proposition. This value of proposition is based on 2 things.
- Prior Estimate of the probability
- New Relevant evidence.
Based on this, the posterior Bayesian learning is achieve and the key to this is an important theorem called Bayes Theorem.
Bayes Theorem | Bayesian Learning
Bayes Theorem in Bayesian Learning deals with how to find the probability of a hypothesis given the data P(h/D), where,
- h is the hypothesis,
- D is the given data.
If there are different competing hypotheses, then the probability of the individual hypothesis, given the data, can be found out and thereby draw a conclusion which is the most likely hypothesis. Thus we have,
P(h/D) = P(D/h) P(h)P(D)
Here,
- P(h) is prior probability;
- P(D/h) states that if h was true what is the probability of D being generated.
- P(D) is the likelihood of data.
The goal of Bayes Learning is to use Bayes theorem to find the most probable hypothesis given the training data. This most probable hypothesis is known as Maximum A Posteriori (MAP) hypothesis. It is given as
hmap= argmax P(h/D); h∈H
Expanding P(h/D) using Bayes Theorem,
hmap= argmax P(D/h) P(h)P(D)
H is the hypothesis space and h represents that hypothesis which satisfies the above expression out of all hypotheses in the hypothesis space. Since P(D) is independent of h. So we can remove P(D) and simply maximise
hmap= argmax P(D/h)xP(h)
If for all the hypotheses, the probabilities are equal then we choose that hypothesis for which P(D/h) is maximum. So hML ; the maximum likelihood hypothesis is applicable in those cases where the prior probability of all hypotheses are equal. That is, before there is any data, all the hypotheses are equally probable. Thus that hypothesis is chosen where P(D/h) is maximum. This is given by,
hML= argmax P(D/h)
An example:-
Let us consider an example of how in finding the least squared line (linear regression), concepts of Bayes theorem can be used to determine the most probable hypothesis. Suppose that a real valued function is given and we have to learn this function. Let f be the target function and the individual data points are given as (Xi,di), where
di = f(xi)+εi
εi is the error and an underlying assumption is that the error follows a normal distribution with mean 0 and standard deviation . So di can be thought of as
di N( f(xi) , 2)
2 is the variance which corresponds to the error term. Let us also assume that εi are independent for different instances and is a gaussian with mean 0 and variance2.
In the figure below, let the red line be the true function (f(x)). Let the data obtained be represented by the dots as shown.
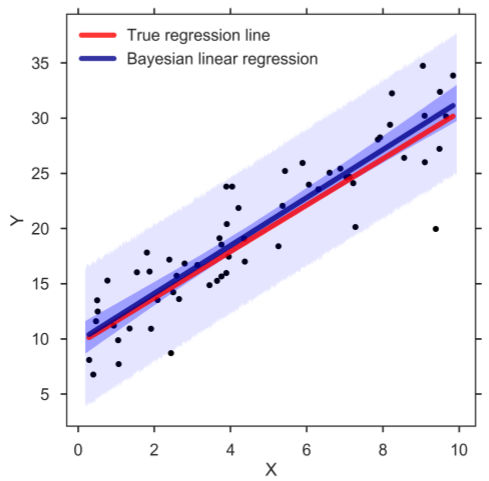
SOURCE: Simple Linear Regression and Bayes Learning https://images.app.goo.gl/GubQVS23ozR9p8qN7
Our aim is to find a function which estimates f. To do so we turn towards the maximum likelihood hypothesis.
hML= argmax P(D/h)
Since Gaussean distribution is followed we have,
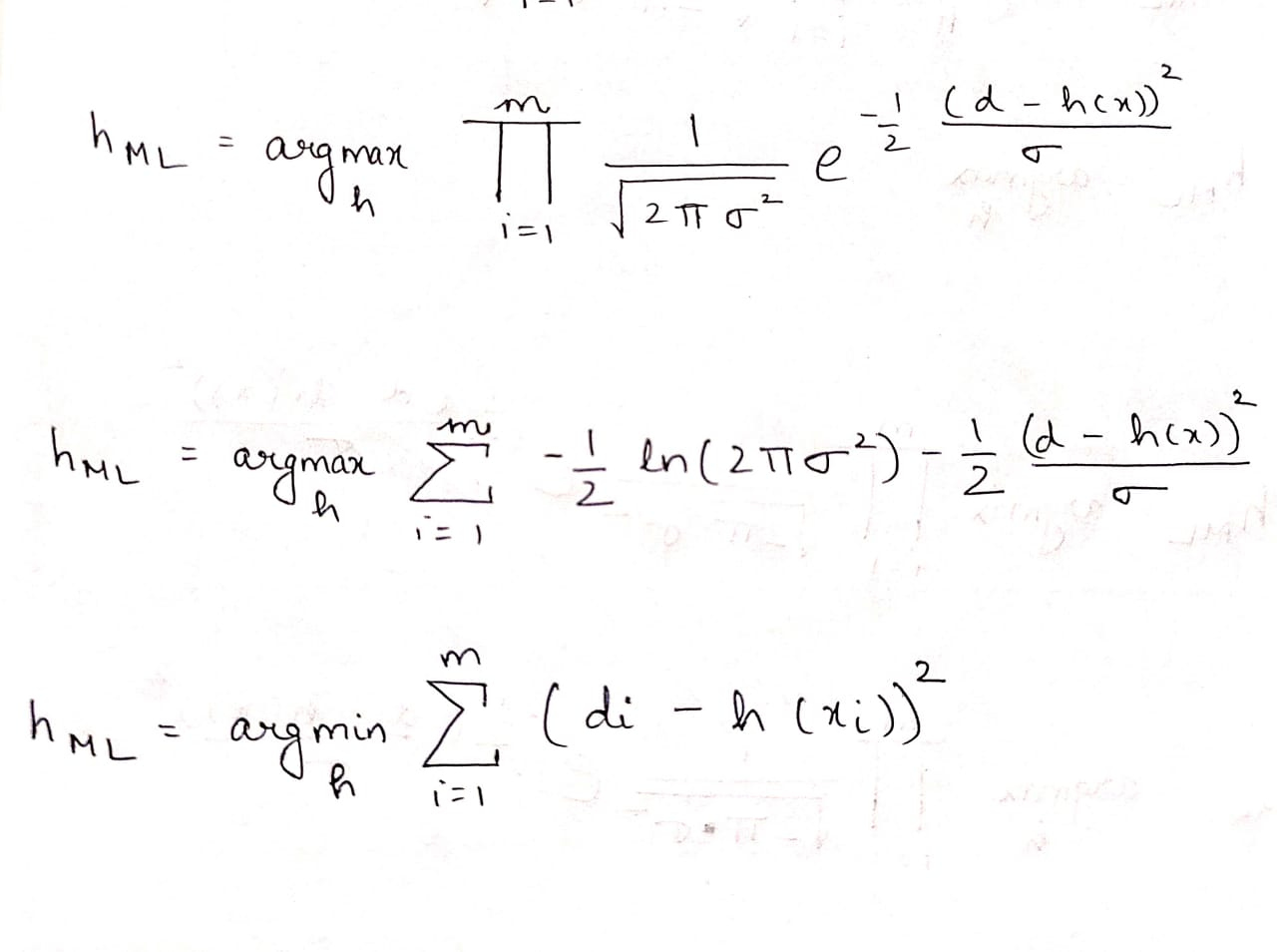
….(1)
Taking Natural log, we have
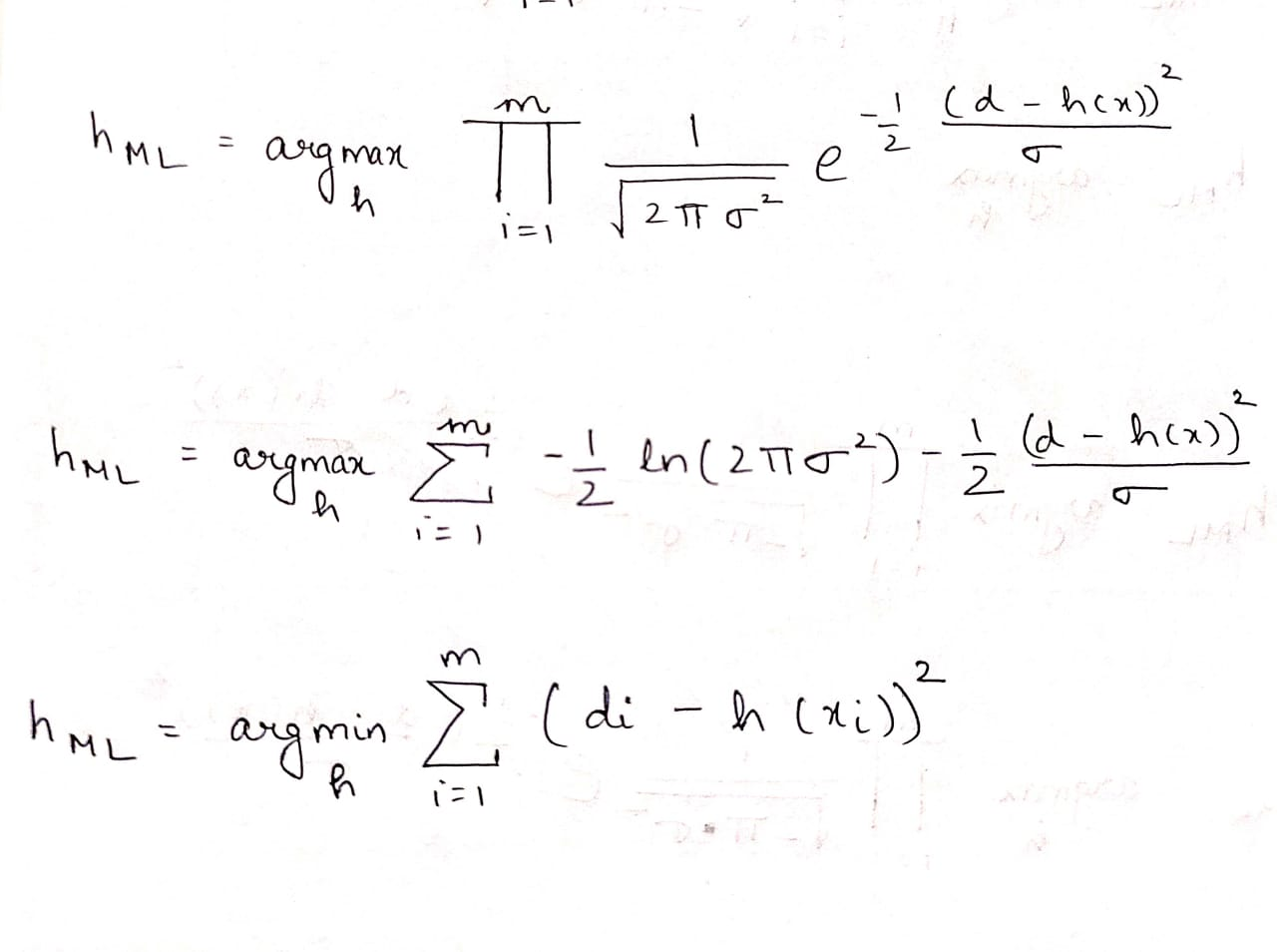
Since -½ ln (2π2) is constant so when we take the hypothesis for which the above expression inside the summation is maximised, the constant part does not influence it. The second part in equation 2 determines hML. Again (½) and does not play a role in maximising hML. Thus
hML = argmini=1m(di- h(xi))2…(2)
The argmax will be converted to argmin as maximising a negative number is the same as minimising the positive equivalent. So the maximum likelihood hypothesis for the linear regression problem, is when (di- h(xi))2is minimised. This is also the criteria of least square. Thus based on the above we may get a function like the one with blue colour. The blue lines in the figure represent the sum of squared errors that is minimised. The above is the Bayesian Learning of minimisation in order to find out the linear regression.
Bayes Optimal Classifier
Suppose that there is some training data, with the class it belongs to. Also, a test instance is given, and our aim is to determine the optimum classification of x. The answer that might come to our minds would be that the most probable hypothesis can be found out using the MAP criteria and then that hypothesis can be applied to the test example. But this need not be the case.
So, using training data, hMAP (the most probable hypothesis) was learnt. But the most probable hypothesis is not the most probable classification.
Let us assume that h1, h2, h3 are the three competing hypotheses which belong to hypothesis space. Also , it is given that
P(h1/ D) = 0.4
P(h2/ D) = 0.3
P(h3/ D) = 0.3
Clearly the map classifier is h1as Maximum Posterior probability is that of h1.
Suppose a new data x is there with us, with;
h1 (x) > 0
h2(x)<0
h3(x)<0
If this the case, what is the most probable classification ofx? h1states that x is positive while h2 , h3 state that x is negative! The answer in this case is negative as the sum of probabilities of hypothesis h2 , h3(0.6) is greater than hypothesis h1(0.4). This is known as the Bayes Optimal Classification. In this classification, for a specific example, we consider the class to be;
Most Probable classification =argmax vj VhHP( vj / hi ) P(hi / D) …(3)
Equation 3 represents the Bayes Optimal Classifier. It gives that class which on taking sum over the entire hypothesis space yields the maximum value of P( vj / hi ) P(hi / D) ,for the given classification problem.
Gibbs Sampling
Using the same hypothesis space and same known history, no separate classifier can outperform this on taking average. Thus it is called an ‘optimal classifier’. But as we know the size of hypothesis space is gigantic, it is not feasible to use the Bayes Optimal Classifier. So an approximation of Bayes Optimal classifier is used. This is known as Gibbs Sampling.
In Gibbs sampling, sampling from the hypothesis space is done, in place of application of all possible hypotheses on the new data (x). A hypothesis is chosen randomly, in line with P(h/ D) . Thus a probability is associated with each hypothesis. Hence, over the hypothesis space, there is a probability distribution. A posterior probability distribution is obtained according to the training data (in other words evidence) over the hypothesis space. A single hypothesis is chosen from this distribution, and this chosen hypothesis is used to classify the new data.
For Gibbs algorithm, the error that is obtained is bounded. Thus over the target hypothesis (drawn at random) if the expected value is taken, in accordance with the prior probability distribution, then error in Gibb’s Classifier is less than twice the error in the Bayes Optimal classifier. Thus to classify the instance, from Gibbs sampling, a single hypothesis can be chosen, provided the posterior probability distribution has been computed.
Written By: Aryaman Dubey
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs