
What is K-means?
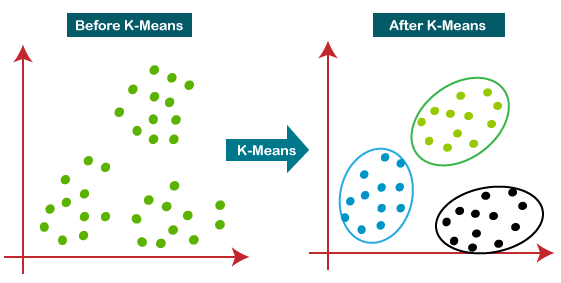
K-means clustering is one in every of the only and most common unsupervised machine learning algorithms.
Typically, unsupervised algorithms create inferences from datasets mistreatment solely input vectors while not bearing on famed, or tagged, outcomes.A cluster refers to a collection of data points aggregated together because of certain similarities.
In this we will define the value of k, where k is the number of clusters we want to retain with the dataset. So, on defining the value for k we are defining the number of clusters we want to make.
Intuition of K-Means Clustering for k=2 :
- Randomly initialize two points in the dataset called the cluster centroids.
- Cluster assignment: assign all examples into one of two groups based on which cluster centroid the example is closest to.
- Move centroid: compute the averages for all the points inside each of the two cluster centroid groups, then move the cluster centroid points to those averages.
- Re-run (2) and (3) until we have found our clusters to an optimum state.
How does it works?
- First, we have to sort out the value of k in order to get the number of clusters to our data points on the graph
- And secondly, we will assign some random points in our dataset as the centroids and these centroids are known as cluster centroids
- Then assign the points to the respective cluster to which the cluster centroid is closest, among all the cluster centroids, and let’s assign those data points to that cluster for instance
- Then comes the moving of the centroid, where the assigned points to a particular cluster are taken and then points to the respective cluster are averaged, and then that averaged coordinate is assigned as the new cluster centroid
- Then we follow up the cluster assignment and moving of centroid iteratively till we get our optimum state of clustering
- After the iterative process, we are then left with the K clusters as we desired to form.

Choosing Value of K?
Choosing K can be quite arbitrary and ambiguous.
The elbow method: plot the cost J and the number of clusters K. The cost function should reduce as we increase the number of clusters, and then flatten out. Choose K at the point where the cost function starts to flatten out.
However, fairly often, the curve is very gradual, so there’s no clear elbow
Another way to choose K is to observe how well k-means performs on a downstream purpose. In other words, you choose K that proves to be most useful for some goal you’re trying to achieve from using these clusters.
Advantages of K-Means:
- Guarantees convergence
- Easily adapts to new examples
- Generalizes to clusters of different shapes and sizes, such as elliptical clusters.
Down Sides of K-Means:
- Difficult to predict K-Value
- With global cluster, it didn’t work well
- Different initial partitions can result in different final clusters.
Summary
So, in this article we have seen the in depth of K-Means Clustering algorithm and the optimum way to find the value of K and even advantages as well as disadvantages of K-Means algorithm and as we know it is a unsupervised learning algorithm which says that it does not have any labeled dataset and it do have many use cases in this contemporary world.
Written By: Naveen Reddy
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs