
What is Gradient Descent?
Gradient descent is an optimization algorithm. It calculates the change in the output function if we change the input function. The GD can be used as an iterative approach to minimize the given function, or, in other words, it can be described as a way to find a local minimum of a function.
Gradient Descent Method can be considered as a first-order optimization algorithm. One takes a step proportional to the negative of the gradient of the function at the current point, to find a local minimum of a function.
Finding Minimum using GD

Figue1(https://cdn-images-1.medium.com/max/1600/0*fU8XFt-NCMZGAWND.)
Imagine a blindfolded man who with the fewest possible steps wants to get down a hill. Now, what strategy should he apply to do so? Here’s a solution, he will start descending the hill with big steps where the slope of the hill is steepest. Slowly and gradually, as he gets down the hills, the slope of the hill becomes less steep, here he would make his steps shorter so that he does not cross the destination.
This problem can be mathematically described using GD. We can consider the above image as a hill. Now we will start from any point X₀ on the hill. At this point, we will calculate the gradient that is nothing but the slope of the function. We will take a step in the negative direction in order to reach a new point X₁. The next step is considering this new point X₁ as X₀ and repeating the same process again and again till we reach the minimum.
This approach can be summarised as picking up a random starting point, calculating the gradient at that point, taking small steps in the negative direction that causes the function to minimize the most and, repeat this with the new starting point.
If a function has a global minimum, this approach is likely to find it but if the function has multiple local minimums, then there are chances that it will find the wrong minimum. In this case, we have to return the procedure from different starting points. If a function has no minimum, then it’s possible the procedure might go on forever
Types of Gradient Descent
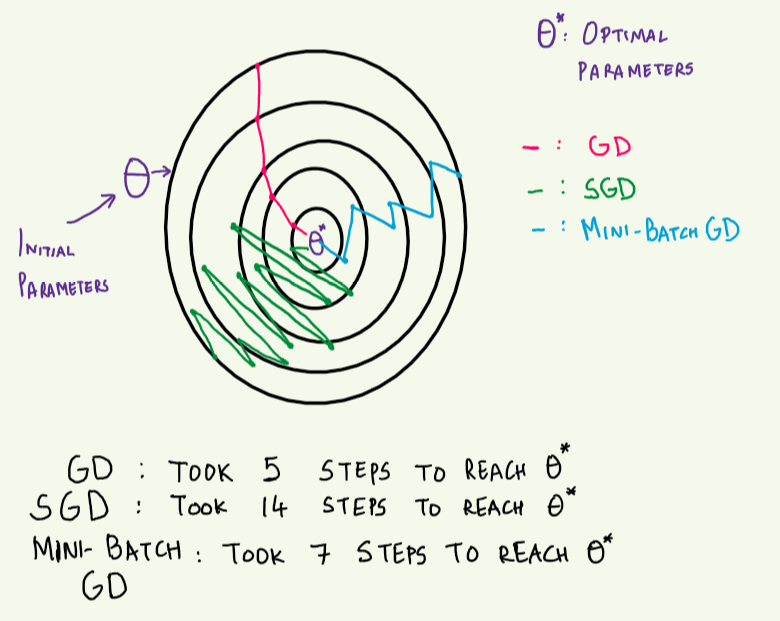
Three popular gradient Descent Based on the amount of data they use are:
- Batch Gradient Descent
- Stochastic Gradient Descent
- Mini Batch Gradient Descent

Figure2(https://miro.medium.com/max/1560/1*XbMBzok-C5Azw2632NMjog.png)
{kind=link}
Let us discuss these in detail.
1. Batch Gradient Descent
Also known as vanilla gradient descent the batch gradient descent, calculates the error within the training dataset for each example, but the model is updated only after all training examples have been evaluated. This entire process is like a cycle and called an epoch of training.
Advantages of this include being computationally efficient, producing a stable gradient of error, and a stable convergence especially for convex functions. The disadvantage of Batch Gradient Descent is that the stable gradient of error can sometimes result in a convergence state that is not the best the model can achieve. It also requires the entire training dataset to be available to the algorithm and in memory and is therefore considered to be slow for very large training datasets.
2. Stochastic Gradient Descent
Stochastic Gradient Descent(SGD), unlike batch GD, gets updated after each training example. This means it updates the parameters after considering each training example. This depending on the problem makes SGD faster and the rate of improvement is detailed based on the frequent updates. On the other hand, it gets computationally very expensive and leads to noisy gradients.
3. Mini Batch Gradient Descent
Mini Batch Gradient Descent being a combination of both Batch GD and SGD is a reliable method. We divide the training sample into small batches (generally the size of the batches are: 64, 128, 256.., but there is no hard and fast rule) and the model is updated after each batch. applications. Note that when you’re training a neural network, it’s the go-to algorithm and it’s the most common type of deep learning gradient descent.
Mini Batch GD is considered to maintain balance efficiency and robustness provided by Batch GD and SGD respectively.
The table below shows the accuracy provided and the time consumed by the three types of GD.
| Type of GD | Accuracy | Time consumption |
| Batch GD | High | High |
| Mini batch GD | Moderate | Moderate |
| SGD | Low | Low |
Using GD
We use GD to fit a parameterized model to the data. Generally, we have a parameterized model for a dataset that contains one or more parameters that best fit the model. The loss function is used to calculate how well our model fits the data.
Loss function suggests how good or bad our model parameters are, we can think of this GD to find the best model parameters that minimize the loss.
Steps for calculating GD for Linear Regression:
- initialize X₀ and X₁ with any random predefined values.
- Take a step, say α, in the direction opposite to which gradient points.
- The coordinate where we ended up being updated as new X₀.
- Repeat the step2 until convergence.
Explanation With Example


Let us consider a function x^3-4x and implement gradient descent on this. Our aim is to find a value of x on this function such that the value of the function becomes minimum.

To calculate GD, we have made 2 functions. The first function named ‘deriv’ will calculate the gradient that is nothing but the slope of the function at a particular point.
The second function will update the parameter and move in the direction opposite to the gradient to calculate the value of X that gives the minimum of the function. Here ‘l_r’ is the learning rate that decides how long a step should be. The parameters will get updated until the difference between the two steps taken becomes less than the precision.


Here we can see the updated value of the parameter for which our function gives the least value. Here the dots in the graphs show how over the iterations, the parameter has been updated by calculating the gradient and descending down the slope of the function. This took 89 iterations with a learning rate of 0.5 to reach the desired value.
A similar process is done to calculate the value of the parameter for which the loss function has the minimum value and that value gives the best fit of the model.
That is why gD is considered an important optimization algorithm that is used to predict the best fit by calculating the most relevant values of parameters for which the loss is the least.
written by: Chaitanya Virmani
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs