
What is CountVectorizer In NLP?
CountVectorizer means breaking down a sentence or any text into words by performing preprocessing tasks like converting all words to lowercase, thus removing special characters.
In NLP models can’t understand textual data they only accept numbers, so this textual data needs to be vectorized.
so, In this blog our main focus is on the count vectorizer. First, we understand the Bag Of Words Model.
Bag Of Words (BOW) Model:
Natural Language processing models only understand the numerical value. So we need to convert textual data to a numerical value.
also, The BOW is a very simple model. It converts sentences into a bag of words with no meaning. however, It converts the sentence to a fixed-length vector of numbers.
so, In this model, every word has an assigned unique number with the count of the number of occurrences of that word. then, We are focusing on the representation of the word not the order of word.
CountVectorizer:
Countvectorizer tokenization(tokenization means breaking down a sentence into words by performing preprocessing tasks like converting all words to lowercase, removing special characters, etc.
An encoding vector is thus returned with the length of the entire vocabulary(all words) and integer count for the number of times each word occurs in the sentence.
so, Here we explain the sentence.
My name is XYZ. firstly, I completed my B.E. in 2019 from Gujarat Technology University. I like playing cricket and reading books. also, I am from amreli which is located in gujrat.
So, here will be represented as follows:
Table 1
| My | name | is | XYZ. | I | completed | B.E. | in | 2019 | |
| doc | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 2 | 1 |
| from | Gujarat | Technology | University | Like | playing | cricket | and |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| reading | books | am | amreli | which | located | gujarat |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Table 2
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| doc | 2 | 1 | 2 | 1 | 3 | 1 | 2 | 1 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
The above table represents the CountVectorize sparse matrix.
Table-1 in a row represents the document and column is represent the frequency of unique words appearing in the document
so, In table 2 the index represents a number of words that appeared in a sentence. Also, represent how it is represented in practical.
Here we are using Scikit-learn CountVectorize. Also, we are showing that count vectorization works.
Firstly, we import the library. CountVectorizer is imported from sklearn feature_extraction

secondly, the next step is to initialize the object cv for using CountVectorize. Then fitting it on our sentence.

The text has been preprocessed means each word is a separate token and this is represented as a sparse matrix.
Here we check the complete vocabulary.
print(cv.vocabulary_)
{'my': 14, 'name': 15, 'is': 11, 'xyz': 21, 'completed': 5, 'in': 10, '2019': 0, 'from': 7, 'gujarat': 8, 'technology': 18, 'university': 19, 'like': 12, 'playing': 16, 'cricket': 6, 'and': 3, 'reading': 17, 'books': 4, 'am': 1, 'amreli': 2, 'which': 20, 'located': 13, 'gujrat': 9}Note: this number is not the count they are positional in the sparse vector.
Let’s here check the length and shape of our vocabulary.

There are some additional parameters in the count vector.
- Stop Words
- min_df
- Max_df
- Custom Preprocessing
- Limiting Vocabulary Size
1. Stop Word:
A stop word is a commonly used word like “the”, ”a”, etc. In NLP useless words are called “Stop Words.” That they have little useful information.
You can pass the stop word list as an argument. The stop words can be passed as a customs stop word or a predefined stop word list. Here we are using English stop words.
First, we pass a predefined list of stop words.
cv2 = CountVectorizer(sen, stop_words=’english’)
In NLP have predefined lots of stop words like ‘my’, ‘against’, ‘a’, ‘by’, ‘doing’, ‘it’, ‘how’, ‘further’, ‘was’, ‘here’, ‘then’, ‘their’, ‘while’, ‘above’, ‘both’, ‘up’, ‘to’, ‘ours’, etc
Second, we are passing a custom list of stop words that we don’t want to consider in our vocabulary. Here we are passing a custom list of stop words ‘which’, ‘my’, ‘and’. After applying the stop word remove it from the original sentence.

2. Min_df:
The min_df parameter equals a number that specifies how much importance we want to give the less frequent words in the sentence. The main aim is to ignore words that have few occurrences to be considered as meaningful information.
Here we initialize cv3 with min_df=2. We are showing lots of words are removed.

3. Max_df:
It is the opposite of min_df. And consider words based on their presence in the maximum n number of documents specified. Max_df indicates the importance you want to give to the less frequent words.
Let’s understand with an example.
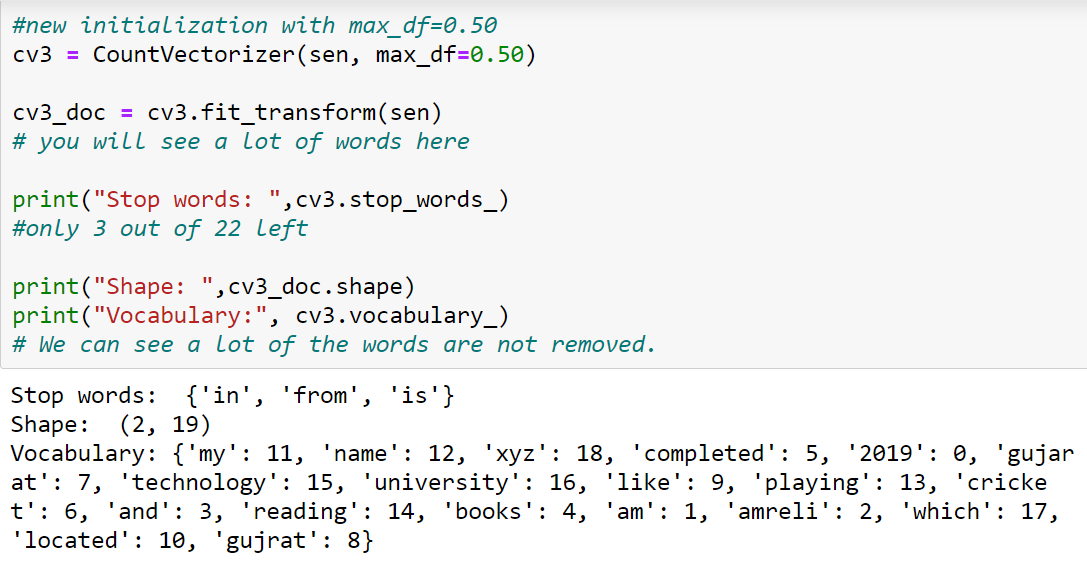
In the above example only removing 3 stop words because they are the most frequent word.
4. Custom preprocessing:
Preprocessing helps reduce noise and improve accurate analysis. Here an example of how you can do custom preprocessing with a count vectorizer.

In the above example, preprocessor_cutom is a predefined function where we performed the following step.
- convert all text into lower text.
- Remove special characters.
- Use stems of words instead of the original word using porter_stemmer.
5. Limiting Vocabulary size:
Here we can mention the maximum vocabulary(words) size using the max_feature parameter. In this example, we are going to set the vocabulary size by 15.

Conclusion:
CountVectorizer provides extract and represents features from your text data. Also, it allows you to control stop words, limit vocabulary size, min_df, max_df, etc.
Written By: Paras Bhalala
Reviewed By: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs