
What is model evaluation?
Model evaluation is a performance-based analysis of a model. Much like the report card for students, the model evaluation acts as a report card for the model. This later signifies whether our model is accurate enough for considering it in predictive or classification analysis.
Why is there a concern for evaluation Metrics?
Machine learning is a feedback form of analysis. There will always be a parameter in which the model will be lacking in. But to measure such parameters we require evaluating the model with different metrics available. We check the model, rebuild our model, check again with the metrics and this process goes on until and unless we get a satisfactory result.
We tend to be in a hurry to construct our model and make predictions based on it but we tend to forget the fact that the model so constructed, may not be a good model and if checked with different metrics might not give a satisfactory result.
Types of models Evaluation
In machine learning, we generally use two types of models comprising of
- Classification/Class output models: These models are used for prediction for different classes and give discrete values as their output. For example, predicting whether a person is having cancer or not, predicting whether India will win a match or not, are some of the few examples where we find classification coming into the account.
- Continuous/Probabilistic output models: These types of models, as the name suggests are responsible for predicting continuous values. They generally output the values that have a continuous nature. For example, predicting the housing prices in the locality, predicting the weather over a period of time are some of the examples where the probabilistic models are used.
Different evaluation metrics:
Confusion Matrix
A confusion matrix in simple terms is an NxN matrix that is used in classification problems. Here, N stands for the number of classes that the model is predicting. Let us look at how a confusion matrix actually looks like by considering a binary classification model that predicts the output based on 2 output classes namely 0 or 1.
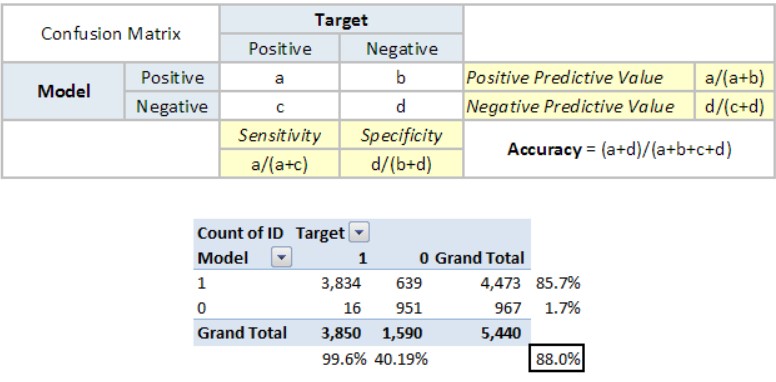
We can see that there is a 2×2 grid where there are columns and rows are representing positive and negative parameters. On the left, we have the predicted output of the model, and on the top, we have the actual output. This matrix gives a comparative study of how the actual output and the predicted output vary.
The variable ‘a’ in the matrix represents the number of values that are positive and are correctly predicted by our model. These values are called the True
Positives :
Please note here that the positive and negative in this case do not indicate the magnitude of the values rather they represent classes. Positive let’s say is for class 1 and negative refers to say, class 0.
Similarly, b represents the values that are actually negative but are predicted positively by the model. These types of values are called
False Positives :
Considering the negative row, c represents the number of values that are actually positive but are predicted negatively by the model. These values represent False Negatives. Lastly, d represents the number of values that are actually negative, and the model predicts it correctly to be negative.
Now, considering these terms let us define the metrics that we are going to use in case of the confusion matrix.
Accuracy:
The proportion of the actual number of values that are predicted correctly.
Positive Predictive Value/ Precision: The proportion of positive cases that are correctly identified.
Negative Predictive Value: The proportion of negative cases that are correctly identified.
Sensitivity/ Recall: The proportion of actual positive cases that are correctly identified.
Specificity: The proportion of actual negative cases that are correctly identified.
The accuracy as we see comes out to be 88%. One of the important advantages of the confusion matrix is that the same matrix can be used by different classes of people. For example, a pharmaceutical company is concerned with a minimal wrong positive diagnosis and hence they would want high specificity. On the other hand, an attrition model is more concerned with high sensitivity.
F1 Score
F1 score can be regarded as an extension of the confusion matrix . As we have defined the terms Precision and Recall, we will use them in calculating the F1 score. F1 score can be calculated as:
F1 = ( 2* Precision * Recall )/ Precision + Recall
Why F1 score? Well, in case we want both precision and recall to be high, we use the F1 score. As you can see, in the formula we have defined above, we are calculating the F1 score considering the harmonic mean of Precision and Recall. Now an obvious question might arise why not the arithmetic mean? Let us address this question by considering an example.
For example, in a certain model, we get the Precision to be 0 and Recall to be 1. Now, this model for all obvious reasons is considered to be useless since this model will discard any kind of input and will always output to a single class. In this case, if we consider the arithmetic mean of Precision and Recall we get a value of 0.5. Whereas, in the case of the harmonic mean, we would get a value of 0 which is desired. Another reason why we take harmonic mean into account is because it penalizes the extreme outliers.
Log loss
We used to calculate the log loss in logistic regression and used one of the optimization algorithms like gradient descent to minimize the loss and predict the outcomes. The formula goes like this:
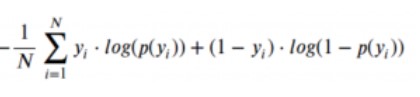
Here, p(Yi) refers to the predicted probability of a positive class. (1-p(Yi)) refers to the predicted probability of a negative class. Here, we can regard y=1 as the positive class whereas y=0 can be regarded as the negative class. Now, based on the log loss calculated, we plot a graph between log loss and precision.
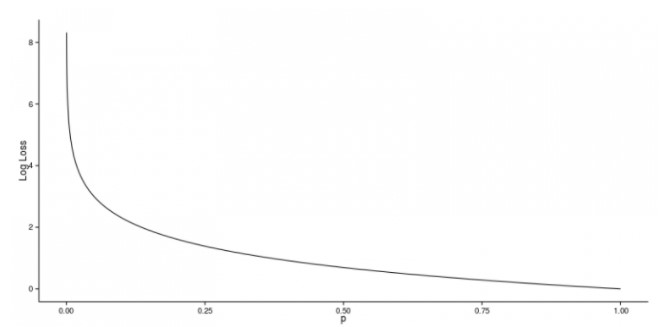
We can clearly see that as we move higher in precision our loss starts to decrease and attains saturation. The loss won’t decrease further. The lower the loss, the better is the model in predicting the output. However, there is no absolute measure of what a good loss is. Generally, loss within the range of 0 to 1 is considered ideal.
Concordant- Discordant Ratio
This is an important classification metric. Let us try to understand this by considering an example. Let us say Ram, Shayam, and Ghanshyam are three friends appearing for the semester examination. Ram, who is studious and has studied throughout the year has a 90% chance of passing the exams. Shyam who has skipped some lessons in between has about a 50% chance of passing the exams.
Ghanshyam on the other hand has about a 30% chance of passing the exams. Now, the results are out and we came to know that Shyam failed. Let us try to address this situation by concordant and discordant ratio concept.
We first make pairs of the 3 students namely RS, SG, and GR. We will next filter out those pairs which have one responder and one non-responder in them. The responder here stands for passing the exam whereas the non-responder stands for not passing the exam. Such pairs would be RS and SG. Now, we will regard the concordant pair as the one having a higher probability of passing and the discordant pair as the one which has a lower probability of passing.
RS will be regarded as the concordant pair and SG will be our discordant pair. Generally, the concordant ratio of more than 60% is considered to be good.
Root mean Square Error
Root mean square(RMS) is one of the famous evaluation metrics for continuous output. We must have used this in our intermediate classes in the subject of chemistry for calculating the degree of freedom of gas molecules. Well, in the case of machine learning as well this also holds significance. RMSE is based on the assumption that errors are not biased and follow a normal distribution.
The formula for RMSE is as follows:
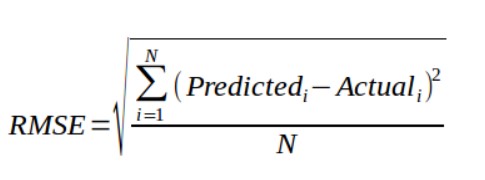
Square root in the RMSE helps the metrics to show a large number of derivations. The squared nature of the error prevents the cancellation of the terms by positive or negative values. This also avoids the use of absolute error. Now, RMSE is highly affected by outliers. These outliers must be removed before using RMSE.
As compared to the mean absolute error RMSE penalizes the larger errors more.
Conclusion
We should always give the right amount of time to model verification because we never know what new kind of data might come that would fail our model. There are many more evaluation metrics that can be considered for verification. The only thing that needs to be in mind is that some specific type of metric is suitable for a specific type of model.
Hope you had a good time learning!
Written By: Swagat Sourav
Reviewed By: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs