
DECISION TREE ALGORITHM
A Decision Tree is a flow chart like type tree structure where each internal node represents a test we perform, a comparison (e.g. left or right, heads or tales) for all ‘n’ options required. Each leaf node represents a final label. The tree’s main purpose is a classification based on parameters which take place from the root node to leaf nodes.
To understand this better, let’s take an example. You need to buy a new phone, you’ll take all important features into consideration like camera, processor, memory, price, etc. These parameters will help you bring down to certain final options out of so many. This top to bottom classification approach using a logical approach is termed as Decision Tree Classification.
Decision Tree is one of the most important non-parametric supervised learning algorithms (Input training data is already tagged with an output). We use this algorithm in mostly regression (target can be continuous values) and classification (target variable has a certain set of results) problems.
Entropy
Entropy is the measure of purity. The aim of machine implementing is to reduce the uncertainty and purer the test class, lower the disorder. It measures between 0 and 1, 0 being the purest, 1 being the most impure. Entropy can be greater than 1 at specific conditions but that would also mean the same thing, very high level of disorder or uncertainty.
Let’s take a look at the formula of Entropy
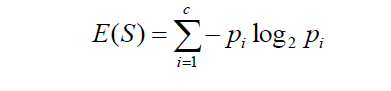
Pi represents the probability of a specific occurrence of a class. For simplicity sake let’s consider there are just 2 classes, P+and P-. We could also take these two as P and (1-P).
If P = 1/10 and (1 -P) = 9/10, so entropy will be calculated as,
Entropy = -(1/10)log2(1/10) + -(9/10)log2(9/10) ≅ 0.14
0.14 is a low level of entropy (since out of 1) so the level of impurity is less, less disorder.
Entropy is to measure the amount of disorder. In order to reduce the amount of disorder, we use Information gain.
Gini Impurity
Gini Impurity is another method of finding the impurity of or disorder of test cases. Similar to the previous method, Let’s say Pi represents the probability of a specific occurrence of a class. For simplicity sake let’s consider there are just 2 classes, P+and P-. We could also take these two as P and (1-P).
The equation for Gini Impurity will be given as:
Gini Impurity = 2P(1-P)
The above given example will be for 2 classes if multiple,
The Equation will be,
i=1nPi(1-Pi)
Note: Both Gini Impurity and Entropy are used to check disorder. Gini impurity is selected by default but it can be changed. Gini Impurity is faster but for at times, Entropy can give more precise results.
Information Gain
Information Gain is used to measuring the reduction of the disorder of the test classes when additional information is provided to it. We get to know how much information is received at each node by our implementations and the higher ones are placed at the top. There needs to be a clearer classification at the start.
Loading and Training
Here we are going to load the classifier using sklearn library and implement it on an iris dataset.

Visualizing your tree
You can use graphviz library by importing it to visualize your decision tree and can also import it as an image .png form or a pdf form.

Improving the Accuracy

The below functions are used for reducing the overfitting of the model and are called Pruning methods
min_samples_split = x : It will split at a node only if there is a minimum ‘x’ number of samples available there. Eg, if min_samples_split = 5, then a node having 4 samples won’t be allowed to split but if the number of samples >= 5, take 6, then splitting will be allowed.
min_samples_leaf = x: It can split a node ‘y’ sample into two parts so that each part is greater than ‘x ’. Eg, if min_sample_set = 3, splitting 8 into 5 and 3 is allowed but 6 and 3 are not allowed since 2<3.
max_depth = x : It restricts the max height of the tree.
max_leaf_nodes = x : Tells maximum leaf nodes allowed in that particular tree
Note: The in-depth definitions and other functions to alter the tree can be found in the official documents of sci-kit learn.
written by: Sparsh Nagpal
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs