
There are different Machine Learning Models that we can use to assess ML algorithms, classifications as well as regressions.
We need to choose ML performance metrics carefully because The way ML algorithm performance is measure and compare will depend entirely on which metrics we select.
Performance Metrics for Classification Models
We also have different types of performance metrics that can be use to evaluate predictions for classification problems.
Confusion Matrix:
The confusion matrix is a matrix thus use to evaluate the performance of the classification models for a set of test data. It can only be evaluate if the true values for test data are known.
- The matrix is divide up into two dimensions, that are actual values and predict values along with the total number of predictions.
- Actual values are the true values for the given observations, Predicted values are those values, which are predicted by the model, and
It looks like the below table:
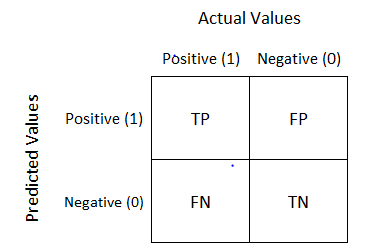
The above table has the following cases:
- True Positive(TP): The model has predicted yes, and the actual value was also true.
- True Negative(TN): Model has given prediction No, and the real or actual value was also No.
- False Positive(FP): The model has predicted Yes, but the actual value was No.
- False Negative(FN): The model has predicted no, but the actual value was Yes.
We can perform different types of calculations for the model, such as the model’s accuracy, using this matrix. These calculations are given below:
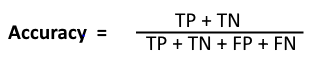
Accuracy:
however, It defines how often the model predicts the correct output. It can also calculate as the ratio of the number of correct predictions made by the classifier to all numbers of predictions made by the classifiers.
Precision:
Out of all the positive classes that have predicted correctly by the model, how many of them were true.
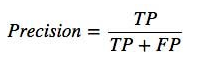
Recall:
Out of total positive classes, how our model predicted correctly. The recall value must be as high as possible.
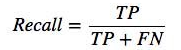
F1-Score:
however, If two models have high recall and low precision or vice versa, it is difficult to compare these models. This will help us to evaluate the recall and precision at the same time. thus, The F-score will be maximum if the recall is equal to the precision.
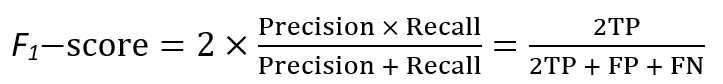
- +1describes a perfect prediction;
- 0 means unable to return any valid information (no better than random prediction);
- -1 means complete inconsistency between prediction and observation.
Let’s say you are building a model that detects whether a person has survive or not. so, After the train-test split, you got a test set of length 100, out of which 152 data points are labelled survived (1), and 266 data points are labelled not survived (0). Now let draw the matrix for your test prediction :
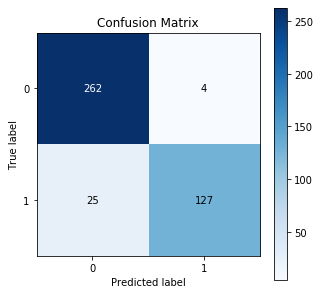
Accuracy: 93.06%
Precision: 94%
Recall: 91%
Classification Report on Machine Learning Models:
The classification report is thus the key metric in a classification problem. You’ll have accuracy, precision, recall, F1 score, and support for each class you’re trying to find.
Classification report of above confusion Matrix :

Receiver Operating Characteristic(ROC): thus, This is a graph that shows the performance of a classification model at all classification thresholds.
The ROC plot two parameters:
1. True Positive Rate (TPR): Same as recall
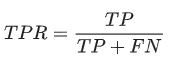
2. False Positive Rate (FPR): It is calculate as
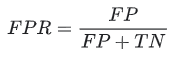
A ROC curve plots TPR vs. FPR at different classification thresholds.
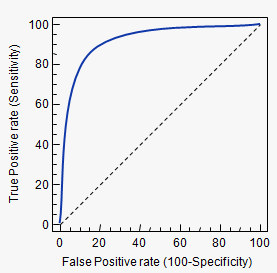
Area Under ROC curve(AUC):
AUC curve measures the entire 2-dimensional area underneath the entire ROC curve (think integral calculus) from the origin(0,0) to (1,1).
AUC curve also gives an aggregate measure of the performance across all the possible classification thresholds.

Logarithmic Loss(Log Loss):
It is also called Cross-entropy loss or Logistic regression loss. thus, It measures the accuracy of a classifier. However, It is used when a model outputs a probability for each class, rather than just the most likely class.

Performance Metrics for Regression Problems
Mean Absolute Error (MAE): It is the sum of the average of the absolute difference between the predicted and actual values.

Mean Square Error (MSE): it squares the difference between the predicted and actual values.
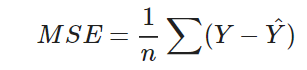
R Squared (R2):
so, R Squared metric is used for the explanatory purpose and indicates the goodness of fit of a set of predicted output values to the actual output values.
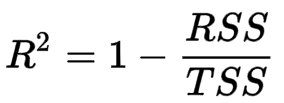
R² = coefficient of determination
RSS = sum of squares of residuals
TSS = total sum of squares
Conclusion on Machine Learning Models:
so, The estimated performance of a model tells us how well it performs with the unseen data. Predicting future data is often the main problem we want to solve.
hence, It is very important to choose a metric before understanding the context because each machine learning model tries to solve a problem with a different objective using a different dataset.
written by: Prudvi Raj
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs