
NLP stands for Natural Language Processing uses NLTK model. however, it is a subfield of AI and Linguistics that studies how machines interpret and analyze, understand and manipulate Human Language. The main Goal of NLP is to build an interaction system that can understand given input and perform tasks.
varying from chatbots, detect Spam mails, Autocorrect, language classification, Translation, Identifying toxic comments and other AI applications where robots react to human commands.
We have a few platforms which can use to develop models; we will be talking about Natural Language Toolkit.
NLTK
Natural Language Toolkit or NLTK is a suite of libraries and programs for symbolic and statistical NLP. thus, We can download NLTK from NLTK official website and then import it to your working environment.
Sudo Pip3 install nltk
Import nltk is a function use to import NLTK libraries.
NLTK.download; downloads and installs all the features and libraries of nltk.
Tokenizing words and sentences
Tokenizing is the splitting of sentences or words into individual components.
Let’s look at different functions used to Tokenize.
Tokenize Words.
Word_tokenize() function is use in order to split sentences or groups of words into individual components.
Below we import word and sentence tokenizer from NLTK library and give a sentence to it.

Output:

Sent_tokenize() is in use to split paragraphs or groups of sentences into individual components.
Input is thus a combination of sentences with 2 separate sentences separate using “.”

Output:
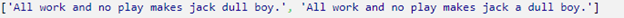
The output is 2 individual sentences.
NLTK stopwords
Stop words are basic grammar or commonly used words which we use in sentence formation ex: the, is, an.
Generally, when we use search bars like GOOGLE and BING, Stop words are removed from the sentence and only keywords are used to search and identify the context you are looking for in the database.
Stopwords.words(); is the function used to identify and remove words from the sentence. thus, The function Stopwords contains a list of all stopwords (commonly used words).
The above function can then be import. corpus which is another nltk library function.
Below is a function where all the stopwords are filtered in a paragraph.

In the above code we import stopwords from nltk.corpus.
They store a sentence in data, after which we call the function stopwords. words and specify which language we are using. As the sentence is in English we set the parameter as English.
We then tokenize the sentence into individual words.
We make a double loop. then, First loop to send all the words, second loop to identify whether all the words we have in our sentence is the stopwords list.
If there is a match between the words available in the sentence and list, then those words are stored in wordsfiltered list.
conclusion
We can follow the above logic and do multiple data manipulations on the above field, Such as deleting those variables, identifying the most common word used.
therefore, We can print those values available in words filtered List, using print function.
written by: tarun Kumar
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs