
It is just been a few days after a long quarantine due to the global pandemic. It is so obvious that we’re tedious. Movies were one thing that kept us alive, isn’t it? But didn’t you wonder How do you think Netflix always knows the movie we prefer? How does flipkart,Myntra and Amazon always know what would you want to buy? This is very simple, all of them use recommendation systems for this. Now a question pops out in our mind,What is a recommender system?
Recommender Systems are simple to complex algorithms aim at suggesting relevant items to users may it be the movies to watch, text to read, products to buy, or anything else depending on the industries. Companies generate huge amount of profits by giving a personalized experience to their customers. Lets look into the overview of a recommender system. The two major systems we review : content-based, collaborative filtering.
Content-based filtering:
The users profiles are construct by using historical interactions or by explicitly asking users about their interests. These systems then make recommendations using the user’s profile features and the item’s attribute similarity.
This model is quite effective when applied, in almost all the situations, however it does posses some drawbacks.
- New users will always lack a well defined profile unless they are explicitly ask to provide their information.
- It needs the side information (attributes) for every item.
- Some characteristics of items/users may not be easy to capture or describe explicitly.
- New users or items with previously unseen features (like a new genre) will suffer (1)
- It makes obvious recommendations because of its excessive specialization (user A has previously shown interest only in categories B, C, and D, then the system wouldn’t recommend items outside those categories. even though it could be interesting to them).
Collaborative filtering:
The interactions between the users and the items are store in the “user-item interactions matrix”. The main idea, then, is that this “user-item interactions matrix” is sufficient enough to infer features and make predictions based on them.
Collaborative filtering model, makes up for almost all the drawbacks of content based filtering, however it has its faults too [4]:
- Cold Start Problem:It needs to have enough information on user-item interactions for any of its system to work.
- Data Sparsity: If it is a new user or item, the model will not have any prior information about them since they don’t have existing interactions.
- Many users or items have far too few interactions to be efficiently handled.
Content based methods suffer far less from these faults when compared to a collaborative model(1). However there are ways to overcome the faults found in collaborative filtering.
Now let us move on to the maths behind the working of a recommender system.
SVD (Singular Value Decomposition):
SVD is a matrix factorization technique that is usually used to reduce the number of features of a data set by reducing space dimensions from N to K where K < N.In cases of large datasets, when our approximation typically will not be as accurate, due to the high processing power required in case of such high dimensionality.
though SVD reduces the dimensionality to a more manageable number.On getting rid of the excess data, SVD succeeds in representing the matrix as a series of linear approximations that expose the underlying meaning-structure. After getting the matrix that can loosely describe the underlying relationship between the users and the items. we can effectively predict how in-demand a particular item may be, if introduced to the market, using the relationship we found.
This above technique is ‘Model-based Approach’ in SVD.
Basically, Model-based techniques try to further fill out this matrix. They tackle the task of guessing how much a user will like an item that they did not encounter before. For that they utilize several machine learning algorithms to train on the vector of items for a specific user, then they can build a model that can predict the user’s rating for a new item that has just been added to the system.
Such a model is closely related to singular value decomposition (SVD), a well-established matrix factorisation technique for identifying latent semantics [5].
The matrix factorization is done on the “user-item iterations matrix”.
The “user-item interactions matrix” has a matrix structure where each row represents a user, and each column represents an item. The elements of this matrix are the ratings that are given to items by users. Using SVD, the initial matrix A with m rows, n columns and rank r can be decomposed into the product of three matrices.
Amxn = UmxmSmxmVTnxn

where U and V are orthogonal matrices where the first r columns are orthonormal eigenvectors chosen from AAᵀ and AᵀA respectively. S is a diagonal matrix with r singular elements equal to the root of the positive eigenvalues of AAᵀ or Aᵀ A.
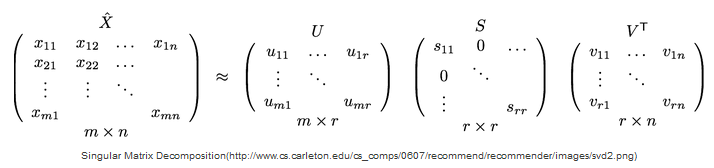
Practically speaking, U is a m x n orthogonal left singular matrix, which represents the relationship between users and latent factors, S is a m x n diagonal matrix, which describes the strength of each latent factor and V is a n x n diagonal right singular matrix, which indicates the similarity between the items and the latent factor (5). Latent factors are a broad idea which describes a property or concept that a user or an item has. It can be the characteristics of the items, for example, the genre of the movie.
The SVD decreases the dimension of the “user-item interactions matrix” by extracting its latent factors.
It maps each user and each item into a r-dimensional latent space. This mapping facilitates a clear representation of relationships between users and items and also helps with data sparsity issues.
Intuitively speaking, SVD tries to capture the relationship between the different movies/users by finding a set of movies/users whose linear combinations can be used to represent all kinds of movies/users .
Now, we get to the key: factoring the matrix via SVD provides a useful way to represent the process of people rating movies (6). By changing the basis of one or both vector spaces involved, we isolate the different (orthogonal) characteristics of the process (U and V).
using SVD, factorization would result in the following:
- Come up with a special list of vectors u1,u2,…us so that every user can be written as a linear combination of the Us
- Do the analogous thing for movies, v1,v2,…vs to get Vs
- Do (1) and (2) in such a way that the map S is diagonal with respect to both new bases simultaneously.
For the sake of simplicity, we will forget about the matrix S as it is a diagonal matrix, it simply acts as a scaler on U and VT [1],(7).
Hence, we will pretend that we have merged the three matrices into two matrices. Now, our matrix factorization simply becomes:
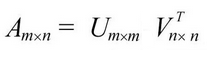
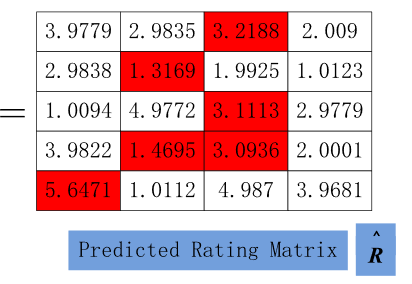
Now in context of the movie example, A would be the user-item interactions matrix, which is fill with ratings. (Rating Matrix or R).
Now the dot product of U (user feature matrix, Q) and V (movie feature matrix, P), would give the predicted user-item interactions matrix, ie. the predicted ratings matrix Now, lets evaluate how accurate our predictions are:
Recommender System accuracy is popularly evaluate through two main measures: Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) (8). They’re both on the same scale as the original ratings. However, one may be better to use, depending on the context of the data set.

One large characteristic of Mean Average Error (MAE) it weighs the outliers or large error terms, equally to the other predictions. Therefore, MAE should be prefer when looking when you’re not really looking toward the importance of outliers.
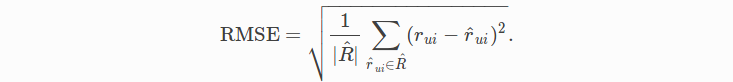
One tendency of Root Mean Square Error is that it tends to be more prone to being affect by outliers or bad predictions. For predicting the ‘rating matrix’ we are not Perturb by large outliers, therefore MAE is the better choice.
In context of our ‘movie’ example,
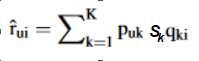
where řui is the predicted rating for a user, u and movie, i
- Puk is a row from the U matrix (pertaining to the relation between the users and the latent factors)
- qki is a column from the V matrix (pertaining to the similarity between the movies and the latent factors).
- Sk determines how strong the influence of k latent factor is.
Since we do not know the rating for some of the movies, we will temporarily ignore them. Namely, we are only minimizing MAE on the known entries in the “user-matrix interactions matrix”(9).
Now, let’s optimise the model.
Error Minimisation:
Machine learning uses derivatives in optimization problems to minimise the error (10). Optimization algorithms like gradient descent use derivatives to actually decide whether to increase or decrease S (i.e the influence of each latent factor) .
The intuitive behind this is simple, a derivative is a term that comes from calculus and is calculate upon the slope of the graph at a particular point. The slope is calculate by drawing a tangent line to the graph at the point. So, if we are able to compute this tangent line, we might be able to compute the desired direction to reach the minima.
Minimizing with Gradient Descent (GD):
The MAE equation is minimize using stochastic gradient descent algorithm. From a high level perspective GD starts by giving the parameters of the equation we are trying to minimize initial values and then iterating to reduce the error between the predicted and the actual value each time correcting the previous value by a small factor [B,14.1],(4).

In this report we use Gradient Descent to optimise the results and lower the MAE, but it is not necessarily the best algorithm. One problem with gradient descent is that it is slow.
Stochastic gradient Descent (SGD):
An alternative to GD is, SGD. To improve the training time, instead of going through all the points to find the MAE, and then updating the S matrix, we go through one pair of values (i.e one row in the V(user) vector and one column in the movie vector) and calculate the error for that prediction and change the S as per that one prediction immediately. This decreases the training time of the model exponentially.

Recommender systems mostly help us retrieve personalized information on the Internet. It can help us deal with the problem of information overload which is a very common phenomenon with information retrieval systems and thus enables users to have access to products and services which are not always available to its users.
written by: Shrushti Hegde
reviewed by: Shivani Yadav
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs