
What is Dimensionality reduction?
As the name suggests, dimensionality reduction is reducing higher dimensions to a lower number of dimensions. But, what are these dimensions that we are talking about? Well, to say it in a simple and elegant manner.
dimensions are nothing but the number of features that we are considering in our machine learning model. The features are the input parameters on which the output values are define.
In Machine Learning, we deal with a lot of data that consists of a number of parameters. It becomes a hard task for a programmer to deal with a large number of features and their impact on the output. It becomes a tedious task to keep track of the changes in all these features together. Thus, a need for a reduction in the number of features arises.
The analogy of how dimensionality reduction helps
Let us take an example to understand the need for dimensionality reduction using an example. We all have studied in colleges or are currently undergoing our college. Now, we all have been section it into different branches and accordingly our classes are allocate upon. You might be remembering that in the first year a person among your class is appoint to be as the class representative.
Now, pause for a second and try to give it a thought that what all activities the class representative performs. To name a few, their work may be scheduling the classes by contacting the professors, giving you an alert signal for the completion of assignments(nobody wants to reminded of that!).
though most importantly they are answerable to the whole class in front of the professors or any higher authority.
So, the idea we use in dimensionality reduction that some of the features that we select from a large dataset are answerable to the whole dataset. These features are carefully take by observing the various types of dependencies (which we will see later in this blog) among the features.
You might have a question jumping in your mind. Having said that we are reducing the number of features in the dataset but in any way can this affect the accuracy and efficiency of our machine learning model?
Well, if in case you thought like that, you need not worry. because as we move along this blog we will address this question.
benefits using PCA
Continuing with our example, we can very well imagine what the role of a class representative is. Had there been no class representative then this would have made it very difficult for the professors.
Instead, now the professor can focus only on the class representative. he or she is only responsible for sharing the details with the class. The representative becomes responsible for sharing the information with his or her fellow classmates.
Keeping this analogy intact thinking about our case of dimensionality reduction, this would help for a reduction in the computational power of the system. Less number of features means less amount of burden to worry about and the chances of error get significantly reduced.
Besides that, a lesser number of features makes it easier for the model to train and display the output in less amount of time. We had mentioned that we will be reducing the number of features without compromising the amount of data.
This is where the Principal Component Analysis(PCA) helps. The higher number of features are converted into a set of reduced features that are capable. We will see later how to implement it.
The role of Principal Component Analysis
Let us again extend our example in the previous sections. Let us say that your semesters are approaching. and it has made you think a lot since you have not studied enough throughout the year(which I suppose no one does!).
you want to develop a routine for yourself specifying how much labor is in demand for each of the subjects to get good marks. Your sample dataset may look like this:

This table specifies how the difficulty level of the subject, how the difficulty level of the questions, how the pass marks. how the amount of syllabus gets complete determines how much amount of hours is in demand for its completion?
The point to be Illustrious here is that not all the factors that you have taken into consideration determine your labor rather. when you look closely you will see that the passing marks of the subjects .
and the syllabus complete upon are independent of the effort you want to invest in that subject.
So our best choices would be selecting the remaining features as the prime ones and the rest are secondary ones by determining their covariances and their loss percentages. If you understood what I just said then congratulations! You just understood how the PCA performs.
Mathematical Aspects of PCA
Let us say that we have 5 features and we want to map into the reduced set of 2 features namely feature-1 and feature-2. Let’s try to plot these 2 features:
Here we have plotted feature-2 against feature-1 and we can see that the straight line is a very good approximation. So the variances will be low in this case since the line passes close to the given points.

Let us try to reverse the scenario and plot feature-1 vs feature-2

You can clearly see in this plot that points and the straight line are wide apart and hence they will be having higher variances. These variances will determine the loss in the model. The models having lower variances will generally give lower loss and that is desired. So in this case the feature-2 vs feature-1 will get select.
This idea can be extended to all those 5 features by calculating pairwise co-variances which will give us a covariance matrix. Next, the Eigenvector is calculated which consists of the data point and the number of columns in that matrix will be equal to the number of features we wish to consider. They will be arranging according to the minimum loss coming prior to the maximum loss. Dependency among the features is calculated and if it turns out to be high as compared to others then that feature is selected.
Implementation of PCA in Python
Here we will be using The breast cancer dataset for our implementation of PCA. The dataset consists of several features that say about the tumor and this helps in the prediction of cancer that is either malignant or benign. We will be importing the dataset and separating the features and labels from it. The X variable consists of all the features and the Y variable consists of all the labels.
Since the data is present in the form of a dictionary so we can extract the data by using the keys.

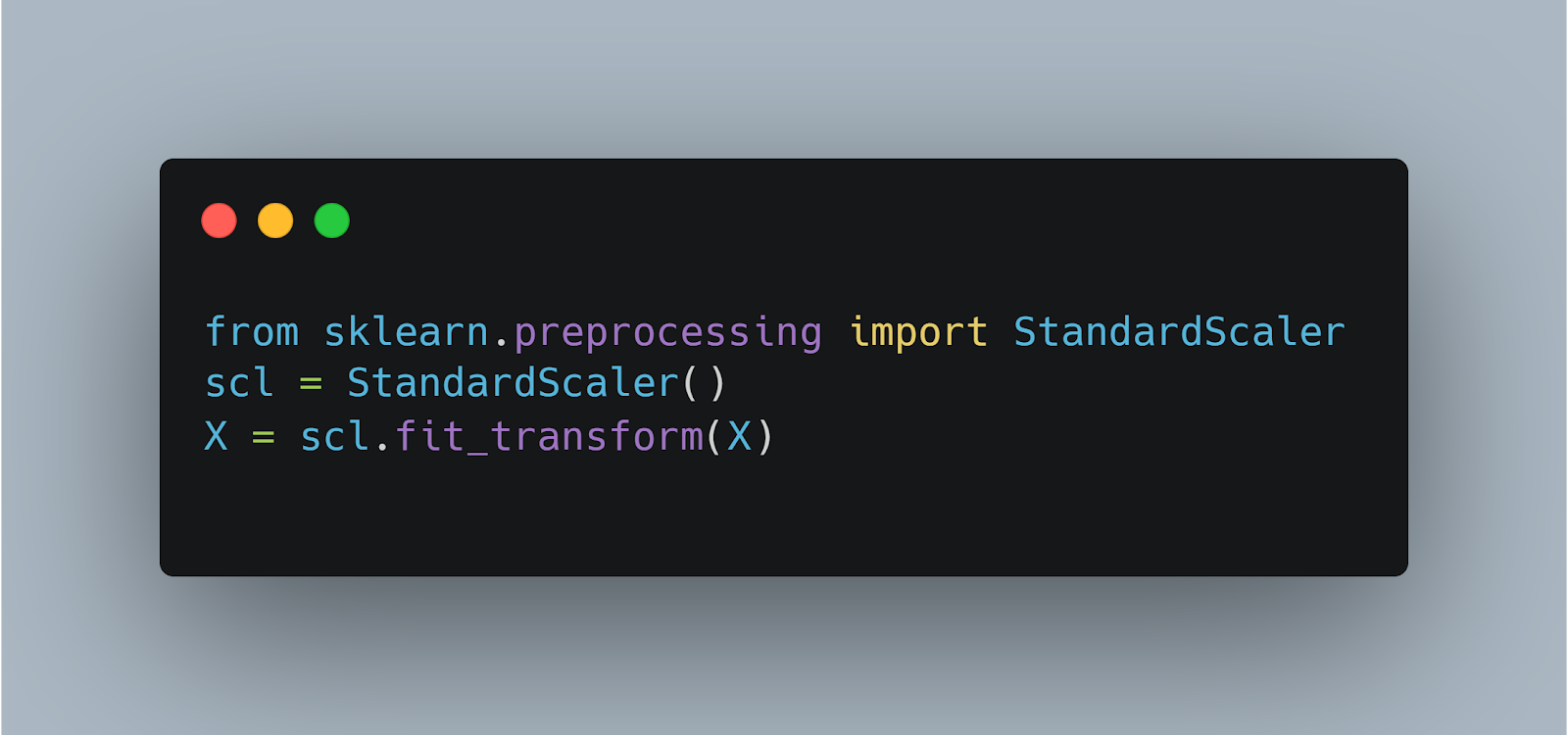
Next, we will be normalizing the data. Normalization refers to the scaling done on the data. Since the dataset consists of wide ranges of data, it is a necessary responsibility of the programmer to bring all the data available to the same scale. This helps in better training performance of the model and helps in reducing the error of the outcomes. We will be using the StandardScaler function for normalizing our data.
Next, we will be implementing the PCA by importing the required library and selecting the 3 best features for our dataset. The n_componets argument takes the number of features after reduction. After transforming the dataset into 3 features we get an Eigenvector of 3 columns whose 1st column consists of the feature with the least loss followed by the next least loss and so on. Since we can plot only in 2 dimensions so we will be looking at the combinations of these 3 features in a pairwise manner by plotting and observing them.

This code will generate 3 plots, let’s see them one by one.
Plot 1( Feature1 in x and Feature2 in y)

Here we can see that both the features are easily separable. Malignant and benign cancer are clearly distinguishable. So this combination is worth consideration.
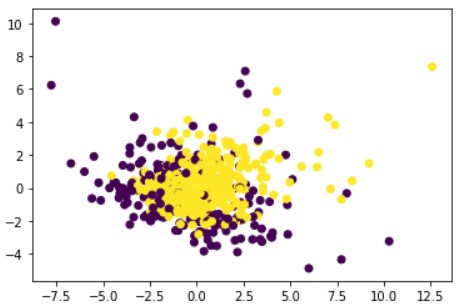
Plot 2( Feature2 in x and Feature3 in y)
Here this can be clearly observed that the two types of data points are inseparable. They tend to mix with each other which makes it difficult for their separation. So this combination won’t be selected.
Plot 3( Feature1 in x and Feature3 in y)
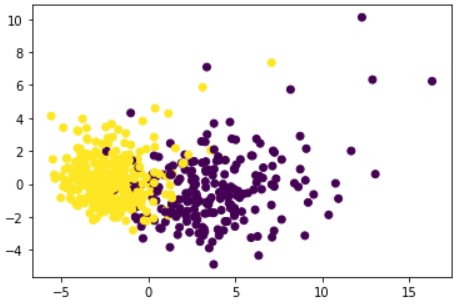
This is much similar to the 1st case where the 2 types of data points are separable easily. So this too can be considered as a combination.
Finding the optimal number of features
Here we will be calculating how many features will give us the highest accuracy and therefore minimum loss. We will be taking into consideration the training accuracy and testing accuracy. We will be plotting them against the number of features. The point where the difference between the training accuracy and the testing accuracy is minimum will be taken into consideration and that number of features will give us the optimal output.
However, even though the minimum difference appears at a higher number of features, selecting a higher number of features will be computationally expensive. Thus, a trade-off will be considered and decided accordingly.

Here the blue curve represents the training accuracy whereas the red curve represents the testing accuracy. We can see that by using the K-Neighbors Classification algorithm we got the optimal number of features to be 2 since at 2 the difference of training and the testing accuracy is minimal. Different classification algorithms will give different numbers of optimal features but the approach in each of the cases will be the same.

Conclusion
PCA is one of the most standard technique that is being used for dimensionality reduction. It is a simple and easy to use method. The PCA helps in selecting the best features out of all the features available thereby reducing the strain on the model to give prediction based on so many features. We also saw how we got the optimal number of features from all the features available. This becomes necessary since it would be manually tedious for us to check all the combinations.
All in all, this was a quick implementation of how PCA works. If you want to dive into the mathematics of all these things that I talked about, you are most welcome to do so! Learning those will be different fun altogether.
Hope you had a wonderful time learning something new!
Written By: Swagat Sourav
Reviewed By: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs