
Support Vector Machines (SVM) is a supervised learning algorithm capable of solving both classification and regression problems, Although it is mostly used for classification problems.
SVM are famous due to their way of handling multiple categorical and continuous data.
SVM’s main goal is to separate classes according to their classification by finding a hyperplane, but for this, we need to plot each data point in a higher-dimensional space.
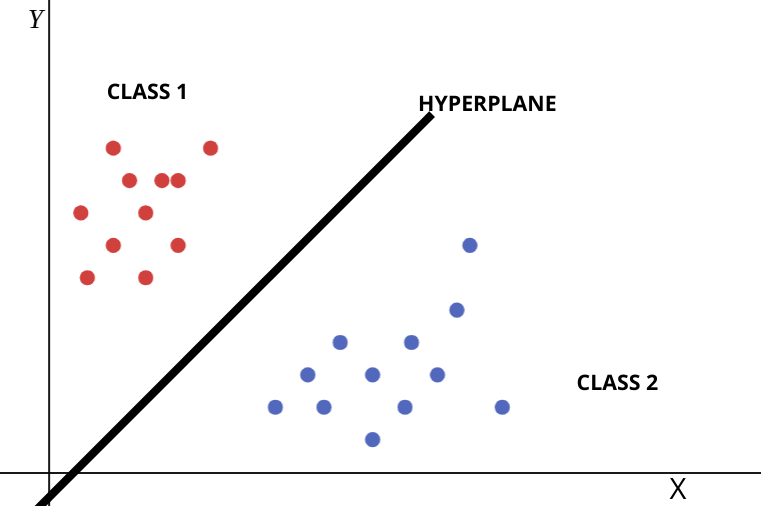
As we can see from the image above the Hyperplane segregates the two classes, this is the objective of the SVM.
Optimal hyperplanes can separate the classes so that we can easily identify to which class or the category the new data point or label belongs to.
But why does SVM need to find the optimal hyperplane?
The answer is simple because optimal hyperplane
- Correctly classifies the training dataset
- Produce accurate results for unseen data (for test dataset).
Before moving on ahead, there are several terms regarding hyperplane which are As described :
- Support vectors
These are the vector points which are closest to the hyperplane. Support vectors are important in finding the optimal hyperplane and removing them will shift the position of the hyperplane. Moreover, these vectors support the hyperplane thus named as support vectors.
- Margin
Margin is the distance of hyperplane from the support vectors
. SVM chooses the hyperplane which has highest the margin
Among all other hyperplanes.
- Accuracy
SVM not only chooses the optimal hyperplane based on Margin but it also considers the accuracy of the hyperplane, which is how many data points it classifies correctly.
The most important point to remember is that SVM chooses that hyperplane which has more accuracy rather than the hyperplane which has a larger margin.
Moreover, SVM can also ignore outliers and prioritize maximizing
the margin rather than including outliers.
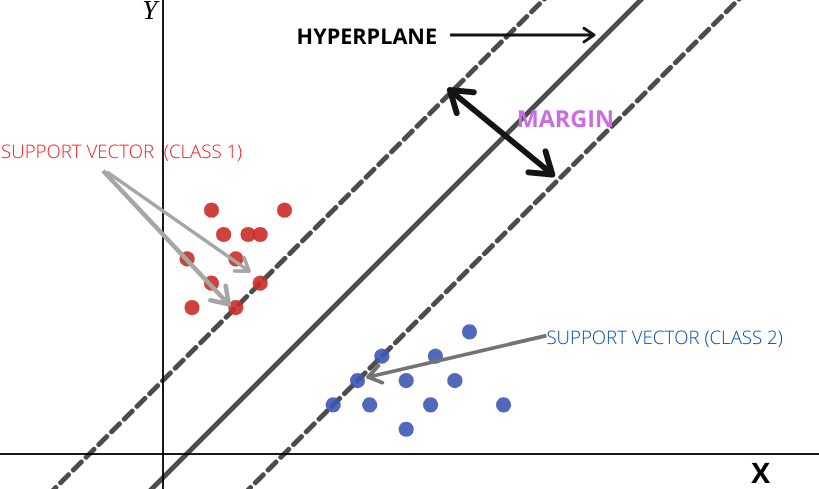
In short, we can say that the optimal hyperplane has the largest margin.
And the goal of SVM is to find such a hyperplane.
But in most cases, the data is not linearly separable which means there exist some data points which are overlapping, which makes it hard to classify. SVM solves these kinds of problems by introducing soft margin and kernel tricks.
SOFT MARGIN
In Soft margin we allow some margin violation to occur to find the optimal hyperplane. This type of classifier is known as Soft Margin Classifier.
Margin violation refers to not considering some data points, which means it tolerates a few misclassified points for choosing optimal hyperplane.
Now the question arises why it allows misclassification?
It allows misclassification to find the hyperplane which has maximum accuracy and margin, in other words, which allows the least misclassification of data.
It also helps in preventing overfitting of the model.
KERNEL TRICK
It is the most interesting feature of SVM which makes it so popular.
The SVM kernel takes low dimensional input space and transforms it into the higher dimensional space.
In short, we can say that it reduces problems from non-separable to separable problems.
Kernel
The kernel is a function that takes input vectors in original space and returns the dot product of vectors in feature space.
But what is Kernel Trick?
In real life SVM Kernel never actually plots lower-dimensional space into
Higher-dimensional space as this process is very time and space consuming.
Kernel trick utilizes existing features and perform extremely complex data transformations and creates new features and use those features to find the
Optimal hyperplane.
There are many types of kernel functions like
- Linear
- Radial Basis Function (RBF)
- Polynomial
- Sigmoid tanh
Frequently used kernel functions are Radial Basis Function(RBF) and polynomial functions.
Consider the following example where data points are dosage of drugs taken by patients and their effect on patient
Here red refers to patients that were not cured
Green refers to patients that were cured .
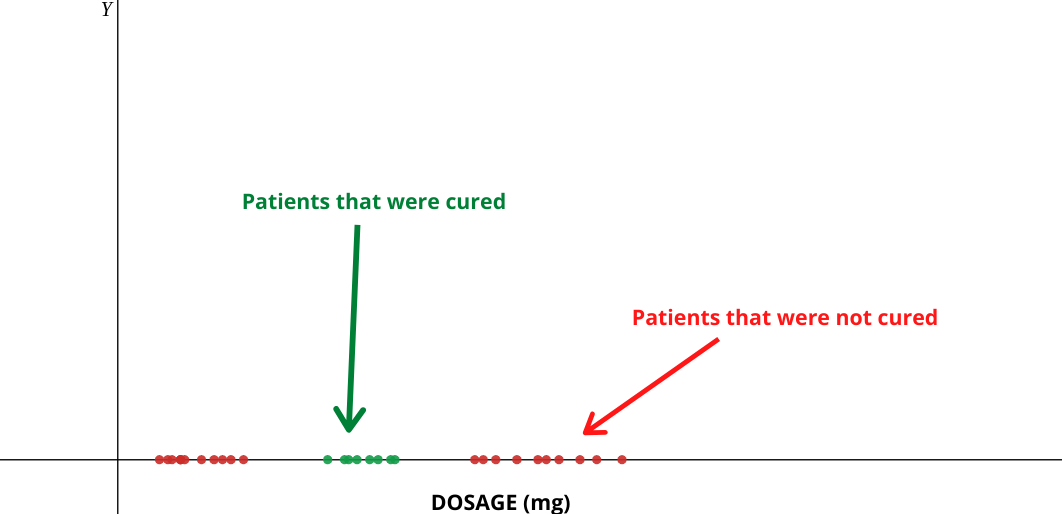
As you can see that we can’t draw any hyperplane which completely classifies both the classes so what does the SVM kernel do?
SVM kernel adds a new axis (Y) and plots DOSAGE 2 and then we can easily draw the hyperplane.

In the above example after plotting dosage^2 on the y-axis we can clearly see that a hyperplane exists and is optimal.
This way the SVM kernel works it finds the optimal hyperplane by transforming low-dimensional input into high-dimensional space.
An important point to remember is that Kernel functions only to calculate the relationship between every pair of points as if they are in higher dimensions, they don’t actually do the transformation.
IMPLEMENTATION OF SVM IN PYTHON
SVM is implemented in python with the help of scikit-learn (sklearn) library
which is quite popular for machine learning algorithms.
Problem
In this problem, we have to predict whether the cancer is malignant (meaning it can grow and spread to other parts of the body) or benign (meaning that it does not spread to various parts of the body).
We are given the Cancer Cells Dataset which contains various features computed for each cell nucleus and a predicted variable whether the cancer cell is malignant or benign.
Let us first import the necessary python packages.

Now we will import the dataset and try to get some necessary information from that.

Output
Here Class is output variable and refers to

2 : Benign
4 : Malignant
Now we will visualize our dataset
Output:-
Now we will do data scaling and model training.
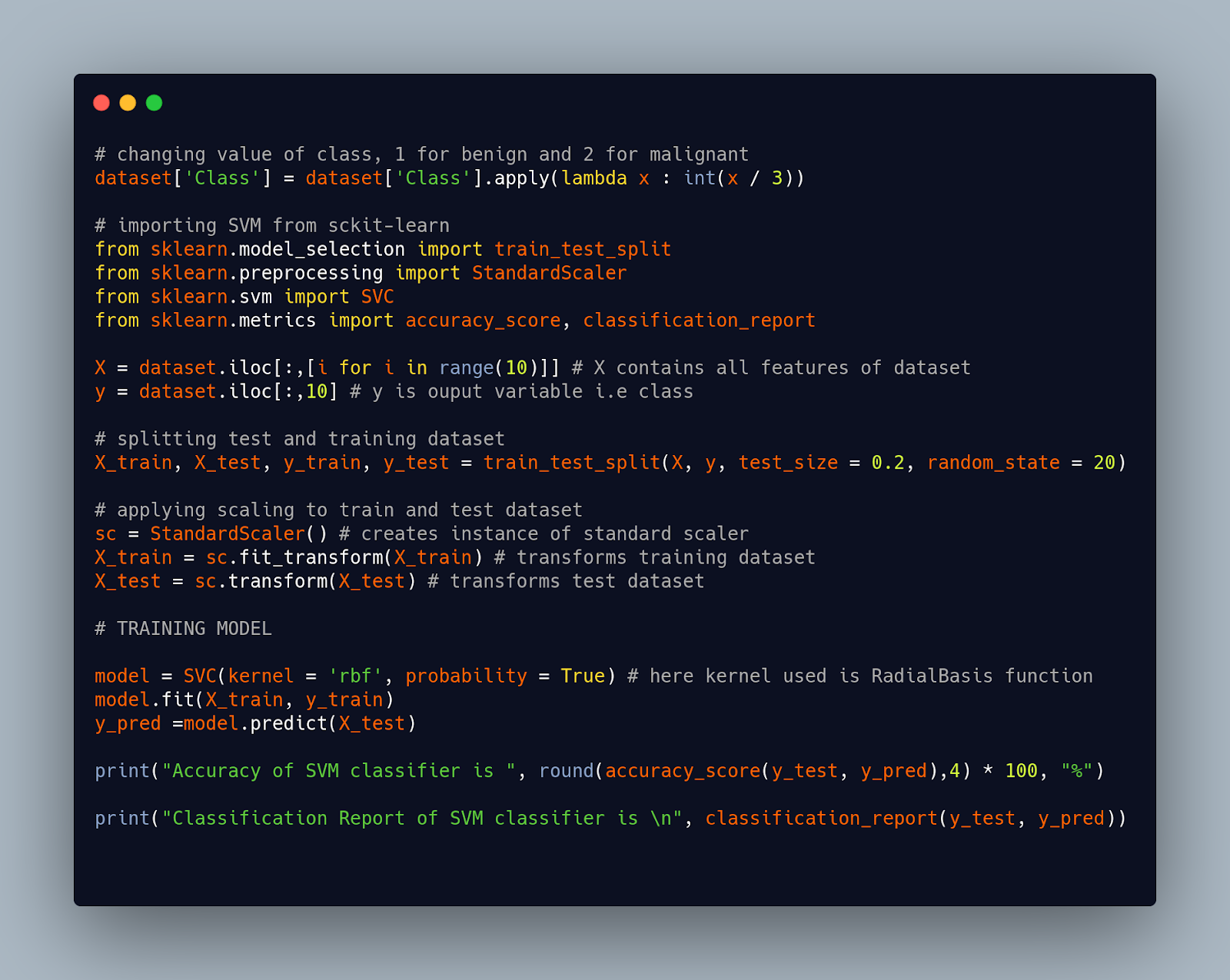
Output:-
Accuracy of SVM classifier is 94.89 %

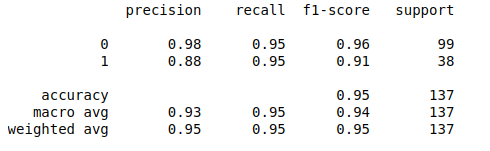
We got 94.89 % accuracy and 95% recall which is quite good for our model.
Finally, we will plot a roc curve for our SVM classifier

Output:-

Advantages of SVM
- SVM produces better accuracy and is faster as compared to the Naive Bayes Classifier.
- It works well in the case of outliers and higher-dimensional space.
- SVM is also memory efficient as they use a subset of training dataset during their training phase
- offers Penalty parameter and kernel coefficient for tuning of the model and prevents overfitting and underfitting.
Disadvantages of SVM
- In SVM it is hard to choose a good kernel function.
- SVM has a high training time for large datasets.
- in SVM, thus it doesn’t work well in case of overlapping classes or where noise is present in the dataset.
- SVM is sensitive to the type of kernel function used during training.
Applications of SVM
- Text and Hypertext categorization.
- Handwriting Recognition.
- Bioinformatics.
- Image classification.
- Protein structure prediction.
Conclusion
In this tutorial, we learned about Support Vector Machines, its objective,
working, kernel functions, kernel trick, model building, and evaluating its performance on Cancer Cells Dataset using Scikit-Learn library in python.
We also discussed its advantages, disadvantages, and applications.
written by: Mohit Kumar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs