
According to Wikipedia Violence is described as “the use of physical force so as to injure, abuse, damage, or destroy”. In public places, violent behaviors are potential and a serious threat to personal security, social stability, unreliability, uncertainty in day to day life. The goal of violence detection using mL is to automatically and effectively determine whether the violence occurs or not, in real-time.
On average 770 million surveillance cameras are install all over the world. Most of these cameras still require human supervision in order to detect any mishap or other types of adversities. Recording all the videos 24×7 and supervision by a human is practically not possible. Recent advances in Computer Vision(CV) can enable us to transcend the limitations of physical human constraints.
Violence Detection Using ML
The definition of violence for modeling and training can be drastically different. Violent scenes can be defined as “scenes one would not let an 8-year-old child see because they contain physical violence”. These subjective features which can represent violence which needs to be address while modeling/ designing the system can be the Presence of blood, Fights, Presence of fire, the Presence of firearms (guns and assimilated), Presence of cold arms, Gory scenes, Explosions, Screams, Gunshots, etc.
Procedure and methods:
For a video clip without any moving object, it is easy to judge that there is no violent behavior. However, when the videos are not captured by a static camera and the background is continuously moving, it is difficult to extract the objects using background subtraction since the moving background can hardly be modeled.
In the making of a model Convolution neural network and classifiers such as Support vector machine or LSTM(Long short term memory cell) are combine to get the desire results. The mainstream techniques use low-level features for this task, recognizing complex patterns, processing a massive number of frames.
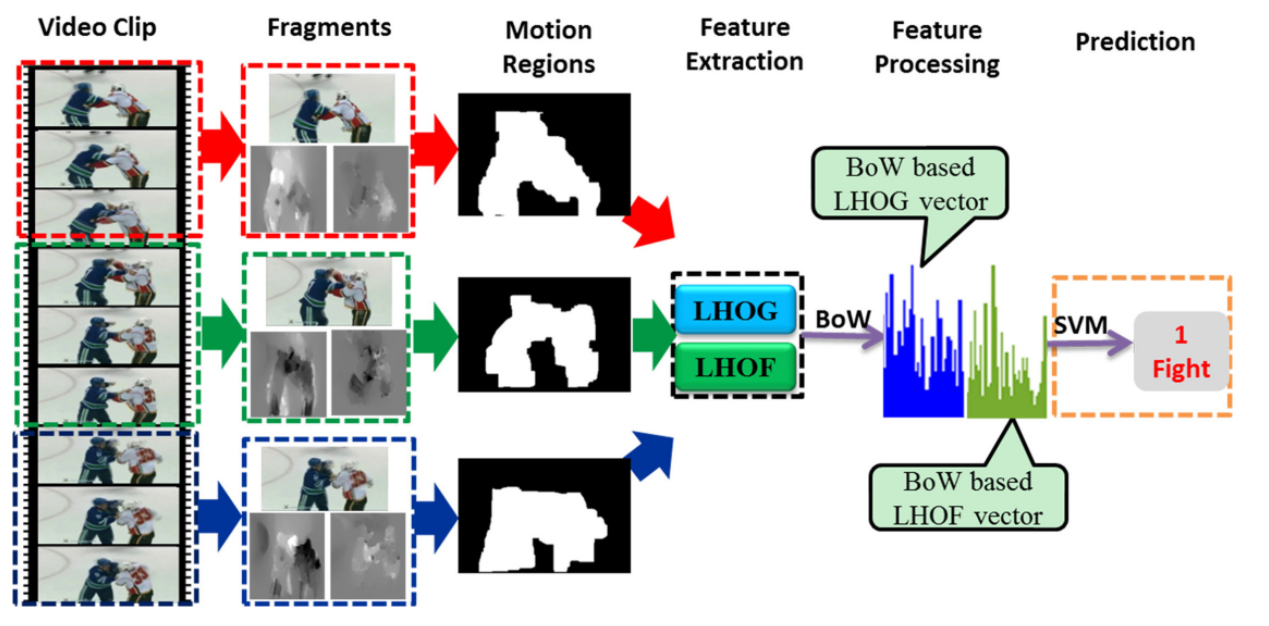
https://journals.plos.org/plosone/article/figure?id=10.1371/journal.pone.0203668.g001
Methods combining Long short-term memory (LSTM) is an artificial recurrent neural network architecture which uses in the field of deep learning. thus, along with Convolution Neural Network which can takes an input image, and assign importance/relevance (weights and biases) to various aspects/parameters in the image and is thus able to differentiate one object from the other.
Step 1:
The first step is to use CNN. The output from each convolutional layer after passing through the “relu” activation function is to extract the features. The function returns zero if it receives any negative input, and for any positive value, it returns that positive value back. Hence it can be written as f(x)=max(0,x).
The main advantage of using the ReLU over other functions is that it does not activate all the neurons which are associated with weights at the same time. Due to this reason, during the backpropagation process, not all weights and biases changes altogether.
Step 2
The Long Short-Term Memory cells are an RNN type of network which are generally use to recall and reconsider a section of previously trained parameters. Generally, a network would put more weight or relevance on the latest inputs and gradually forgets the older learnings over time. This can pose issues in some use cases such as violence detection using mL. Luckily LSTM helps in solving this issue which is RNNs (recurrent neural networks).
that generally continue using past information, to help increase the performance of its model. LSTM does a bunch of mathematical operations so as to have a better memory. LSTM does the activity of the human brain to remember the previously trained event. It passes through a sigmoid function The value zero indicates a forgot state and one denotes a state which is remember by.
LSTM has four gates:
- “Forget” gate is used to dump out all the unnecessary long term information.
- “Remember” gate takes the information from the forget gate and combines it with the information from the learn gate.
- “Learn” gate combines existing Short-term memory with some input.
- “Use” gate utilizes combining information from Forget and Remember gate.

https://link.springer.com/article/10.1007/s42979-020-00207-x/figures/4
Conclusion
This combination of algorithms is one of the approaches to violence detection using ML, Artificial intelligence and deep learning. Many other known and unknown algorithms and methods may exist to solve the same issue with a different perspective. The Domain of Computer Vision and Machine Learning is still young and has tremendous scope for human well being. The understanding and possibilities are still unknown to mankind and can lead to various mysteries and scope for improvement in the decision Science domain.
written by: Jeet Barot
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs