
What is the RNN model?
RNN “Recurrent Neural Networks“ which is a type of neural network in Artificial Intelligence. This network has 2 major implementations:
Time Series Predictions-
Used to predict weather forecasts, Stock Market predictions, etc.
Natural Language Processing-
RNN is vastly use in NLP as the layers with which the RNN model is build, help in implementing various NLP applications. though One of them is Text Generation. however, which deals with creating a model that predicts the next word based on the previously used words and their grammar.
How to build an RNN model?
RNN model is similar to CNN models, just a few layers have to be change to get it working on text corpus( vocabulary/ collection of words/ sentences). The RNN model consists of the below layers.

As seen the only 2 new layers are Embedding and GRU, there is one more layer in use interchangeably i.e. LSTM layer.
Layers in RNN
Each Layer in the RNN model serves a different purpose, but the output of one is input to another.
First up Embedding Layer-
The Embedding layer can be took as a lookup table which creates each word as an integer, maps it to an embedding. The size of the embedding is a hyper-parameter which can be change by you as an experiment to see what works well for your problem.
Second GRU or LSTM (combined with Bidirectional layer)[optional]
LSTM: “Long Short Term Memory”
The LSTM recurrent unit tries to “remember” all the past knowledge that the network has gone through and also drops “forget” irrelevant data which is not needed for further processing. This is done by different activation functions “gates” which serve different purposes.
Each LSTM recurrent unit maintains a vector call as the “Internal Cell State” which describes the information that was passed by the previous LSTM recurrent unit to be retain.
The gates used are as follow:
- Forget Gate-What to forget
- Input Gate-What to add
- Output Gate-What the next hidden state will be
Note: The Internal Cell State is consider as a sub-part of the Input gate, but it’s not consider a gate in many LSTM literature.
GRU: “Gated Recurrent Unit”
Unlike LSTM, GRUs consists of 2 gates and do not maintain an “Internal Cell State”. The information which is store in the Internal Cell State in an LSTM recurrent unit is merge into the hidden state of the GRU. This collective information pass upon the next Gated Recurrent Unit.
The gates used are as follow:
- Update Gate- How much data to pass forward
- Reset Gate- How much data to forget
Note: The Current Memory Gate is consider as a sub-part of the Reset Gate, as this gate’s sole purpose is to reduce the effect of past information on current information.
Coming to Bidirectional, which is an optional prefix layer use up with a combination of both LSTM or GRU.
Example:
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM())
This layer is use to maintain the data flow in both directions i.e. the forward and backward, in normal LSTM, the data is only propagate in the forward direction.
Implementation of RNN
Similar to CNN models, RNN models also require some data preprocessing.
Here the data is in the form of text and audio, coming to just text generation using RNN. The preprocessing of text generation is pretty much simple, we need to break the sentences into single words and create a vector which stores all these words. This is ready using a function call as Tokenizer, tokenization is a process of breaking down sentences into tokens(words, characters, or sub-words).
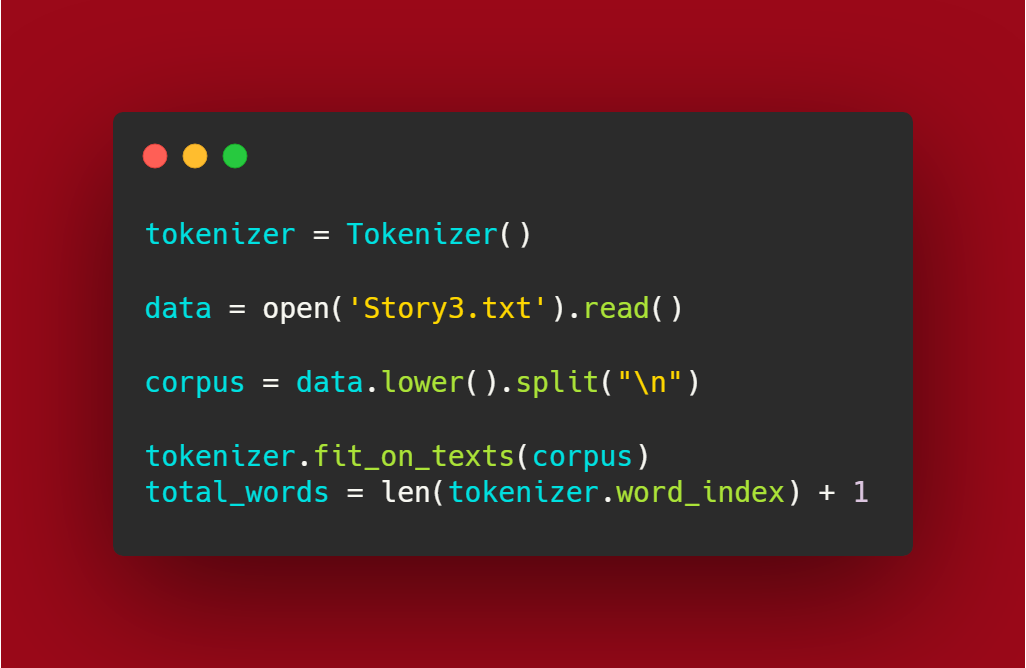
Here the data holds the sentences in the Story3.txt file. These sentences are then convert to lowercase and then tokenized using the function shown in the code. The total_words hold the number of training examples aka “m”.
The next step is to create an input_sequence by padding them appropriately to match max_length.
Example
If max_length=32 and the first line is of length 25 then 7 spaces will be pad up to keep the batch intact.

Then comes label creation and setting the x and y values, here slicing is use to get labels and trainable values for x, whereas for y values only the labels are mapped with total_words.

Finally Training the RNN model
Note: This code is create just for Story3.txt file.
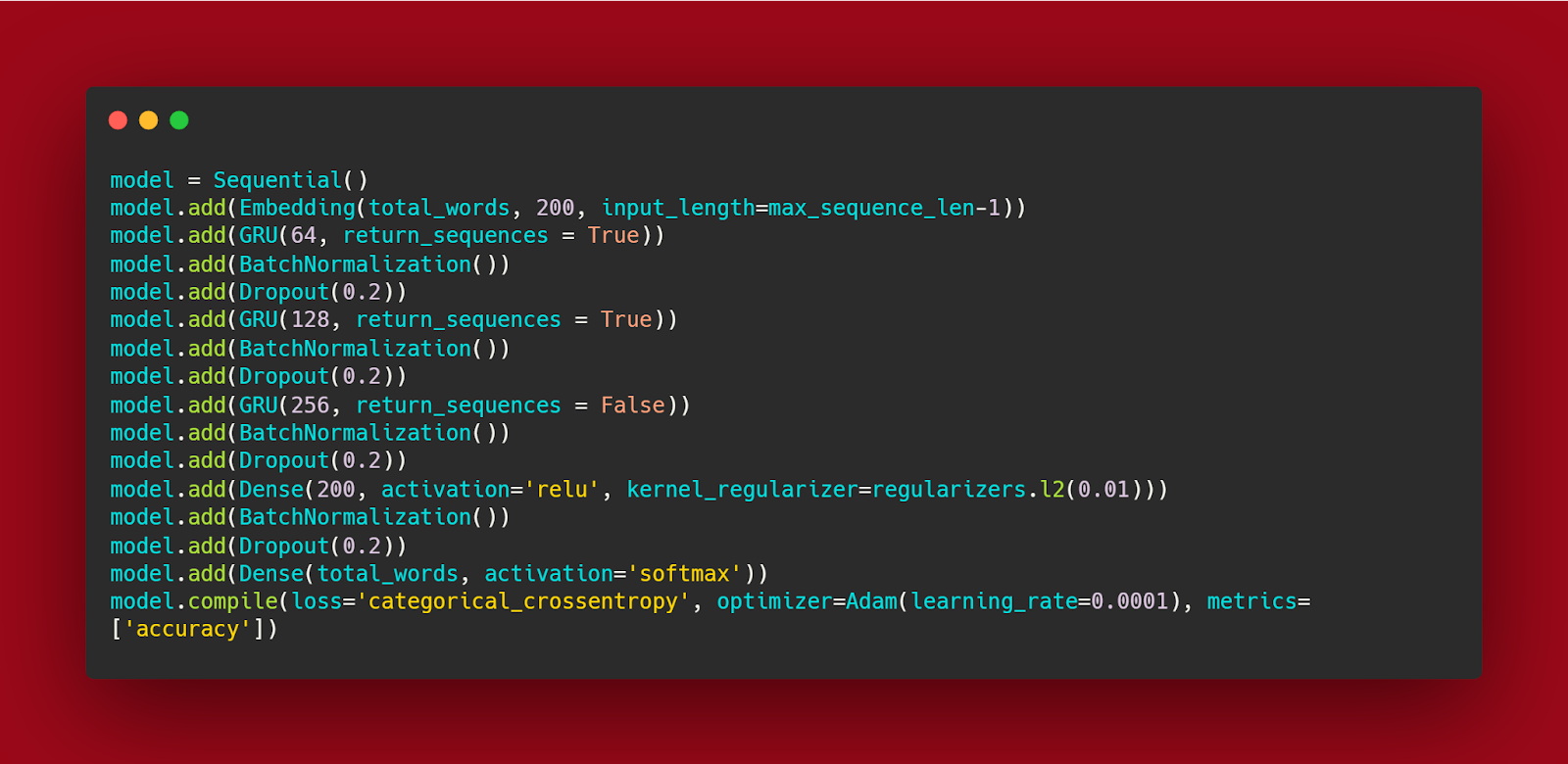
Each file you use for text generation you need to have an idea about the number of words in the file, this will help in modifying the model as needed.
Note: Training the model for 100-200 epochs may not yield good results and as the model is complete heavy using more nodes and neurons. thus, it affects the training time of the model.
Testing the Model
After the Implementation just the testing of the model is spare which you can do using the following code block:

Here the model is tested using a sentence, this sentence is required to give the model the basis on which the text needs to be generated.
Conclusion:
Using RNN for text generation makes us do experiments on the hyper-parameters and other values including number of words and number of layers to get better results.
Reference:
Written By: Pushpraj Maraje
Reviewed By: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs