
Linear Regression | Machine Learning Algorithms
Linear regression is one of the most popular and also important Machine Learning algorithms. thus, The representation is an equation to show a line that best fits the relationship between the input variable(X) and the output variable(Y). however, This means it finds how the value of the dependent variable is changing according to the value of the dependent variable.

Here, we thus represent a linear regression in Mathematically.

Where,
Y = Dependent Variable
X = Independent Variable
a0 = intercept of the line
a1 = Linear regression coefficient
ε = random error
Types of Linear Regression:
1. Simple Linear Regression.
If a single independent variable is used to predict the value of the dependent variable is thus called Simple Linear Regression.
2. Multiple Linear Regression.
If more than one independent variable is used to predict the value of the dependent variable is called Multiple Linear Regression.
Logistic Regression:
Mathematically, a logistic regression Machine Learning Algorithms predicts P(Y=1) as a function of X. so, It is a simple machine algorithm that can be used for classification like spam detection, cancer detection, etc.
Logistic Regression is thus used as a more complex cost function, this cost function can be defined as the “Sigmoid function”.
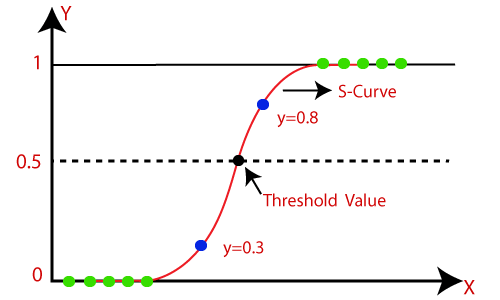
What is the Sigmoid function?
The map functions with any real value between 0 to 1. therefore, In machine learning, we use sigmoid to map prediction to probabilities.
Sigmoid function:
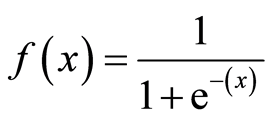
Types of Logistic Regression
- Binary Logistic Regression: In this, a dependent variable will also have only two possible types either 0 and 1. For example yes or no, Success or Failure, and Win or Loss.
- Multinomial Logistic Regression: thus, though a dependent variable will have 3 or more possible types. Like “A” or “B” or “C”.
Decision Tree | Machine Learning Algorithms
Decision tree structure like flowchart (e.g. whether you are fit or not fit). Each leaf node draws a class label and the branch represents a mixture of features that lead to those class labels.
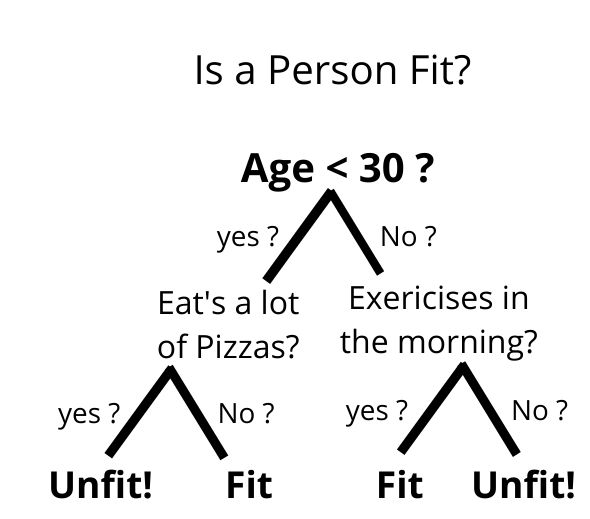
The decision tree can be explained using the binary tree. We want to predict whether a person is fit or unfit given data. Information like Age, Eat, habit, exercises.
so, Here decision node questions like ‘What is age?’, ‘Does he exercise?’, ‘Does he eat a lot of pizzas? leaf nodes are outcomes like either ‘fit’ or ‘unfit.’
It is simple to understand as it follows the same plan as a human while making any decision in real-life. thus, It can be very useful for solving decision-related real-life problems.
The decision tree contains lots of layers, so it is complex.
There are mainly two types of Decision trees:
- Classification trees.
- Regression trees(Continuous data type)
Random Forest:
Random Forest combines the simplicity of the decision tree with the improvement inaccuracy.
Decision trees are easy to create, easy to use, and thus easy to interpret.
To create a bootstrapped dataset that is the same size as the original dataset, we just randomly select samples from the original dataset. The important part is that we are allowed to pick the same sample more than once.
| Chest Pain | Good Blood Circ. | Blocked Arteries | Weight | Heart Disease |
| No | No | No | 125 | No |
| Yes | Yes | Yes | 180 | Yes |
| Yes | Yes | No | 210 | No |
| yes | No | Yes | 167 | Yes |
also, This is a simple Data-set for a random forest classifier.

however, This is the second random selection from the Original Dataset.

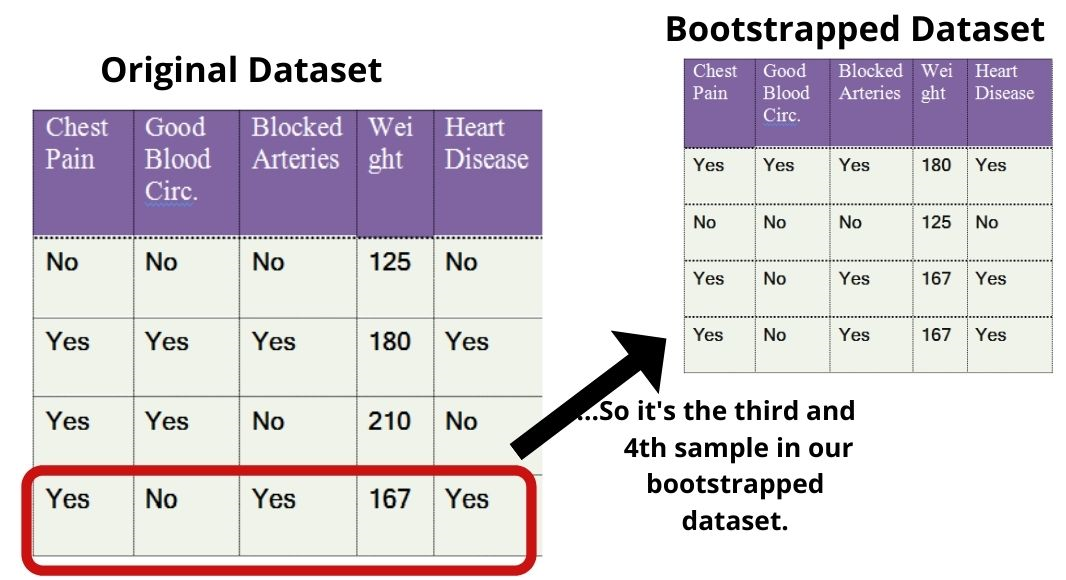
Here’s the fourth randomly selected sample (Note: it’s the same as the third)
create a decision tree using the bootstrapped dataset, And we thus use a random subset of variables for each step.
The variety is what makes random forests more effective and useful than individual decision trees.
After running the data down all the trees in the random forest, we see which option received more votes.
Bootstrapping the data using the mass to make a decision is called “Bagging.”
Boosting with AdaBoost:
AdaBoost full name Adaptive Boosting. It’s prepare by Yoav Freund and Robert Schapire.
Let’s start using Decision Trees and Random Forests to explain the three main concepts of AdaBoost.

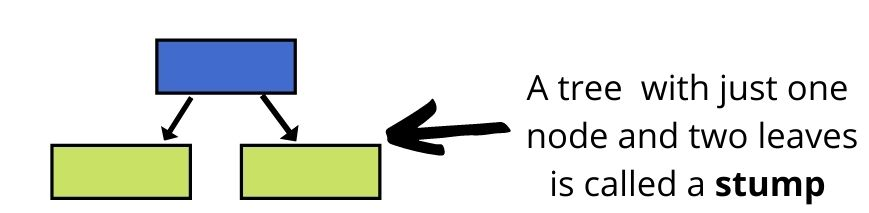
In a Forest of Trees made with AdaBoost algorithm, the trees are usually just one node and two leaves.

Stumps are not great at making accurate classifications. A stump can only use one variable to make a decision.
Thus, Stumps are technically “Weak learners”.
thus, it combines many ‘weak learners’ to make classifications. The weak learners are almost always stumped.
Some stumps get more say in the classification than others.
Each stump is made by taking the previous stump’s mistake into account.
Conclusion:
Here, we have covered most top machine learning algorithms from Data Science.
Written By: Paras Bhalala
Reviewed By: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs