
The Regression model can be summed up to help numerous classes openly, without preparing and consolidating numerous paired classifiers. This is called Softmax Regression, or Multinomial Logistic Regression.
The thought is very straightforward: when given an occasion x, the Softmax Regression model first registers a score sk(x) for each class k, at that point gauges the likelihood of each class by applying the softmax function (likewise called the normalized exponential) to the scores. The condition to register sk(x) should look natural, as it is much the same as the condition for Linear Regression forecast given below:-
sk (x) = xT θ(k)
Softmax Score for Class K
Note that each class has its own committed boundary vector θ(k). Every one of these vectors is regularly put away as columns in a boundary lattice Θ.
Whenever you have processed the score of each class for the case x, you can assess the likelihood Pk that the example has a place with class k by running the scores through the softmax work (given underneath): it registers the exponential of each score, at that point standardizes them (partitioning by the amount of the relative multitude of exponentials). The scores are for the most part called logits or log-odds(despite the fact that they are really unnormalized log-odds).
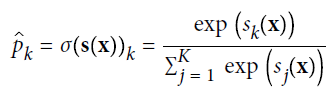
Softmax Function
- K is the number of classes.
- S(x) is a vector containing the scores of each class for the occurrence x.
- σ(s(x))k is the assessed likelihood that the occasion x has a place with class k given the scores of each class for that occasion.
Much the same as the Logistic Regression classifier, the Softmax Regression classifier predicts the class with the most elevate assess likelihood (which is just the class with the most noteworthy score).
While Softmax regression is utilize for multi-class order.
Say there are K classes, the equation of the speculation for each class is:-
P(y = i|x;W_i) = h(x, W_i) = exp(- W_ix)/∑exp(- W_kx), k is from 0 to K
Notice that W is a Matrix. W_i is the ith vector of W that compares to the likelihood of y=i, P(y=i|x; W_i). The cross-entropy is the loss over K classes:
Loss(W, x, y) = ∑ – y_i ×log(h(x, W_i))
The inward total is over K classes and the external aggregate is over example focuses. The cross-entropy loss ends up being the log of the likelihood function L(W):-
P(y|x;W) = ∏ h(x, W_i)^y_i
L(W) = ∏ P(y|x;W)
Where P(y|x; W) is require to be a multinomial circulation and y_i is the ith component of the one-hot encoder of name y, not the class esteem. Expanding L(W) is identical to limiting Loss(W, x, y).
More About Softmax Regression
As referenced above, W is a framework with a size of K×d, where d is the number of highlights of x. For the softmax layer of a neural organization, W is the load of the layer with the size of d×K, where d is the component of the yield from the past layer and K is the number of classes. In fact, during preparation, the softmax actuation work is require in order to process the cross-entropy misfortune and backprop the loads. Nonetheless, during derivation, the enactment can be overlooked and the yield mark is the one with the maximum logit.
In a real sense, there’s an explanation behind calling it softmax. So softmax is really the activation function that we chose for our logistic regression case here:-

as our activation function (sigmoid function) in vanilla logistic regression, in softmax regression we use
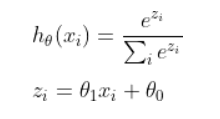
called the softmax activation function. This capacity has a piece of genuine softmax function which is

This implies that genuine softmax is an estimate of max function however a differential form of it, as demonstrated as follows.

So we have seen that the softmax activation function contains the softmax function consequently the name. The differentiable is a must for any activation to have the option to boost loglikelihood and in this way show up at an update rule for boundaries/loads of the last forecast articulation.
Dataset:
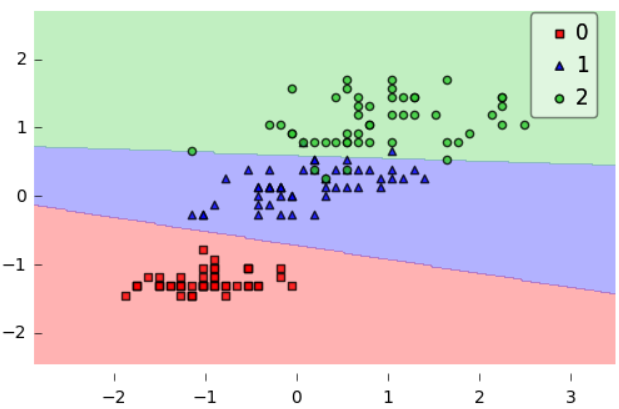
Iris dataset which has three classes from sklearn.datasets. Functions created are softmax activation function, gradient calculator, one-hot encoding, cost function.
1) Softmax Activation function:-

2) Cross-Entropy Function to be minimized is called Cost Function:-

3) One Hot Encoding:-

4) Gradient Calculator:-

where preds is a probability network compare to every perception.
Softmax ends up being a significant one, in this way might meet it again in Neural Nets.
written by: Kamuni Suhas
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs