
In this blog, we would be solving a sentimental analysis problem statement based on the IMDB reviews dataset.
so, We begin with understanding the problem statement and designing a rough walkthrough for solving it.
Now, what exactly is meant by sentimental analysis?
Sentimental analysis refers to using Natural language processing on textual data to study and extract meaningful subjective information from them.
In our case, we have also been given an IMDB movie review dataset that contains about 50k sentimental movie reviews as positive or negative.
however, Our aim is to study the given dataset build and train a model such that it would be able to classify a new unseen review as positive or negative accurately.
so, Having understood the problem statement now comes the initial step of data analysis.
Libraries required for Sentimental Analysis:-
In this project, we would be using certain libraries such as:-
- Numpy
- Pandas
- Scikit-learn
- Nltk
- re
Data Analysis:-
however, The first step of building a model requires proper analysis of the given dataset.
So, start by loading the given dataset into a data frame in pandas.
df = pd.read_csv(“ __ “) —-> load the dataset
df.head(n) —-> display first n rows of the dataset

you would observe the dataset contains about 50,000 rows along with 2 columns named ‘review’ and ‘sentiment’. so, The review column contains the human written textual reviews and the sentiment column contains the class of the review as a positive or negative one.
The dataset didn’t contain any null values which is a good thing.
therefore, exploring individual features you would observe that the review column contained a language with too much noise and randomness in it making it unsuitable to be used directly. Like the individual reviews contained Html tags,Stopwords(a, an, from, to, etc), words having the same root word but used differently(played, playing, play), special characters, etc.
hence, all the previously mentioned factors don’t have any effect on deciding the sentiment rather they just contribute to making the dataset complex which in turn would affect the overall model performance. So, it’s necessary to remove all such noise from the dataset making it clean for training.
To clean the reviews we would be using the nltk module provided by python that contains multiple tools for language and speech processing.
import re —> regular expressions
import nltk —> natural language toolkit
# considering all the noise factors we would now also be defining a generalized function to clean the text and convert it into the required form.
# function to clean text:-
def clean_text(sample):
sample = sample.lower() # converting to lowercase
or sample = sample.replace(“<br /><br />”, “”) # replacing html tags with spaces
sample = re.sub(“[^a-z]+”, ” “, sample) # replacing special char with spaces
also, sample = sample.split(” “)
or sample = [word for word in sample if word not in sw ] # removing stop words
sample = ” “.join(sample)
return sample
thus, The above function removes all possible noise from the textual data and makes it suitable for model training now.

After taking care of the review column now comes the sentiment column which has categorical data. Now, we need to convert the categorical data of sentiment columns into binary form using either label encoding or one hot encoding technique.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # maps the categorical values into 0’s and 1’s
df[‘sentiment_n’]=le.fit_transform(df[‘sentiment’])

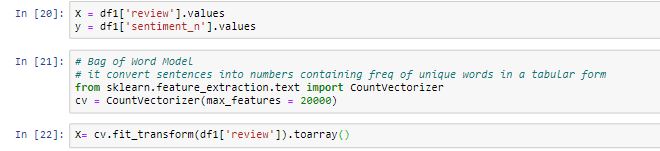
Lastly, we need to make a bag of words model that contains frequency of unique words in the form of a table.
# Bag of Words Model
# it convert sentences into numbers
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features = 20000)
Now, we are ready to build our model as all the randomness of our dataset has been taken care of by us.
MODEL building and training:-
so, we would be building our model, and here I would be using the Multinomial Naïve Bayes algorithm to train our model as it has better performance in classification type problem statements.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
mnb = MultinomialNB()
Now fit the model and try predicting
accuracy_score(y_test,y_pred) —-> get the accuracy score of model performance(85 % in our case).We could now use this model to predict sentiments of new reviews.

( The scores obtained can be further improved by hyperparameter tuning. As they say, there’s always a massive scope for improvement just keep on experimenting till you build your perfect model … ! ).
Hope this blog could help you clear the basic concepts regarding sentimental analysis problem statements.
written By: Rohit Kumar Mandal
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs