
Introduction to Real Estate
Real estate is one of the most important sectors as far as the economy is concerned. Real estate refers to the buying, selling, leasing, and renting of plots, houses, and commercial properties. According to federal statistics, real estate contributed approx 13% of GDP to the U.S in 2018 and also employed 2 million people. This shows how big the real estate sector is.
Real estate prices are changing day by day. So, In this article, we are going for Prediction Of Housing Prices in California by using machine learning algorithms. We have considered almost all the factors which are used while deciding the valuation of the property.
This is a regression problem. The dataset contains 20640 entries and 10 features. The features are listed down.
Longitude, Latitude, Housing Median Age, Total Rooms, Total Bedrooms, Population, Households, Median Income, Median House Value, Ocean Proximity. Median House Value is the output/ dependent variable and the rest of all are independent/input variables.
Prediction Of Housing Prices
Now let’s start with importing the dataset and some libraries.
output-


Output-
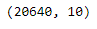
There are a total 20640 rows and 10 columns in the dataset. Out of 10 variables, only ocean proximity is the categorical variable, and the rest others are numerical variables.
The info() method is useful to get a quick description of the data, in particular, the total number of rows, and each attribute’s type and number of non-null values.
Output-

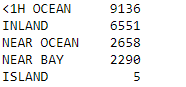
Here we can see that the total_bedrooms feature has 207 missing values. Now we need to handle these missing values. Also, we know that the ocean proximity is the only column that contains the categorical data. So let’s find out the number of categories and data points belongs to each category by the value_counts() method.

Output –
Now also look at the numerical data. describe() method gives an overview of the numerical data.

Output-
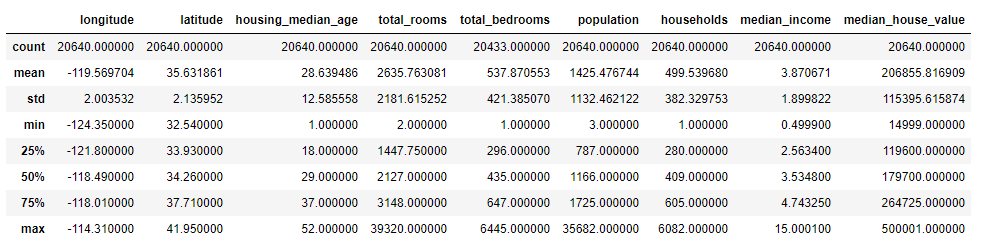
describe() function gives the count, min, max, mean, and quantiles values for the numerical features. These values are self-explanatory.
Another way to feel the data is to plot the histogram of each attribute.

Output-
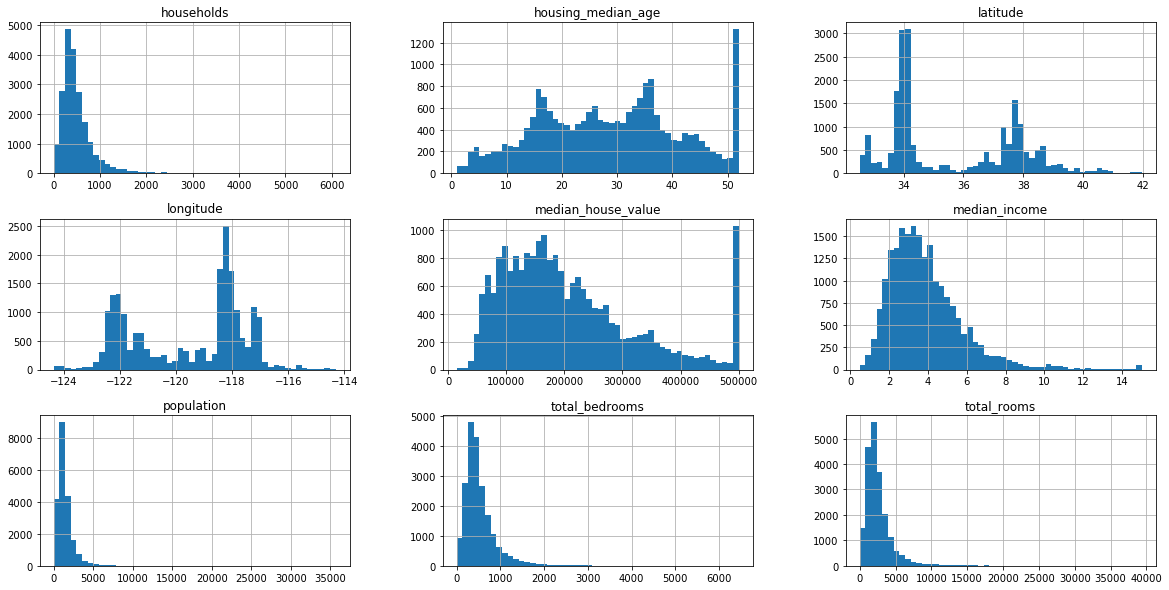
Observations-
- Median house value, housing median age, median income values are scaled and capped.
- Many histograms are tailed heavily.
Now we have a better understanding of the data we are dealing with.
Now let’s do some EDA on a given dataset to gain some insights. Since we have geographical information so let’s create a scatter plot to visualize the data points.

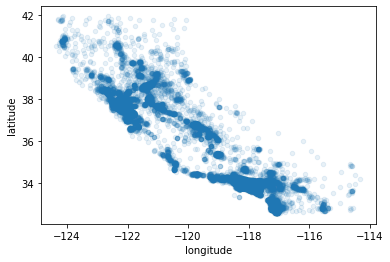
We have used an alpha=0.1 and now you can clearly see the high-density areas near Los Angeles and some other parts of California.
Now let’s look at the housing prices. s represents the marker size and c represents the colour value.
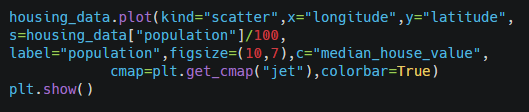
Output-

This shows that the house prices depend upon the location and population density.
Now let’s find out the correlations of each attribute with the median house value.

Output-
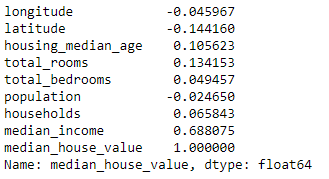
The correlation coefficient ranges from -1 to 1. If the correlation coefficient is 1, then this means that as the one variable value goes up then the other variable value also goes up and if the correlation coefficient is -1, then this means that as the one variable value increases then the other variable value decreases.
Here we can see that the median income feature strongly correlates to the median house value as compared to the other features. So let’s zoom in more with the help of a scatterplot.

Output –
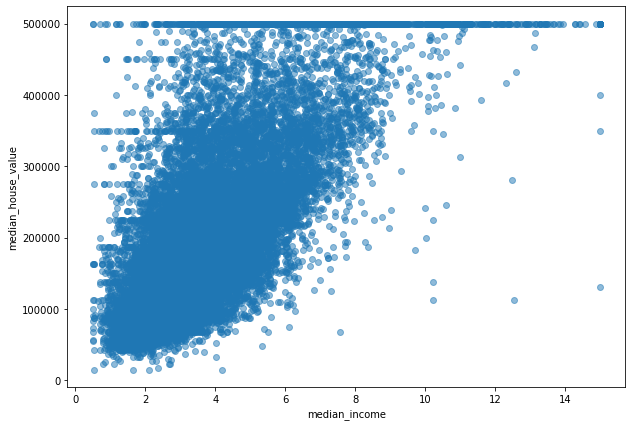
Indeed the relationship between median income and median house value is strong. You can clearly see the upward trend and the values are not too dispersed. The price cap we noticed earlier is clearly visible at $500000.
Now let’s try out the various attribute combinations. Total rooms in the district is not a useful feature. Total rooms per household is the feature many people want to know. Similarly, the total number of bedrooms is not a useful feature so maybe you can compare it with the total number of rooms.

Output –

Bedrooms per room strongly correlated to the median house value as compared to rooms per household and population per household. Lower bedrooms per room house tend to be expensive.
Now we have better insight into the data. Let’s prepare the data for the machine learning algorithms.
First, take care of missing data. We know that the total bedroom feature has 207 rows of missing data.

So we have filled the missing values with the median value of the total bedroom feature.
Separate the dependent variable from the dataset.

Now splits the data into train and test. here we have used an 80-20% split.

Output-

We already know that the ocean proximity is the categorical variable. So, we need to convert this text feature into a numerical feature because most of the machine learning algorithms prefer to work with the numerical feature.
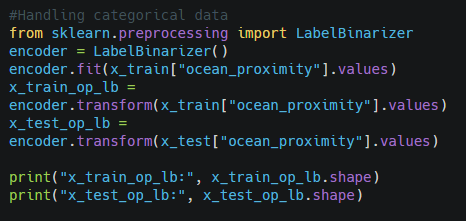
Output-

This dataset has many numerical features and each feature has a different scale. So we need to standardize the numerical data by using Normalizer or StandardScaler method.

Here StandardScaler method is used for feature scaling. Standardscaler modifies the data in such a way that each feature has a mean equals to 0 and variance equals to 1.
Now up to this we have completed the EDA, data cleaning, and preprocessing. Now combine the numerical data and categorical data and apply various machine learning algorithms.

Let’s first train the linear regression model
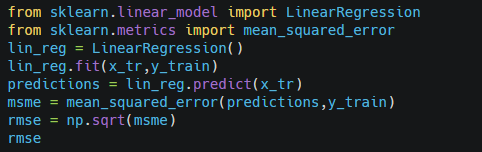
Output-
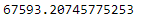
This is clearly not a great score. $67593.21 is the mean error in median house value. however, This is not satisfying. This is an example of underfitting. The main ways to fix underfitting are to select a more powerful model, add some more powerful features, or to reduce the constraint on the model.
Let’s try some complex model to see how it works.

Output-

Zero error. Does this mean that this model is perfect?..No. this is an example of overfitting. you don’t need to touch the test dataset until you are confident about your model.
Now let’s try the RandomForestRegressor algorithm.
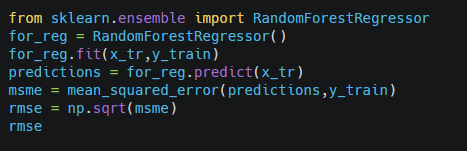
Output-

This score is far better than the previous 2 models. It Looks like the RandomForestRegressor model is the promising model. But still, the rmse value is on the lower side which means that model is still somewhat overfitted to the training data.
Let’s fine-tune the model by using grid-search.
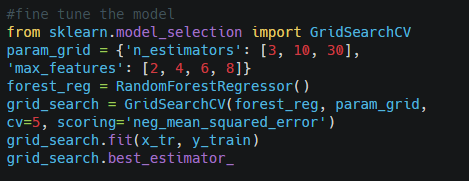
Output-

GridSearchCV experiments with the different combinations of specified hyperparameters and finds out the best combination of hyperparameters.
The best estimator gives you the best parameter values for better Prediction Of Housing Prices.
Now use this best estimator value and again build a RandomForestRegressor model and feed the training data to the model and calculate the root mean square error.
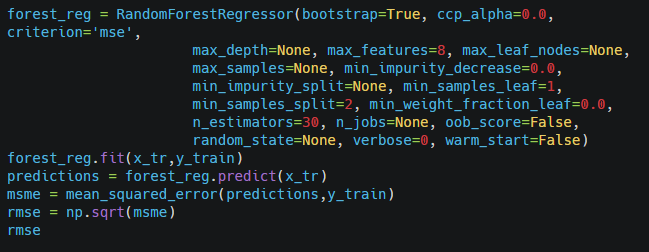
Output-

Now use this model on testing data and find out the root mean square error value on testing data.

Output-

Still, the performance is not as great as we measured on training data. But it is much better than the linear regression and decision tree algorithm. If you do a lot of hypertuning on the training data then the model is likely to perform better on training data and will likely not perform on unknown data.
So, we have seen the 3 models and hopefully, you have got an idea of how the machine learning project looks like. Now you try to create another important feature and try other regression models and observe the results.
Conclusion-
In this article, we learned about how the machine learning project works from data importing, data cleaning, and preprocessing to training the data on machine learning algorithms. Here, we have seen the linear regression, decision tree, and random forest regressor models.
however, based on root mean square error values, random forest regressor best fits the data as compared to the rest two algorithms. One can try other algorithms or create new features that can help for Prediction Of housing prices.
written by: Sanket Landge
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs