
Naive Bayes Algorithm
Another very talked-about supervised Classification rule is Naive Bayes mathematician.
Before diving deep lets perceive What will Naive Bayes Algorithm signify.
- This rule is termed “Naive” as a result of it makes a naive assumption that every feature is freelance of different options that isn’t true in the world.
- As for the “Bayes” half, it refers to the statistician and thinker, and therefore the theorem named after him, Bayes’ theorem, that is that the base for the mathematician rule.
so, Before Going Naive {bayes|Bayes|Thomas mathematician|mathematician} we have a tendency to see concerning Bayes Theorem
Bayes Theorem
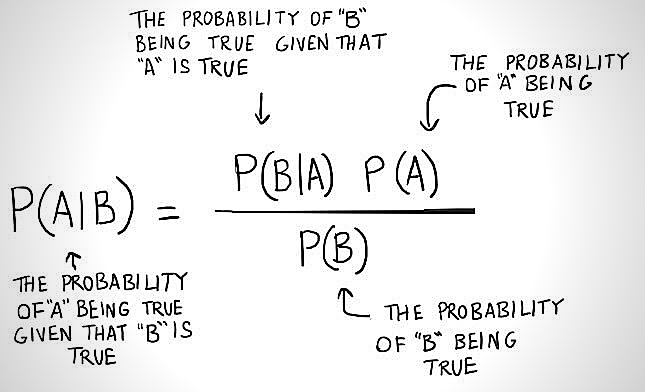
Where,
P(A|B) is that the likelihood of thus hypothesis A given the information B. This is often known as the posterior likelihood.
P(B|A) is that the likelihood of information B as long as the hypothesis A was true.
P(A) is that the likelihood of hypothesis A being true (regardless of the data). thus, This is often known as the previous likelihood of A.
P(B) is the likelihood of the information (regardless of the hypothesis).
P(A|B) or P(B|A) are conditional chances P(B|A) = P(A and B)/P(A)
Types of Naive Thomas Classifier:
- Multinomial Naive Bayes Algorithm
- Bernoulli algorithm
- Gaussian Naive Bayes Algorithm
1. Multinomial:
this can however largely used for document classification drawback, i.e whether or not a document belongs to the class of sports, politics, technology etc. therefore, The features/predictors employed by the classifier area unit the frequency of the words gift within the document.
2. Bernoulli:
this can be the same as the multinomial algorithm. however the predictors are unit mathematician variables. The parameters that we tend to use to predict the category variable take up solely values affirmative or no, for instance if a word happens within the text or not.
3. mathematician Naive Thomas Bayes :
once the predictors take up endless worth and aren’t separate, we tend to assume that these values are a unit sampled from a normal distribution.
How does Naive Bayes Algorithm rule works?
Let’s be aware of its victimisation associate classic example.
Below I even have a coaching knowledge set of weather and corresponding target variable ‘Play’ (suggesting prospects of playing). Now, we’d like to classify whether or not players can play or not supported atmospheric phenomenon. Let’s follow the below steps to perform it.
- Step-1: Convert the info set into a frequency table
- Step-2: produce a chance table thus by finding the possibilities like Overcast likelihood = 0.29 and likelihood of enjoying is 0.64.
- Step-3: currently, use Naive theorem equations in order to calculate the posterior likelihood for every category. The category with the very best posterior likelihood is the outcome of prediction.
example
This is the below statement :
Consider the given Dataset, apply Naive Bayes algorithm.
To predict that if fruit has following properties then which type of fruit it is?
X={ Yellow, Sweet, Long }
Dataset:
| Fruit | yellow | sweet | long | total |
| mango | 350 | 450 | 0 | 650 |
| banana | 400 | 300 | 350 | 400 |
| others | 50 | 100 | 50 | 150 |
| total | 800 | 850 | 400 | 1200 |
Here is the Answer:

Applications of Naive Bayes Algorithm :
- Naive Bayes is widely used for text classification.
- Another example of Text Classification where Naive Bayes is mostly used is Spam Filtering in Emails.
- Other Examples include Sentiment Analysis, Recommender Systems etc.
- NB can also be used to predict the weather report based upon the atmosphere features.
written by: Mohd Zaid
reviewed by: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs