
Let’s Start, K means clustering is Known for unsupervised machine learning algorithms.
We know it is an unsupervised algorithm.That makes inference from datasets.And Make Cluster with It or You can say ,it converts unlabeled data to meaningful Information.
In K Means You Defined Target number of k , Which denotes to the number of centroids you need in the data set. A centroid is the real location which represents the center of the cluster.
It contains data points which are allocated to the cluster .
And Here is One thing , What is Mean in K ‘Means’ in the K-means; it means to average the data and find the central Point.
Applications of K- Means:
K-means algorithms are Much popular. Due to its applications such as Market Segmentation, Document Clustering, Image segmentation, and Image Compression.
- It Finds Meaningful Insight with data.
- It helps to target customers.
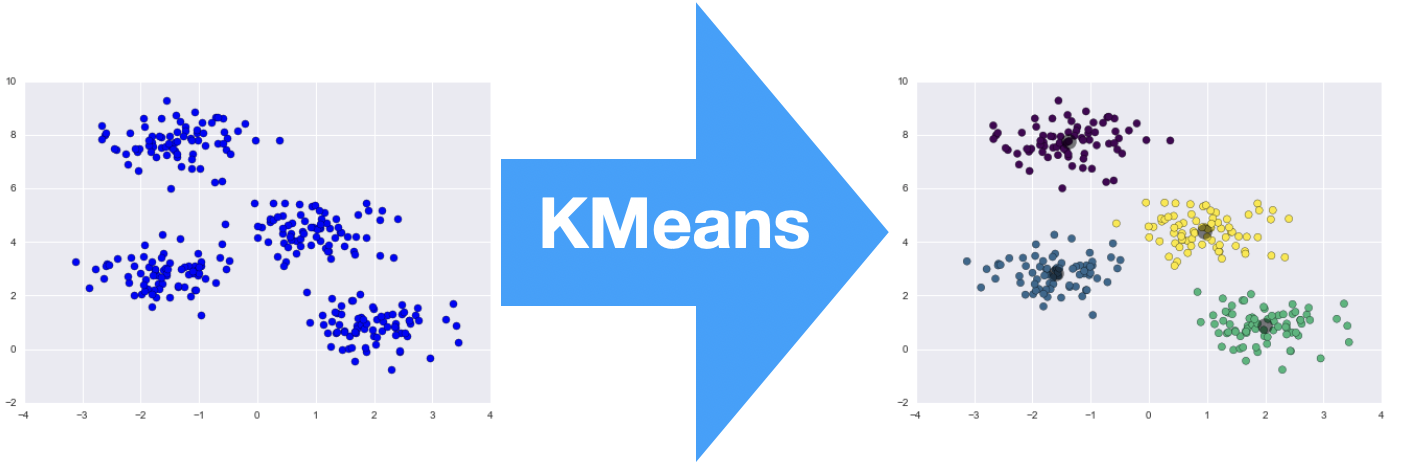
With the above Diagram We see some data points which we don’t know who they are but after using K-Means it has some labels and associated color.
Advantages / Disadvantages of K-Means Algorithms:-
Advantages:
- Ease of Implementation and high speed performance
- Measurable and efficient in large data collection
Disadvantages:
- Selection of optimal number of clusters is difficult.
- Selection of the initial centroids is random.
How the Clustering Algorithm Works ?
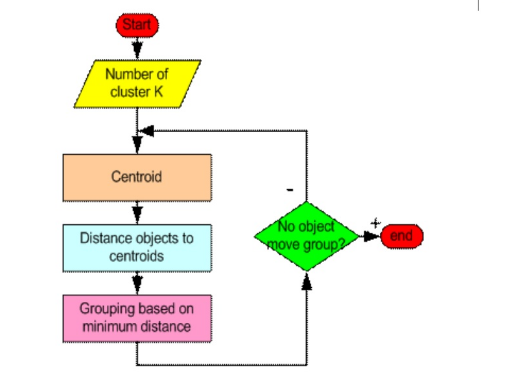
Steps 1:
Start with a Decision on the value of k = number of clusters.
Step 2 :
Put any Initial Partition that classifies the data into k clusters.
Step 3 :
Compute its distance from the centroid of each of the clusters by taking each sample in sequence
Step 4 :
Here, Grouping based on the distance.
Lets Try One Example :
We first implement the k-means algorithms on a dataset and see how it works.
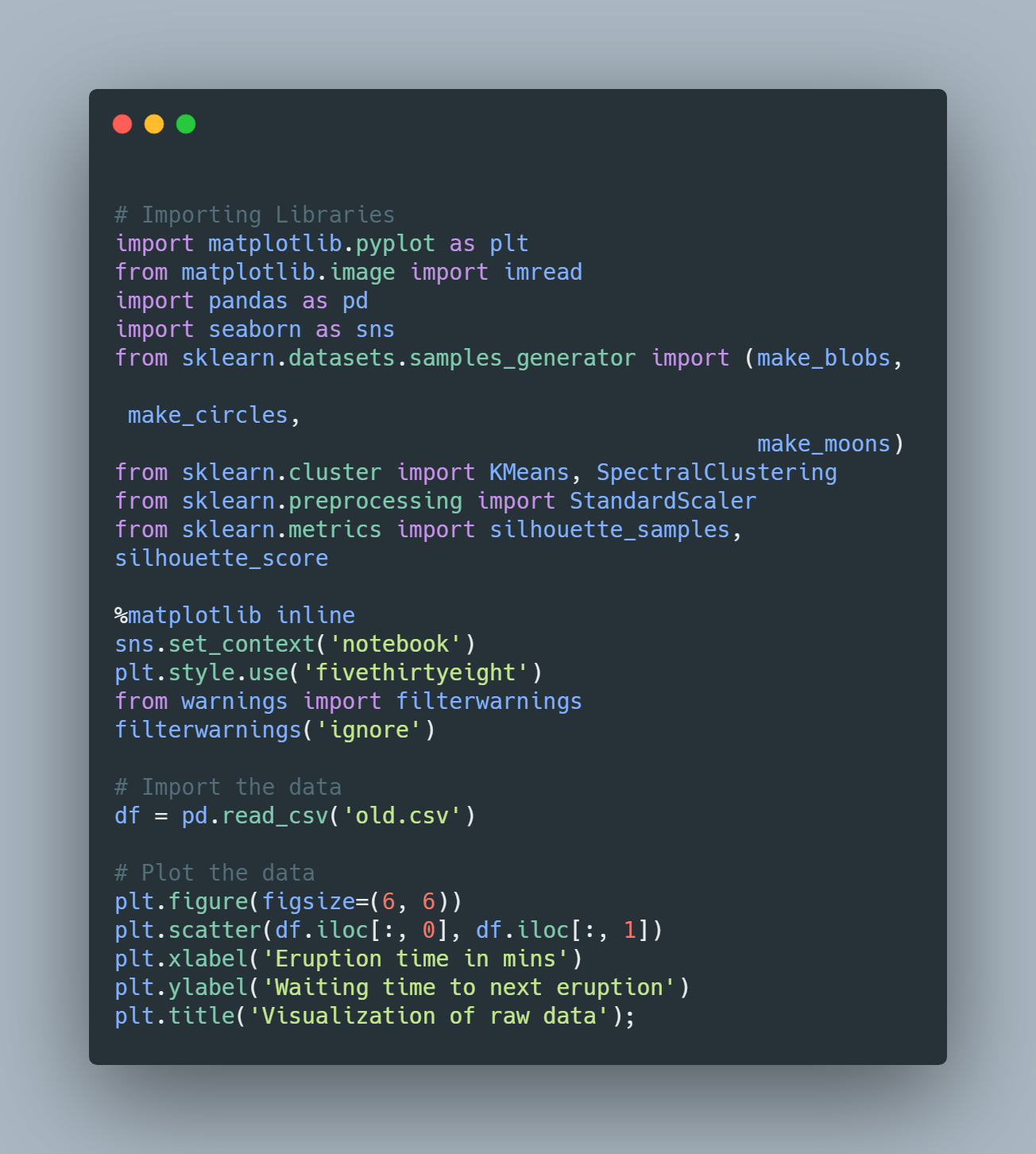
Above code ,We Just Import the data and Try To Visualise the data .
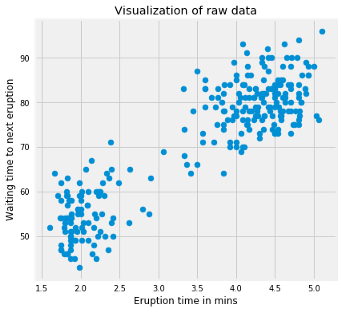
We see this data because it’s easy to plot and visually spot the clusters .
Let’s standardize the data first and run the k means algorithm on the standardized data with k=2.

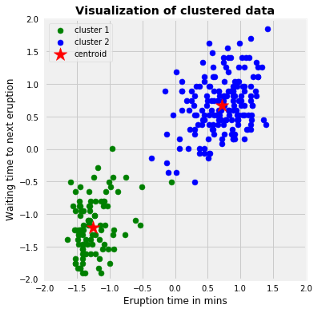
The above graph show the scatter plot of the data colored by the cluster
In this example, we chose K=2. The centroid of each cluster can be denoted by The symbol ‘*’.We can think of those 2 clusters as different kinds of behaviors under different scenarios.

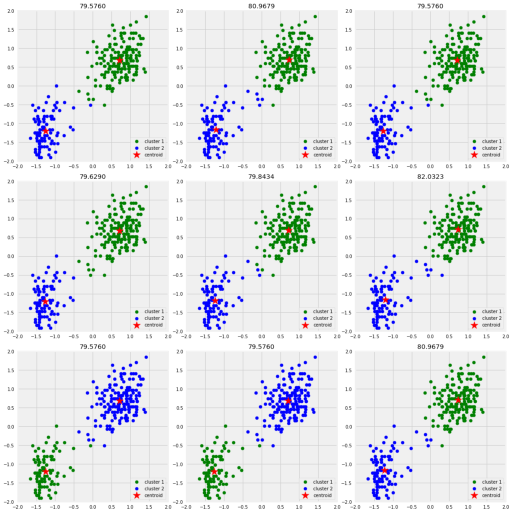
As the graph above shows ,
We tried different ways to intializations then we would pick the one with the lowest sum of squared distances.
Evaluation Method in Clustering :
- Elbow Method: The elbow method helps us on what a good k number of clusters would be based on the sum of the square distance between data points and their assigned cluster centroids. We Pick k at where ssd are elbowed.

The graph above shows that k = 2 is a good choice .
- Silhouette analysis: we can choose silhouette analysis instead of elbow method because silhouette method can calculate silhouette coefficient and easily find exact number of k.
Let’s see the example :
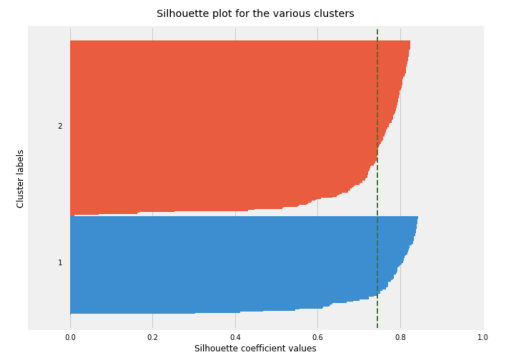
Here we Need To remember to calculate silhouette coefficients.The value of the silhouette coefficient lies between[-1,1] . A score of 1 denotes the meaning of data point 0 is very compact within the cluster to which it belongs and far away from the cluster.The worst value is -1 .Values near 0 means it’s overlapping clusters.
Conclusion :
the Algorithm is quite useful for clustering algorithms. Using the elbow technique and silhouette technique We can evaluate the algorithm. Here, Silhouette is Much Precise over the elbow technique.
Hence, The goal is to group data points into subdivided groups. It’s Good When Making a Business Decision.
Article By: Ayosharya Das
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs