
Introduction to IPL Match Prediction:
Here we have created an IPL match prediction model for winner using Machine Learning Algorithm and Python. We used 2008 to 2019 data for creating the IPL match prediction model. In this, I used five features team names, toss winner, toss decision, and venue.
Step 1: Download the Data(Data Gathering).
- You can download the data from Kaggle. Here I am sharing the link of Kaggle IPL data.
Link:https://www.kaggle.com/nowke9/ipldata
- Import the data using pandas read_csv function. And Import necessary Library
Import Library:

Importing Data:
Now read the dataset from CSV file and display the top 5 records.
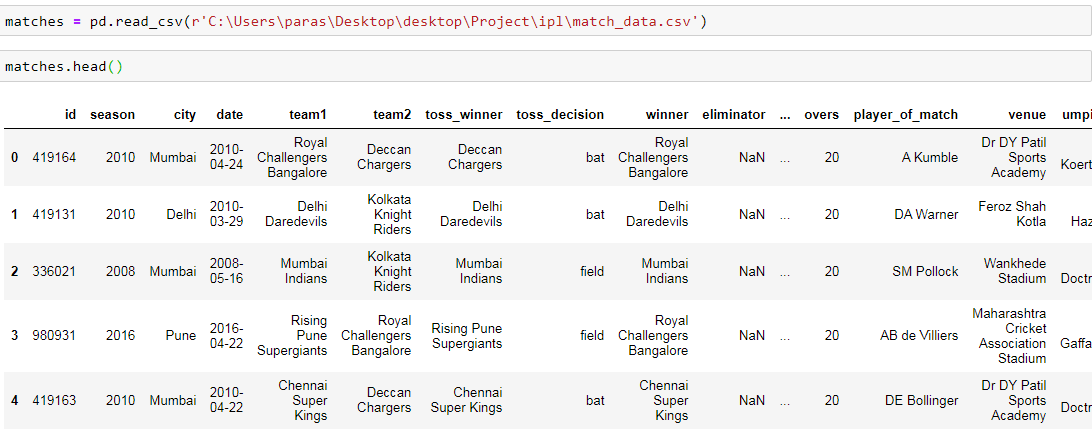
Understanding the DATASET:
The data-set for IPL Match Prediction consists of 18 columns:
- Id: The match id to uniquely identify each match.
- Season: The season on which the match was held.
- City: The name of the city where the match was held.
- Date: The date on which the match was held.
- Team1: The name of team1.
- Team2: The name of team2.
- Toss_winner: The toss winner team takes the decision to take bat or field.
- Toss_decision: The toss winner team takes the decision bat or field.
- Result: The result of a normal, tie, or no result.
- dl_applied: If DL rules applied or not applied.
- Winner: The name of the winning team name.
- Win_by_runs: How many runs did the winning team win.
- win_by_wickets: How many wickets did the winning team win.
- player_of_match: The name of the player name.
- venue: The name of the stadium.
- Umpire1: The name of the on-field umpire.
- Umpire2: The name of the on-field umpire.
- Umpire3: The name of the third umpire.
Step 2: Data Cleaning (Data Pre-Processing).
This is the most important step. If you miss this, no matter how well you build the models, you can’t get good outputs. In this step we will remove all the unused columns. Here I have shown how to remove the unused columns.

Also, we are filling in the missing values. in this data-set city name and winner team name is missing. In the city name fill using venue name. Here I have shown how to fill missing values.

Step 3: Exploratory Data Analysis.
EDA is for seeing what the data can tell us beyond the formal modeling. You understand when you visualize it pictorially. Pictures speak a lot of data.
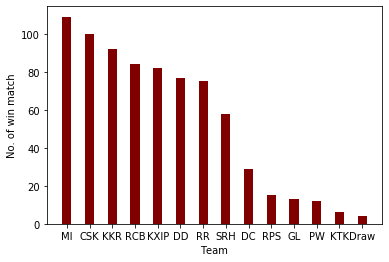
Here we are showing which team has won how many times.

Also, here we are showing how many times have won from a match played in total.

Also, Here we are showing below two graphs. The first graph describes the total number of toss win teams. And the second graph describes the total number of match wins.

Step 4: Feature encoding.
It is the process of transforming a categorical variable into a continuous variable and using a team in the model.
In feature encoding first, we replace the team name with a short name. Mumbai Indians to MI, Kolkata Knight Riders to KKR, Royal Challengers Bangalore to RCB, Deccan Chargers to DC, Chennai Super Kings to CSK, Rajasthan Royals to RR, Delhi Daredevils to DD, Delhi Capitals to DC, Gujarat Lions to GL, Kings XI Punjab to KXIP, Sunrisers Hyderabad to SRH, Rising Pune Supergiants’ to RPS, Rising Pune Supergiant to RPS, Kochi Tuskers Kerala to KTK, and Pune Warriors to PW.
Then after encoding team1, team2, toss_winner, and winner features. In this, we convert the numeric value. MI to 1, KKR to 2, RCB to 3, DC to 4, CSK to 5, RR to 6, DD to 7, GL to 8, KXIP to 9, SRH to 10, RPS to 11, KTK to 12, PW to 13.
And in the toss_decision field have 2 unique values, So we convert bat to 0 and field to 1.
Here we convert the Feature variable into numeric values.

Step 5: Model Creation.
We did our data importing, data pre-processing, exploratory data analysis, feature engineering. Now it’s time to build models that predict the class label. Here we are using the RandomForestClassifier model.

Step 6: Testing and accuracy of our model.

IPL match between KKR and CSK. KKR won the toss and chose to bat. The match is being played in Kolkata. As per our model, KKR wins this match.

Here we are shown a prediction function and convert numeric value.



Conclusions:
In this we have limited data, so we can not create powerful models. We believe this model performance will increase, if we were given a large amount of data.
written by: Paras Bhalala
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs