What is NMT?
NMT stands for Neural Machine Translation which comes from machine translation. Here the use of neural networks is complete to do the machine translation of one language into another.
NMT helps in translating using grammar, parts-of-speech, vocabulary of the language to find correct replacement in other languages.
Example:
1. How are you today?
Translating to German
Wie geht es Ihnen heute?
Following is the historic translation of JFK’s speech that created confusion during the cold war.
“Ich bin ein Berliner” which also means “I am a jelly donut”.
Link for optional reading
The above example gives us the need to find not just correct words to replace, but also to match relationships between words so that we don’t end up making a wrong translation.
Architecture of Neural Machine Translation
The NMT consists of Encoder and Decoder which help in translating. Encoder takes a sequence as input in one language, whereas the decoder decodes the given input and tries to find appropriate replacement words in the language the model is translating.
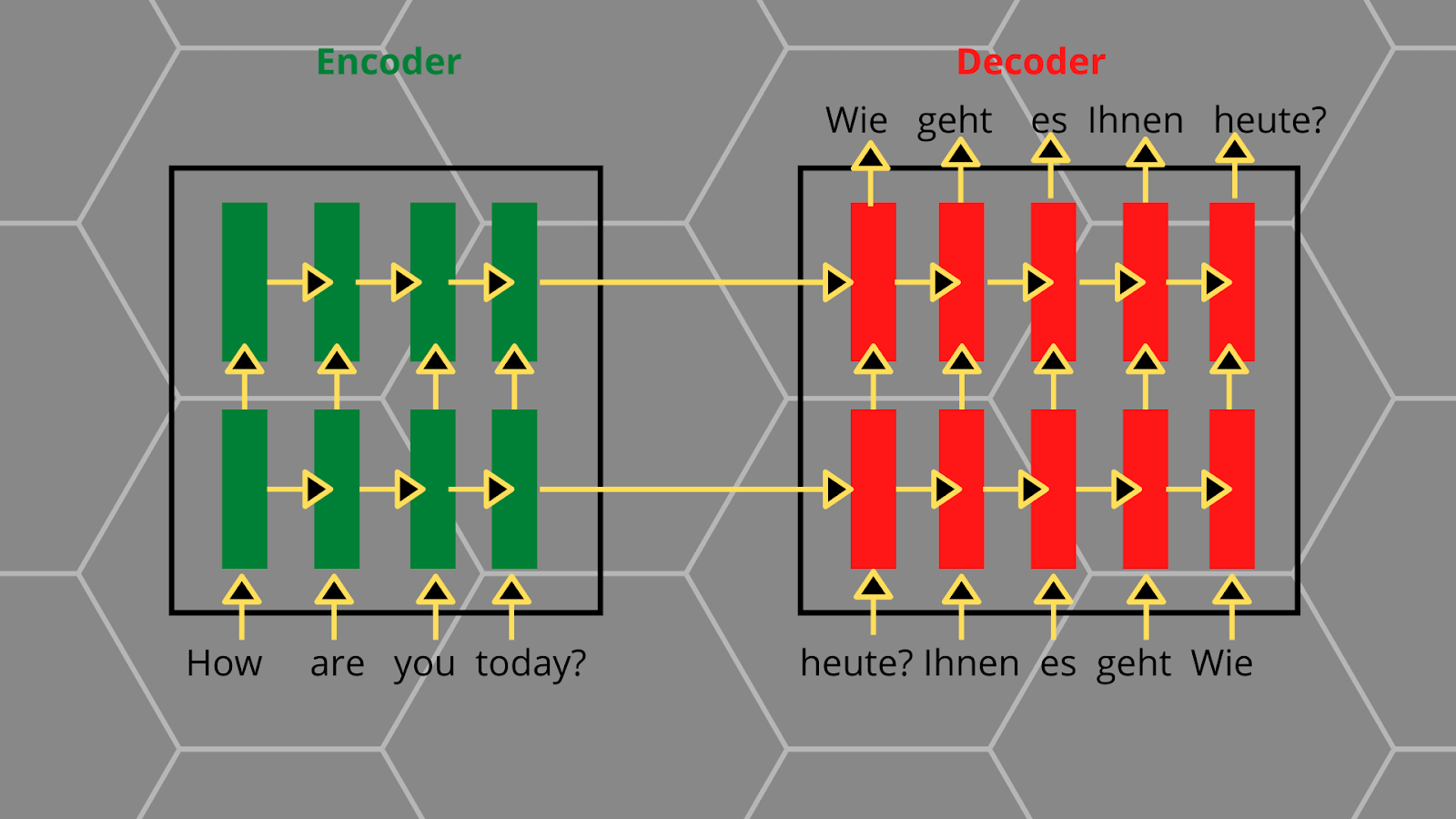
Encoder and Decoder are nothing but 2 LSTM-RNN models whose functions are change then.
however, Encoder works with sequence-to-vector encoding, whereas the Decoder works with vector-to-sequence decoding.
Data Preparation for NMT
The dataset contains language translation pairs in the format.
Something like this “May I borrow this book? ¿Puedo tomar prestado este libro?”
Here’s a link to get pre-formatted datasets “http://www.manythings.org/anki/ ”.
thus, The above link has many zip packages which can be used for NMT models.
After downloading the dataset from link above, some steps are need to prepare the data:
- Add a start and end token to each sentence, which looks like <SOS> and <EOS>.
- Cleaning the sentences by removing special characters and unnecessary characters.
- Create a word index and inverted word index (dictionaries mapping from word → id and id → word).
- Padding of each sentence is must to match the max length sentence.
Implementation of Neural Machine Translation using Attention
The NMT models trained before Attention were using seq2seq structure. This structure had an issue known as Fixed Encoder Representation which caused a bottleneck at the output vector.
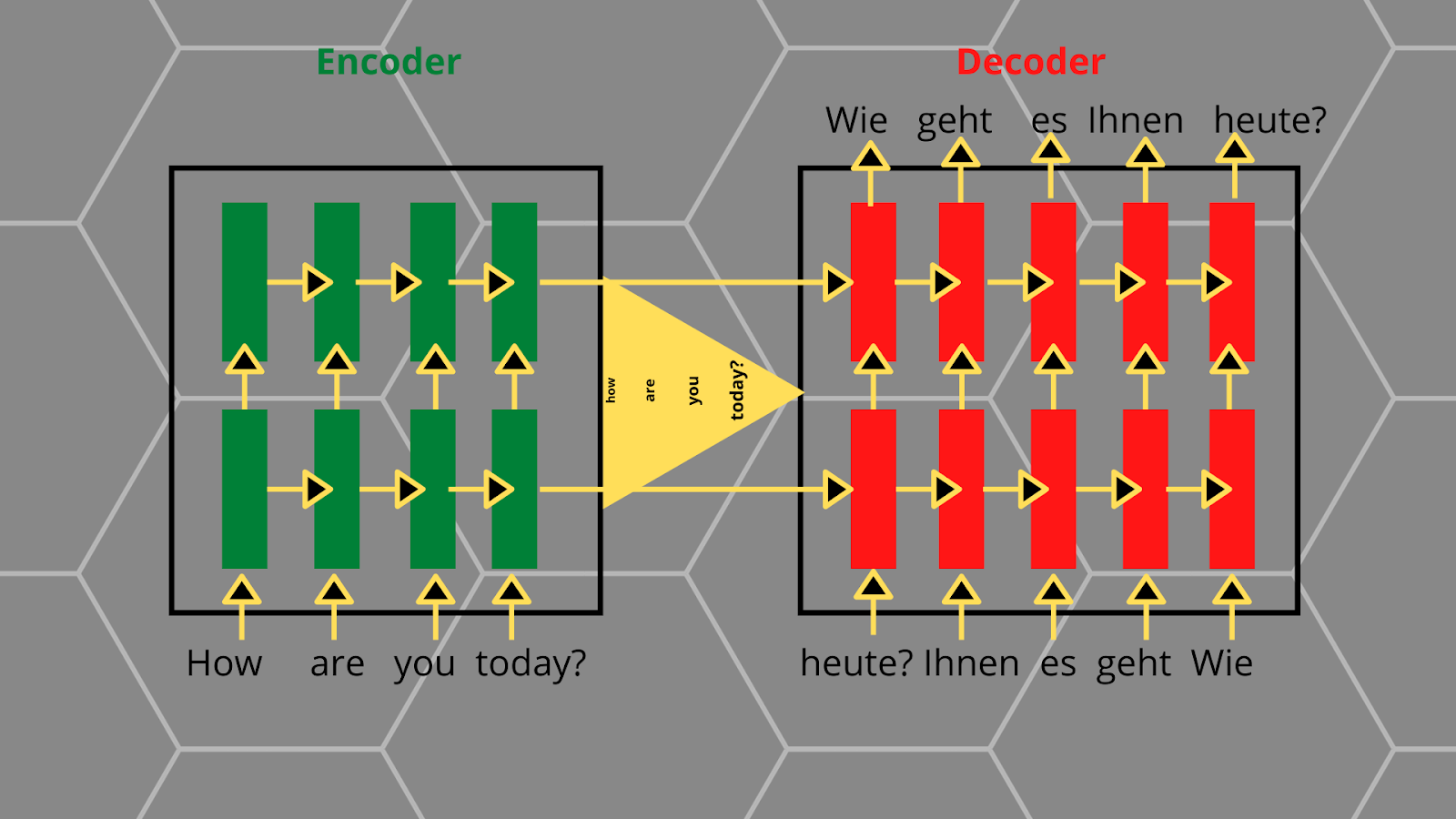
Here you can see the latest word gets higher priority than the previous ones, which makes the NMT model hard to maintain the relationship between these words. Here’s where the working of attention comes in.
What is Attention?
Attention as the name says, it allows the model to “Focus on important parts” of the sentence.
The term “Attention” was initially introduced in the paper Neural Machine Translation by Jointly Learning to Align and Translate whose sole purpose was to address the fixed representation problem.
Attention mechanism is a part of a neural network which makes the network focus only on important data. At each decoder step, it decides which parts of the sentence are more important. So the encoder does not have to get all the tokens in the sentence into a single vector.

As seen earlier the encoder and decoder part is the same, the output of the decoder is sent to the softmax activation function to get final results of the NMT model.
There are various computations that take part in calculation of each attention value based on the important parts of the sentence.
Training the NMT model
Here we’ll be using the encoder and the decoder structure to create the NMT model with extra addition of attention.

In this example, we are translating English tokens to German tokens. The input is represented by 0, and the target is represented by 1. One copy of the input tokens is fed into the inputs encoder to be transformed into the key and value vectors. Another copy of the target tokens goes into the pre-attention decoder. An important note here, the pre-attention decoder is not the decoder what we saw before, which produces the decoded outputs.
The pre-attention decoder is transforming the prediction targets into various vector spaces called the query vectors. To be even more specific, the pre-attention decoder takes the target tokens and shifts them one place to the right. This is where the teacher forcing takes place.
however, That way when we predict, we can just feed in the correct target word (i.e. teacher forcing).
The input encoder gives you the keys and values. Once you have the queries, keys, and values, you can compute the attention. After getting the output of your attention layer, the residual block adds the queries generated in the pre-attention decoder to the results of the attention layer.
Then activations go to the second phase, with the mask that was previously created. We are now in the top right corner of the image. The Select is use to drop the mask. It takes the activations from the attention layer or the 0, and the second copy of the target tokens, or the 2. These are the true targets that the decoder needs to compare against the predictions.
Finally, you just run everything through a decoder LSTM /dense layer or a simple linear layer with your target’s vocab size. This gives your output the right size. We use log softmax to compute the probabilities. The true target tokens are still hanging out here, and we’ll pass it along with the log probabilities to be match against the predictions.
Link to the full code on NMT will be given in the references section.
Conclusion:
Working on NMT models is kind of tricky as the computation happening behind need to be understood first to improve the model performance.
References:
- NMT paper Neural Machine Translation by Jointly Learning to Align and Translate.
- Here’s a link to get datasets “http://www.manythings.org/anki/ ”.
- Code link “https://www.tensorflow.org/tutorials/text/
- NMT models in detail “https://lena-voita.github.io/nlp_course/
seq2seq_and_attention.html#attention_intro”
Written By: Pushpraj Maraje
Reviewed By: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs