

Why and how to predict Hypothesis Space And Inductive Bias?
Predictions have become very essential in our lives today. From predicting weather to predicting the status of stock in finance, these predictions play an important role. But how do we actually predict? What are the necessary tools required for successful prediction?
The answer is that while making predictions, we need or are given examples or data. The examples are of the form (x̂,y), where for a particular instance, x̂ comprises the values of different features of that instance and y is the value of the output attribute. Features refer to properties that describe each instance. Another way of thinking this is (x̂, f(x̂)). So this way of thinking is based on the fact that the output of an instance is a function of the input feature vector. This is the function we are trying to learn in machine learning.
Inductive Bias
Consider the two types of supervised learning problems: Classification and Regression, which depends on output attribute type (that is discrete valued or continuous valued). In Classification type, this f(x̂), is discrete while in regression f(x̂) is continuous. Apart from classification and Regression, in some cases, we may want to determine the probability of a particular value of y. So in cases of probability estimation, our f(x̂) is the probability of x̂. So these are the types of Inductive Bias problems we are trying to look at.
We call this Inductive Bias because we are given some data and we are trying to do induction, to try identify a function which can explain the data. Unless we can see all the instances (all the possible data points) or we make some restrictive assumptions about the language in which the hypothesis is expressed or some bias, this problem is not well defined. Therefore it is called an Inductive Bias.
What is feature Space?
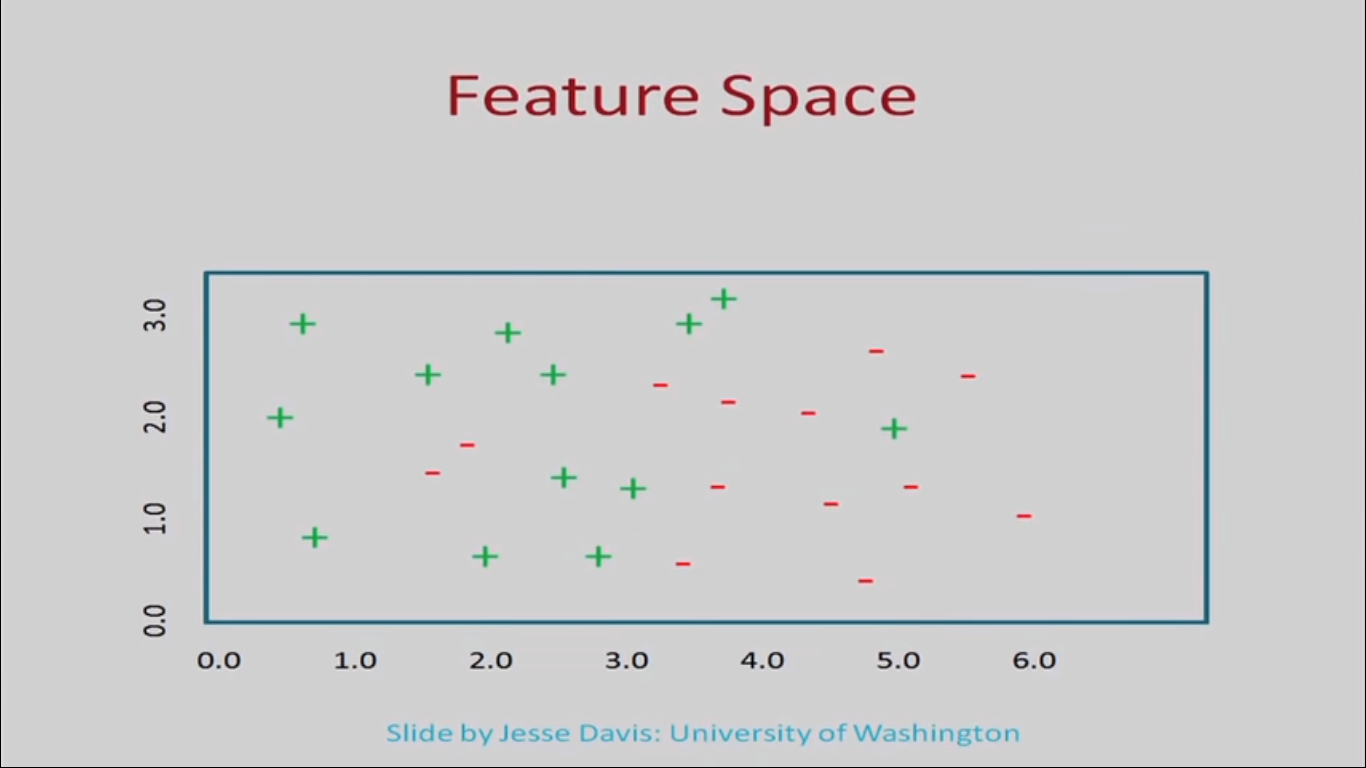
FIG 1: Source: Slide By Jesse Davis, University Of Washington
We know that features refer to properties that describe each instance. Often we have multiple features which we call a feature vector. For example for a particular task we may be describing all the instances with 10 features. So the feature vector will be a 1 dimensional vector of size 10. Based on this we can define a feature space. Consider for simplicity that we have 2 features and let’s call them x1 and x2. These features define a two dimensional space. So the space defined by the features is known as feature space. For n features we can define n dimensional space.
Example situation
Let us look at a classification problem. Let’s assume that it is a 2 class classification problem, that is we are provide with a number of instances or examples. Some of them belong to class 1 the others belong to class 2.
Also we are provide with a training set which comprises a subset some of them are mark class 1 and some of them are mark class 2 and we can say that class 1 is positive and class 2 is negative. We can map different points in the feature space as shown in the figure 1.
Our objective is for the function to know/predict if a new instance is provide, whether this instance will be positive or negative. The function should separate the positive from negative with the help of a curve or a line. Depending upon the separating line we can determine if the new instance is positive or negative.
Let’s again consider figure 1. Let’s mark some test points(the question mark points in figure 2). What we have to determine is the class of the points (positive or negative) in the prediction problem. In order to answer the prediction problem we have to come up with a curve (that is a function). Let’s consider this function marked in the pink line. According to this case of the function, we can say that the test points to the right would be negative (based on the trends) and to the left would be positive.
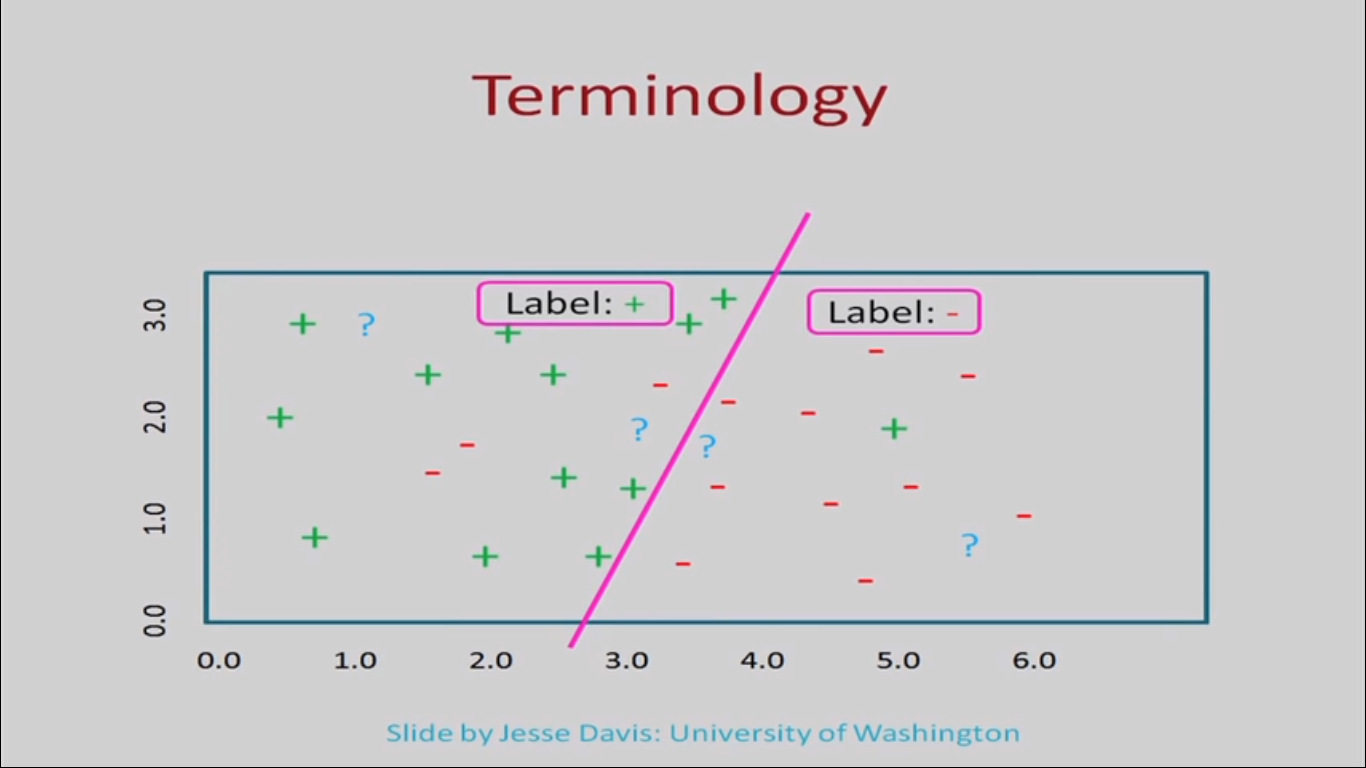
FIG 2: Source: Slide by Jesse Davis, University of Washington
We can consider any curve. But that curve must appropriately predict(not necessarily 100%) the class of the task point. This function (pink line) is also refer hypothesis and we use this hypothesis for predictions.
Hypothesis Space
Instead of this particular line, we could have used other functions for hypothesis. As shown in figure 3 all these are the possible functions which we could have found. The set involving all such legal functions (that are possible) defines the hypothesis space. In a particular learning problem we first define the hypothesis space (the class of the function we are going to consider), then given the data points we try to come up with the best hypothesis.
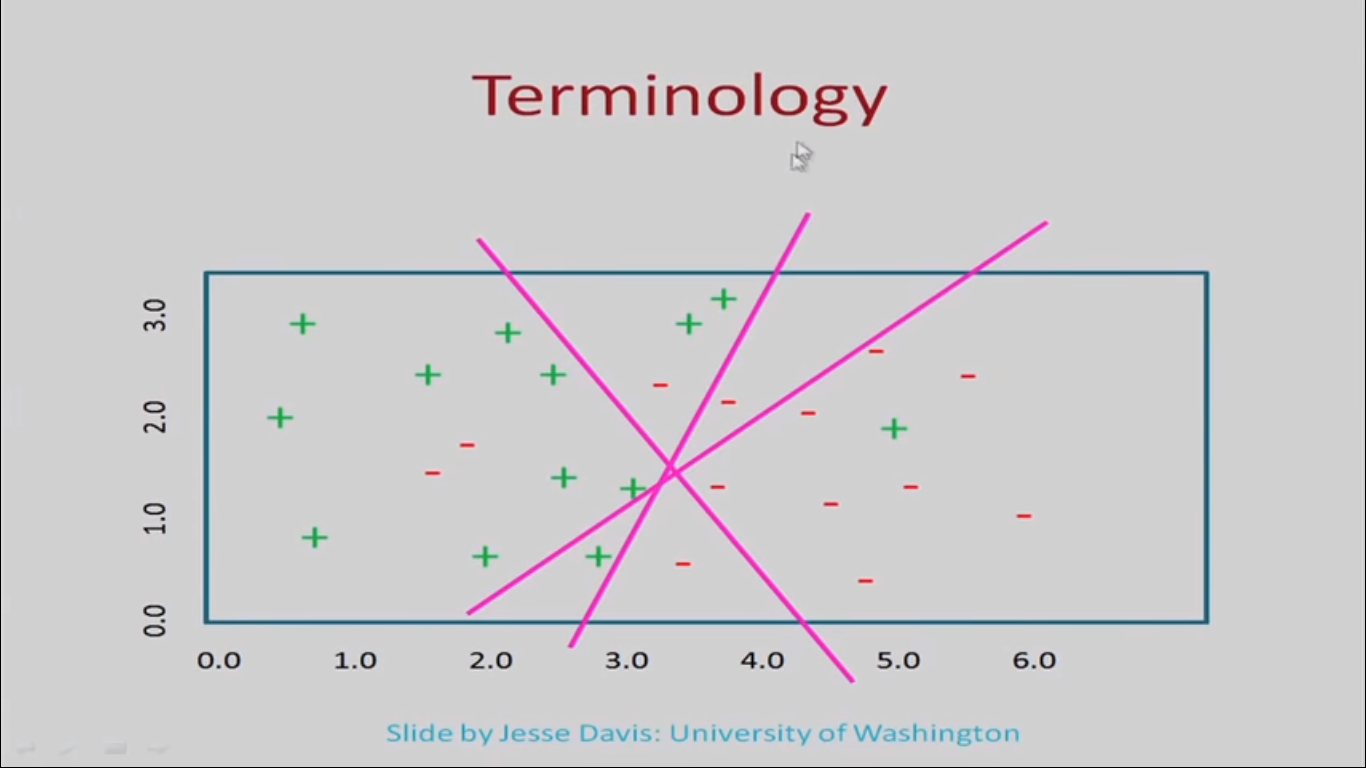
FIG 3:Source: Slide by Jesse Davis, University of Washington
Other Decision Curves
Inductive learning is a way to predict using hypothesis space about the class of the task points. Various types of representation have been considered for making predictions. Some examples are linear(discussed above), which acts as a discriminator between two classes. Another structure which is used is a decision tree. A decision tree is a tree, where at every node we take a decision based on the value of the attribute. Based on this we go to different branches of the tree. Every leaf node is labelled according to the value of ‘y’. Other representations are multivariate representation, neural networks, single layer perceptron(the basic unit of the neural network) and multi-layer perceptron.
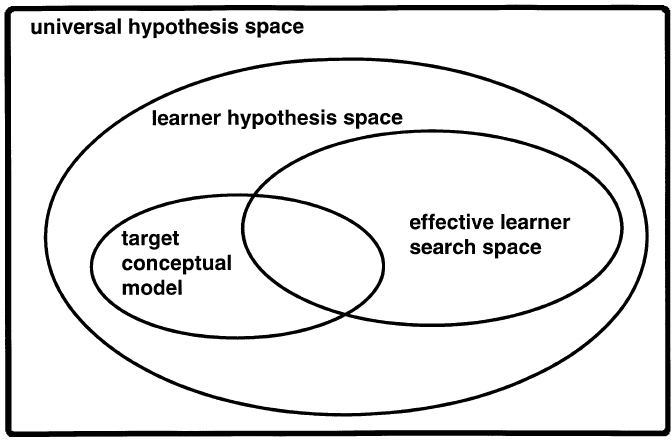
SOURCE: https://www.researchgate.net/figure/The-different-regions-in-hypothesis-space-representing-the-knowledge-of-the-learner_fig3_227155069
Hypothesis is describe by the features and language that is select. From this set, the learning algorithm will pick a hypothesis. A hypothesis space is represent by ‘H’ and the learning algorithm outputs h ∈ H. ‘h’ represents the chosen hypothesis. H depends on data points that are select and also on certain types of restrictions (bias) that we have imposed. Thus supervised learning can be thought of as a device which explores the hypothesis space in order to find out one of the hypothesis which satisfies the given criteria.
An example to conclude
Let’s consider an example for further understanding. Let’s take the features which are boolean that is x1, x2, x3, x4 are 4 features which are boolean. Thus x1 can take either 1(=T) or 0(=F). Similarly x2,x3,x4 can take either 0 or 1 as shown.
| X1 | X2 | X3 | X4 |
| 1 | 1 | 1 | 1 |
| 0 | 0 | 0 | 0 |
Thus the possible instances will be 16(=24).How many boolean functions are possible? The function will classify some of the points as positive, others negative out of the 16 points. Thus the number of functions is the number of possible subsets of the 16 instances. So the subsets possible are (216). This can be generalise to n boolean features too. So instead of 4 boolean features if we have n boolean features then the number of possible instances is 2n and the number of possible functions will be 2(2^n).
As it can be seen the hypothesis space is gigantic in size and it is not possible to look at every hypothesis individually in order to select the best hypothesis. So one puts restrictions in the hypothesis space to consider only specific hypothesis space. These restrictions are also refer bias and they are of many types.
An example is Occam’s Razor which states that the simplest consistent hypothesis about the target function is the best and should be considered as the hypothesis. Other types of bias include Minimum description length and maximum margin bias. The choice of bias depends on the requirements and the available data sets.
Written By: Aryaman Dubey
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs