
YOLO stands for You Only Look Once. The current version of YOLO is YOLO version 5. It is completely written in PyTorch.
The most important thing is object detection Using YOLO5 by creating a proper custom dataset.
Object Detection Using YOLO5
Step 1: Let’s learn how to customize your dataset.
Firstly, We’ll have to download the dataset.

Step 2: Then, we’ll import all the libraries we’ll need in the entire code.
urlib -> for image download
cv2 -> for image transformation

Step 3: Now, we’ll create an array named clothing.
Then, open the file and for each line, we are going to append it into our array clothing.

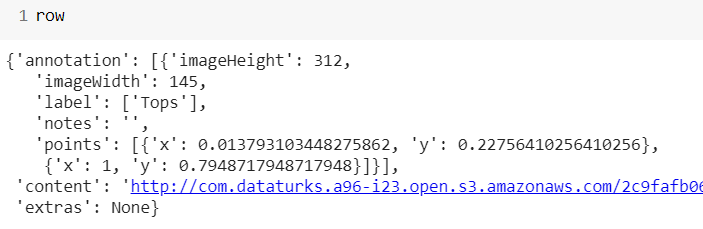
Single annotation looks like clothing[0]. It will display an annotation whose length is greater than 1.
In the output part for this code, x and y are not in pixels, they are in percentage, and below that we the link for the image.

Step 4: Now, again creating an array of name categories.
Iterate all annotations. Then, extend the categories with labels for each annotation. As you can see above, labels are actually in the array format, so we are converting it into a list. Then, display all the categories that we have.

Step 5: We’ll now split the data into train and validation sets.
Below, we get the number of training samples as 453 and the number of validating example as 51

Step 6: We are now going to take the image and download it using urllib.request.urlopen.
Then, we’ll convert the image into RGB format and then save it in JPEG format. By doing this we’ll have that image on our local machine.

Step 7: Next, we have to use OpenCV to read the image.
thus, recall we need to convert this image into RGB format because OpenCV needs the image in that format. With the help of the shape function, we will get the output as width, height, number of colour channels.

Step 8: Now, we’ll apply annotation for this image and then we’ll iterate over all the annotation and all the labels.
And right there we’ll get the width and height of the image. Point coordinates are normalized in values between 0 and 1.
x1, y1 are real pixel coordinates based on the image width and image height. Then we’ll annotate rectangles with the help of cv.rectangle. Then, we’ll write a function to label those rectangles named cv2.putText.
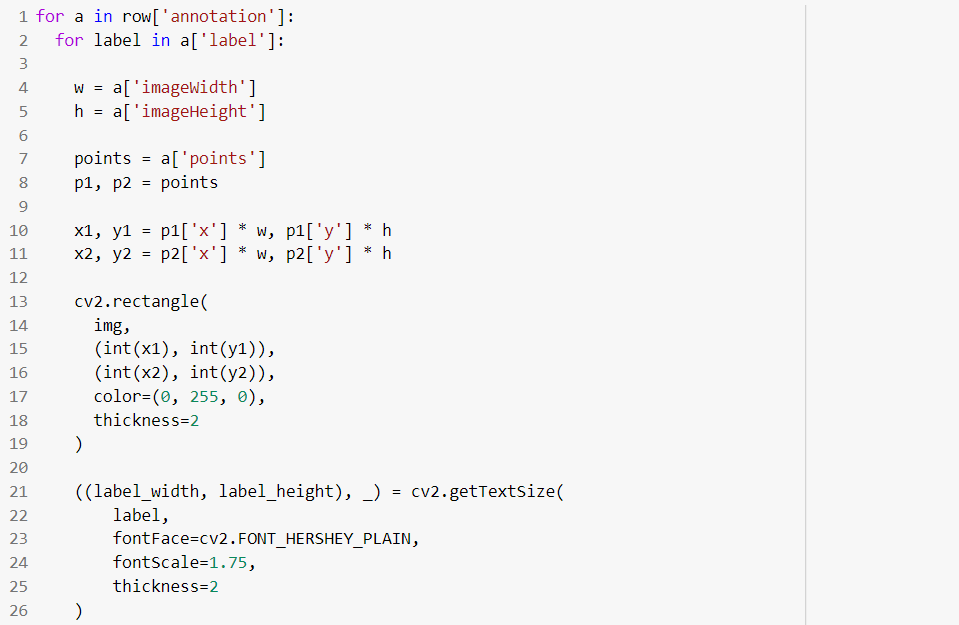

Here’s our image with a labelled rectangle.

For the YOLO custom object prediction model, we need a specific type of dataset. In this, we require an image dataset folder and label dataset folder of both train and validation datasets. In the label folder, it contains the annotation of the respective folder. In the code given below, we’ll convert the available dataset to the required dataset format. The code is self-explanatory.



Step 9: Now, we’ll look at how we can fine-tune YOLO version 5 using our custom dataset.
then, see how it performs on the image that we have in our test set. Get the GitHub repo and clone it.

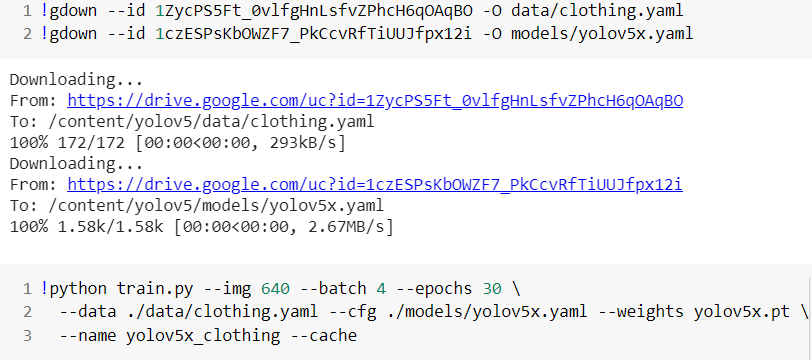
Step 10: Now, we’ll enter the directory and check out specific commits.
Below this part of the code, we’ll specify the maximum image width as 640 pixels, then we specify the number of epochs, then set the config for the dataset, and then we are going to get the config of the model. Another important thing is that we are going to pass the weights then the name of the model. After this part of the model, the training of the model begins.
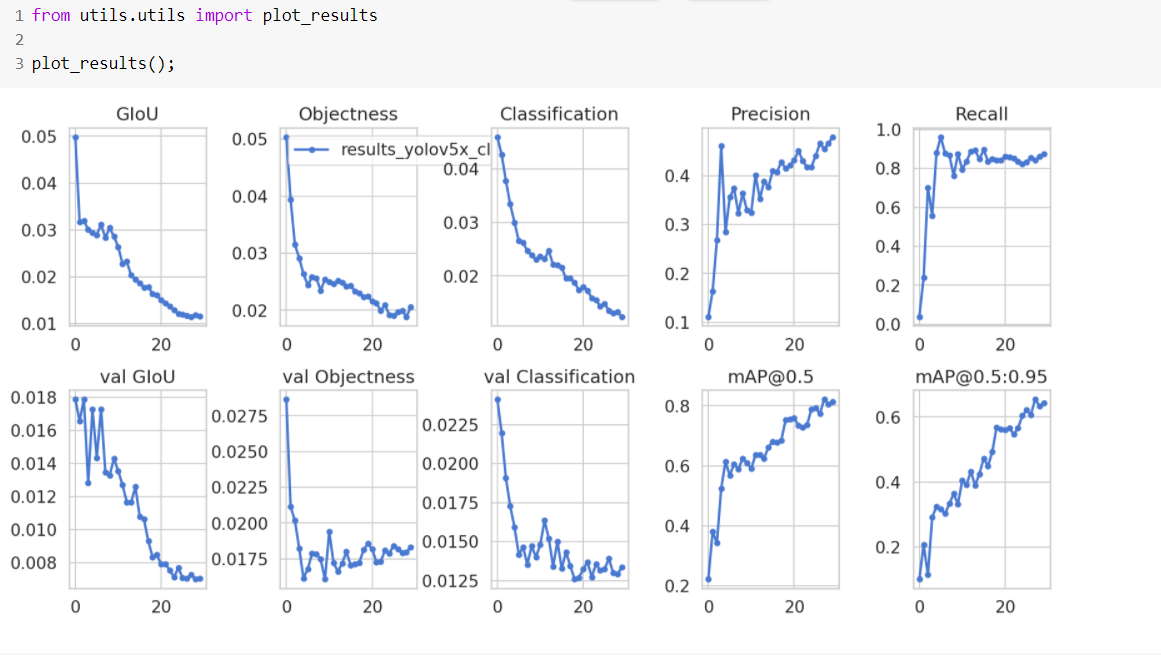
Step 11: Now, we’ll visualize our dataset.
step 12: Now, we’ll select 50images from the validation set and copy those into inference images.


Using the globe library we have defined the path of random 50 images from the inference dataset in the form of a grid. The preview is given below.

Written By: Ketki Kinkar
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs