
Handling Categorical Features
While we work on huge data we encounter Handling categorical features in many datasets. These generally include different categories or levels associated with the observation, which is strings and should be converted to the computer to process them. Hence these are converted into integers.
They are mainly 6 techniques to handle categorical data :
- One hot encoding
- One hot encoding with many features
- Ordinal encoding
- Count or Frequency encoding
- Mean encoding
- Target guided encoding
One hot encoding
It is a technique where every category is consider as a feature and assigns 1 or 0. For N features there are N rows. This is a simple way to handle categorical data. The only disadvantage of using categorical data is that it has a “curse of dimensionality ” which means that there will be an increase in dimensions of data as the number of features increases. In python, we use get_dummies function.

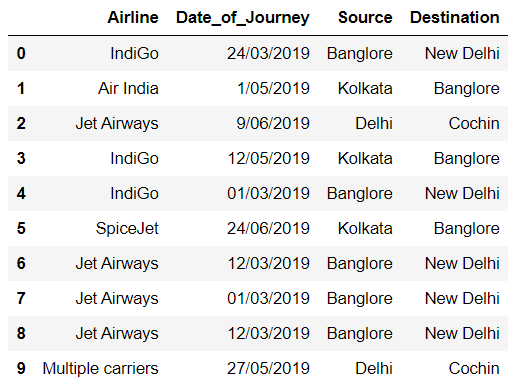
After applying one-hot encoding to the first column, single columns are divide into many columns.

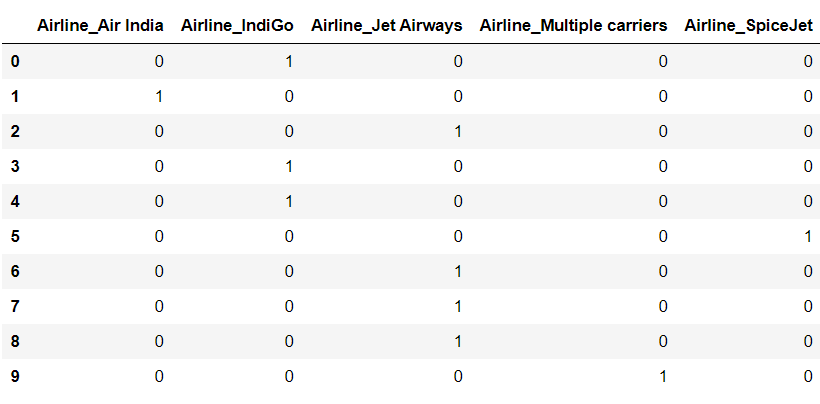
As the number of categories in a column increases, the number of columns increases while one hot encoding which makes data complex hence we can limit columns.
One hot encoding | Handling Categorical Data
It is an alternative way when the number of categories in the column are more. This is similar to one-hot encoding but the only difference is that we remove categories which are least repeat and perform one-hot encoding. It is most efficient when there are more categories.
For this, we first sort categories based on the frequency. Then we remove the least frequent category. Behind the scene, removed categories are consider as a single feature.
So first sort categories according to frequency.


Now, we remove the least repeated columns and perform one hot-encoding manually.


Here “SpiceJet” and “Multiple carriers” don’t have a separate column as they are least repeated.
While applying machine learning algorithms both come into a single category.
Ordinal encoding
It is a simple technique use when there are very few categories in a column. We simply assign a number to each category through a dictionary in python. We put the category as key and number in as the value. And we use map function to replace categories with a number.


Count or Frequency encoding | Handling Categorical Data
Count encoding or feature encoding is a technique where we replace categories with frequency in a column. This method is easy to implement and with help of this, we can assign weights to a category. we are not increasing feature space. But the only disadvantage with this method is that, if two categories have the same count then they are consider as a single category. This technique is use when we need to represent.


Mean encoding
Mean encoding is a complex way of encoding which is use to encode based on the target. Which means that it encoded based on the independent column. This is similar to count frequency. The only difference is that the independent feature of a data is use. We use this technique when we use binary classification where the output is either 0 or 1.
Mean of a category is label. This gives weights and is use for classification. There are two disadvantages in implementing this technique. Firstly if there are 2 categories with the same mean then they are consider as a single category. Another disadvantage of this technique is that we can’t implement regression.

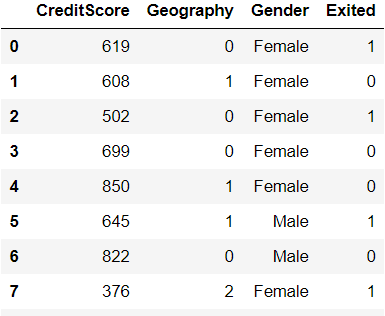
Here we used unique() to check how many distinct categories are present in the Geography column.Then we grouped by category and took the mean of target column.


categories are then labeled with their means of target using map function.


Target guided encoding
This is similar to mean encoding but the only difference is that it is used to means are arranged in ascending order and then enumerated. We use this technique when we use binary classification where the output is either 0 or 1.Mean of a category is labelled. This gives weights and is used for classification.There are two disadvantages in implementing this technique. Firstly if there are 2 categories with the same mean then they are considered as a single category. Another disadvantage of this technique is that we can’t implement regression.
The enumerated data is in the form of a dictionary, then the labels are changed using the map function.

Conclusion
We conclude that each and every encoding technique is used in its own purpose.
One hot encoding gives best with few features, we can limit dimensions according to frequency. With ordinal encoding, we can give our own labels. Using count frequency, we use frequency to encode a category. Through mean encoding, we calculate the mean of the target variable. With target guided encoding, we encode according to ascending order of mean.
written by: Abhishek Vardhan
reviewed by: shivani yadav
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs