
Feature Scaling is an important data pre-processing step before going ahead with building a machine learning model. In most cases, the performance of a machine learning model varies significantly depending upon whether the data has been scaled or not. The objective of feature scaling is to enclose all features in a common boundary without losing information. The three things that define the features are the units, magnitude, and range.
If we do not scale the features, the model prefers features with more magnitude without considering the units. For example, a model will give more weightage to 100cm over 2m, even though the latter is greater in length.
NEED FOR FEATURE SCALING
Consider a dataset wherein based on the Height and Gender we determine the Weight. The Height can be in inches or centimeters while the Gender will be 1 and 0 for male and female, respectively. Now, there is no comparable relationship between the gender and height attributes as the two features are independent of each other.
Consequently, by default, a machine learning model will assume that the Height feature will have more significance than Gender based on its magnitude. In such cases, it is necessary to bring all features to the same level.

Let’s work on the red wine quality dataset for further discussion.

We now apply Linear Regression on this raw unscaled data to give the Root Mean Square Error and the R2 score of the model.

NORMALIZATION
Normalization is a process that scales the feature values such that they range between 0 to 1. Usually, Min-Max scaling is used for Normalization.
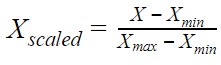
Xmaxis the maximum value in the dataset and Xminis the minimum value in the dataset. When the value of X is maximum the equation gives 1 and when the value of X is minimum we get 0. This gives us our range terminals of 0 and 1.
Using MinMax Scaler on the red wine dataset, we get an RMSE value of 0.63, which demonstrates the favorable effect of scaling.
STANDARDIZATION
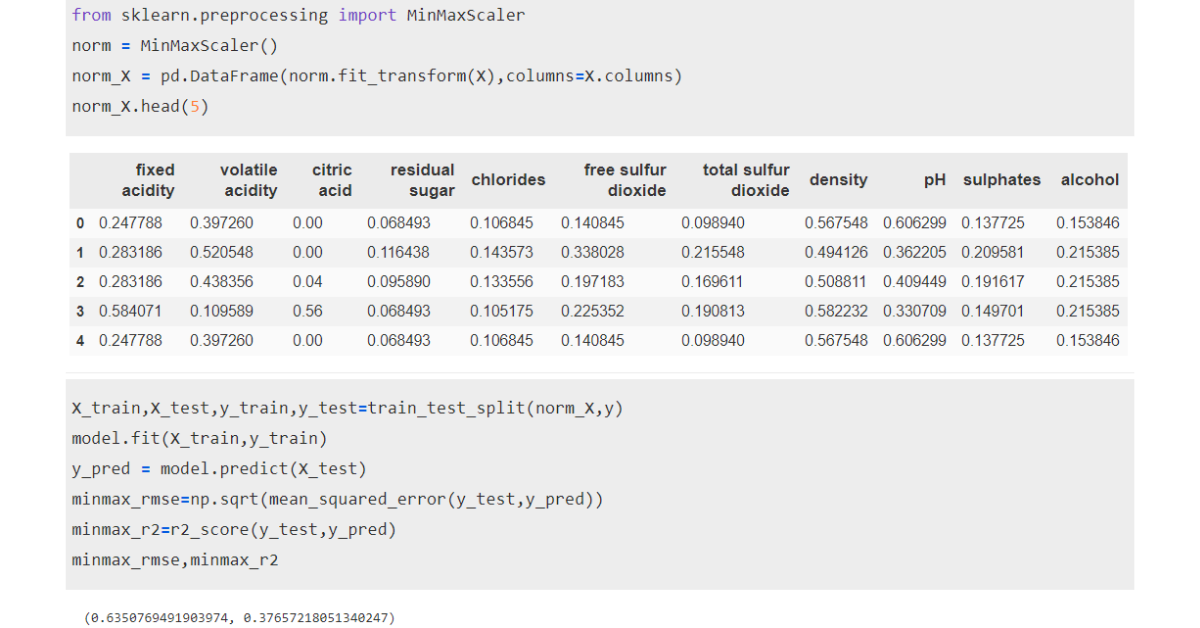
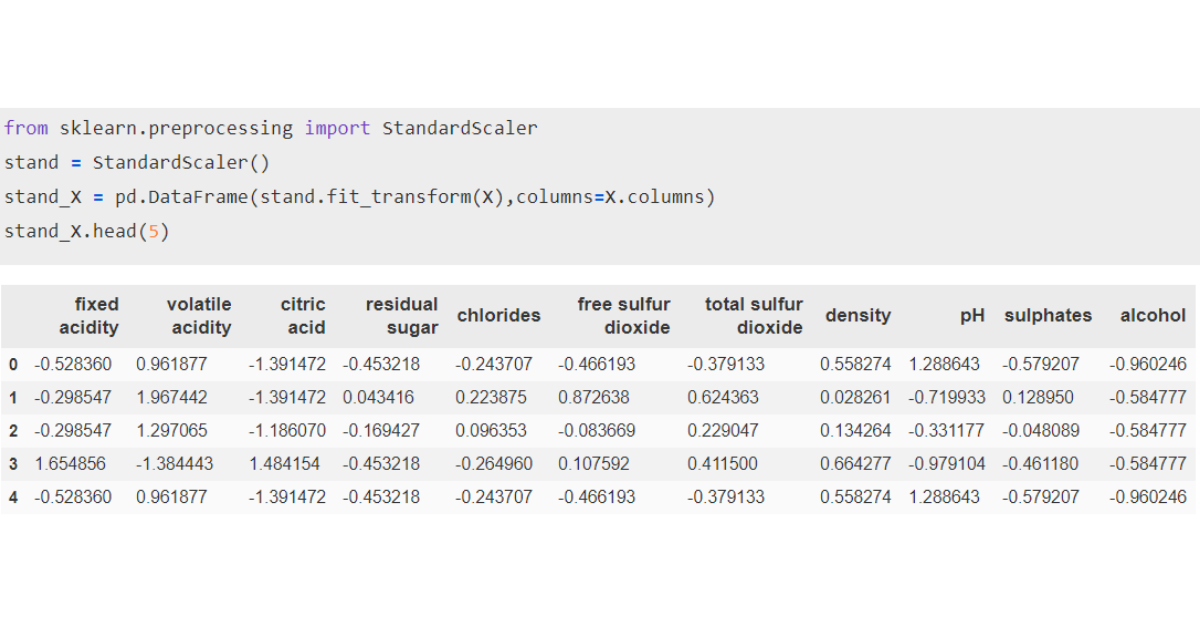
Standardization is a process that scales the feature values to achieve a distribution with a mean equal to 0 and a standard deviation of 1. This is also called Z-score normalization.
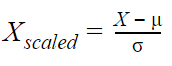
is the mean and is the standard deviation. The range for scaled values may vary. For standardization, we use Standard Scaling from scikit-learn.
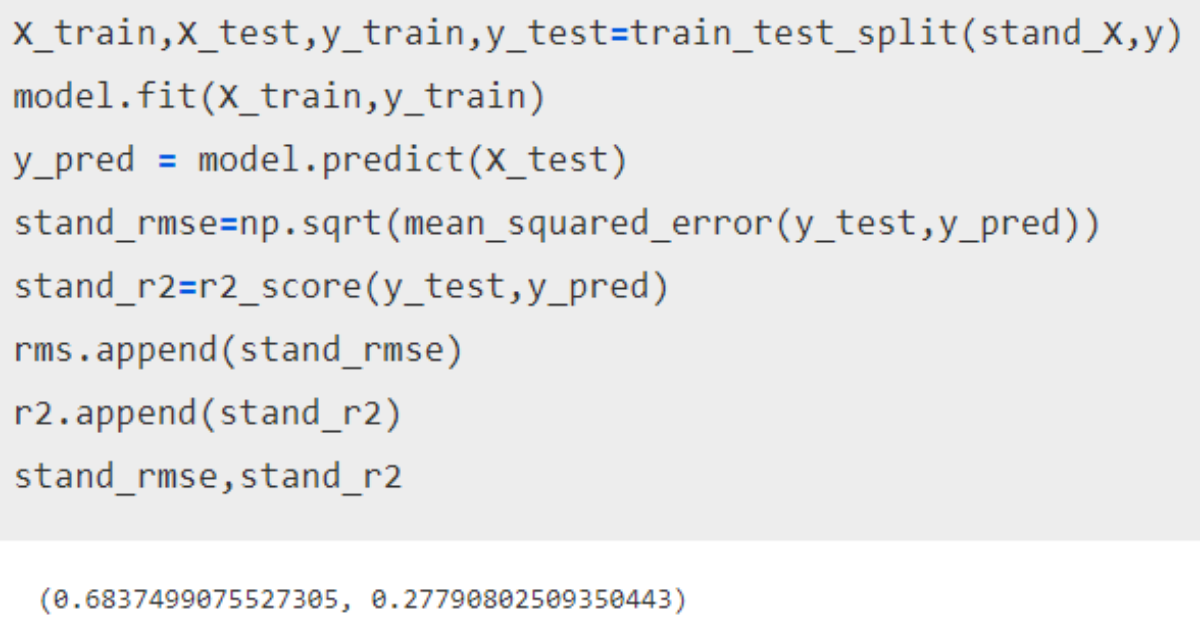
Standardizing the red wine dataset, we get an RMSE value of 0.68, which is better than unscaled data.
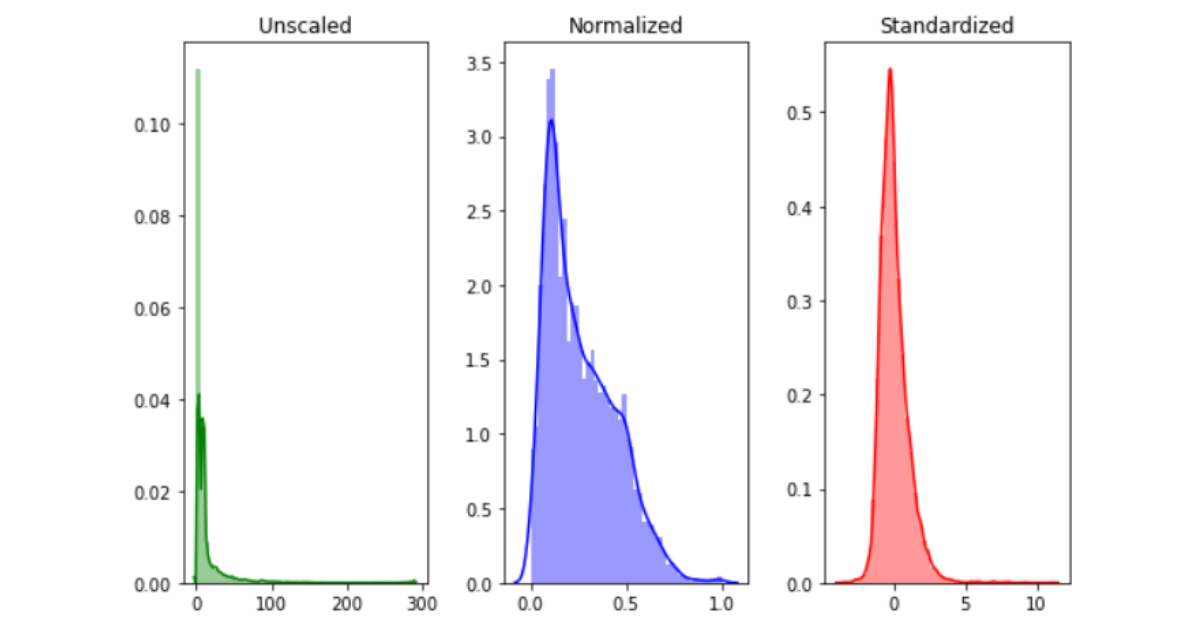
On visualizing the effect of scaling on the dataset, we can clearly see that feature scaling significantly reduces the range of feature values.
EFFECT ON MACHINE LEARNING ALGORITHMS
Feature scaling has the ability to dramatically increase the accuracy of a model. It works extremely well on some algorithms but has no effect on others. Let’s take a look at some algorithms.
Algorithms that use gradient descent (linear regression, logistic regression, and neural network) along with algorithms that use euclidean distance (K Nearest Neighbors, K-Means clustering, and Support Vector Machine) require the features to be scaled.
For algorithms that use gradient descent, the objective is to find a smooth curve to the global minima. However, if the features are independent of each other, the difference in the range of values will cause the step-size to vary. As a result, the curve will be far from smooth.
Algorithms that use Euclidean distance are most sensitive to the range of features. This is because, if the range is huge, the distance between data points will be huge as well, which in turn will be detrimental to the model’s performance.
Algorithms like Decision Trees, Random Forest, Gradient Boosting, etc, are not significantly affected by feature scaling since the trees in these algorithms are constructed based on conditions and are not dependent on the range of values. Algorithms like Linear Discriminant Analysis and Naive Bayes also do not require feature scaling.
DIFFERENT SCALERS | FEATURE SCALING
We implemented and understood Min-Max Scaler and Standard Scaler. Now, let’s take a brief look at some other scalers.
1. Max Abs Scaler
This method scales to give only positive values by scaling each feature by its maximum absolute value. This scaler scales each feature value to give the maximal absolute value as 1.0.

2. Robust Scaler
The Robust Scaler is named such because it is less sensitive to outliers. It is much similar to Min-Max Scaler, but instead of the maximum and minimum values, it makes use of the interquartile range( 1st and 3rd Quartile ). It has no specific range, just like the standard scaler.


3. Quantile Transformer Scaler
Quantile Transformer is another scaling method that is less sensitive to outliers. The features, in this method, are transformed into uniform or normal distribution.

4. Power Transformer Scaler
Power Transformer Scaler is used to transform the data into gaussian-like distribution. The power transformer uses maximum likelihood estimation to minimize skewness and stabilize the variance.

CONCLUSION

There is no given method as to which scaling technique one should choose; it depends on the data and algorithm. In this case, MinMax Scaler gives the best RMSE and R2 score. We can see from the table that feature scaling gives better model performance over unscaled features.
Hopefully, this article presents an informative overview to get started with feature scaling. Even though it might seem insignificant, feature scaling is an essential step in machine learning data preprocessing.
written by: Vishva Desai
reviewed by: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs