
Deep Learning is an iterative way of training the machine. Like any iterative or cyclic process, DL involves three main components namely, formulate- training the NN, test the model, and evaluate the model. In other words, iteration in DL indicates the number of times the hyperparameters are update upon. Hyperparameters are the core entities in any DL models. The best combination of various permutations of the hyperparameters must be set up to ensure accurate results.
Training deep learning models takes a long time. In order to achieve the best training efficiency, the performance of the optimization algorithm becomes an important factor. Deep learning algorithms require optimization in different circumstances but training the neural network is said to be the most difficult task for the following reasons:
- Time-consuming: In real-time, training a single neural network instance on several machines will take days to months in real-time scenarios.
- Expensive: Training the NN is expensive
For the above-said reasons, specialized optimization techniques are in need.
Existing Loss function as Optimization and its limitation
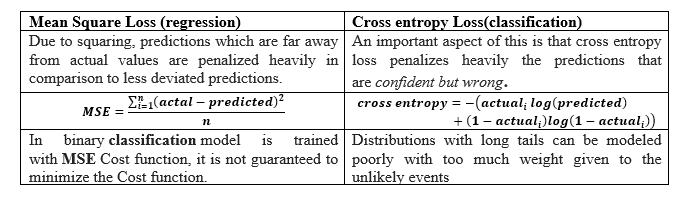
A loss function is in use for neural network models to optimize the parameter values. Loss function can be classified into two broad categories as shown.

The following table compares the frequently used loss function in deep learning for regression and classification tasks respectively.
Loss function can also be define as an algorithm that converts concepts to practical. So, it is a transformation function on neural networks that converts multiplication of matrices into deep learning. The advanced loss function in deep learning models is in use for specific purposes.
| Advanced Loss Function | Task |
| Robust Bi Tempered Logistic Loss | To train a robust model to noisy data |
| Minimax loss for GANs | To minimize generator’s loss and maximize discriminators’ lossIt is used as an optimization strategy in two-player turn-based games for minimizing the loss or cost function |
| Perpetual Loss function | This is a feed-forward CNN which are trained when an input image is transformed into an output imageHigh-quality images can be generated by defining and optimizing loss functions based on high-level features |
| Loss function(Boundary) for the segmentation of highly unbalanced classes | The distance metric is used on the outline spaces or shapes instead of regions.It offers evidence of data that is corresponding to regional losses. |
Advanced Activation Functions
Some of the advanced activation functions also use different layers of the DNNs are Parametric ReLU and ELU.
Parametric ReLU
Parametric ReLU is a generalization of Leaky ReLU, where the slope for negative inputs is not predetermine, rather it is consider as a learnable parameter. Formally, it is define as,
y=f(x)=x,x>0and ax,x0
where the coefficient ‘a’ decides the slope of the negative part.

The neural network should also learn the best value of itself along with the rest of the model. Thus, when a=0, the function becomes ordinary ReLU. When a small and constant value, usually 0.01, becomes LReLU.
Exponential Linear Unit
Exponential Linear Unit or ELU is similar to Leaky ReLU, but instead of a straight line, it uses a logarithmic curve for all the negative weighted sum of inputs as shown below

Similar to LReLU and PReLU, thus the negative values of ELU move the mean of the activations closer to zero. When the mean of the activations is closer to zero, learning is usually faster.
however, A significant improvement over LReLUs and PReLUs is that, for smaller arguments, an ELU saturates to a negative value. This implies a smaller derivative which decreases the variation and the information that is pass on to the subsequent layer. This makes an ELU noise-robust as well as low-complex.
written by: Ganesh Hari
reviewed by: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs