

Before feeding the data into the machine learning model, this is the most necessary process. According to the model, the reason behind the data set demand to distinct and specific so that we have to find out the require features of that information. The process of data preparation provides a method through which we can prepare data for project definition and also for project evaluation of Machine Learning algorithms.
The very purpose of the Data Preparation phase is to turn the data into the best machine learning format, including three main phases: Data Cleansing, Data Transformation, and Feature Engineering. High-Quality data is more essential for complex algorithms, so this is an incredibly important phase and should not be skipped.
A quality data preparation method will include:
- Data Cleaning
- Data Transformation
- Feature Engineering
- Granularity Management
- Sensitivity Management
- Locality Management
1. Data Cleaning
It is very important to clean up the data after collecting the data and make it appropriate for the Machine Learning model. This involves solving issues such as outliers, inconsistency, missing values, erroneous, skewed, and trends. It is very important to clean the data as the model only learns from that data, so if we feed inconsistent, suitable data to model it will only return waste, so it is necessary to ensure that the data does not contain any unseen problem.
Data cleaning includes:
- Handling Missing Values
- Handling outliers
- Dropping duplicate values
- Grouping sparse class
2. Data Transformation
Data Transformation is a process where the raw data is transform from one form to another. For data integration and data management, it is compulsory. We can change the data types during data transformation, clear the data by removing null values or duplicate values, and get enriched data that depends on the model requirements. however, It enables us to perform data mapping that determines how to map, modify, funnel, aggregate, and join individual features.
Data Transformation process will includes :
- Managing skewed data
- Scaling the data
- Categorical encoding
- Bias mitigation
3. Feature Engineering in Data Preparation
Before discussing Feature engineering, I want to discuss what a Feature is. In the context of Machine Learning, we all know, To train any machine model, we need some input data and some output data. thus, This data is mainly in the form of rows and columns (Structured Data). so, These columns are known as Features. A Machine Learning Algorithm uses these features to predict the actual output. Different ML algorithms have different requirements of data.
When the data is not available as per the requirements of the algorithm, we also need to clean and prepare it so that our Model could be easily trained on this data.
According to a survey in Forbes, 80% of the work of data scientists is accounted by Data Preparation only importance of feature engineering in training any machine learning model and how much it is important in Data Science.
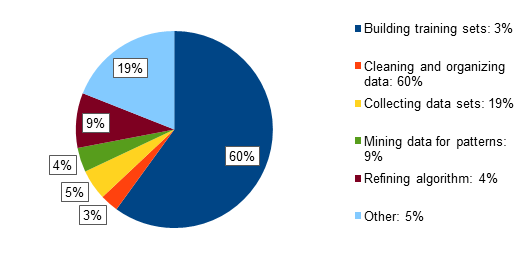
4. Granularity Management
Within the data structure, granularity means the level of detail of your data. Very detailed data (such as seconds, single product, one specific attribute) and aggregate data (such as total number of monthly orders, all products) can be found in a typical Data Warehouse. The greater the granularity of a table of facts, the more data you will have (or in an excel sheet: rows). But your data’s granularity also determines what kind of data you can get out of the stored data.So you need, of course, the same granularity to aggregate data.
Significance of managing granularity:
- The storage space will be determined by your granularity. hence, The higher/ finer the granularity, the more time you need to store.
- Your granularity will determine what kind of information you can create or get out of your information system (reports, etc.).
5. Sensitivity Management in Data Preparation
Sensitivity management is one of the most important factors of data preparation. To manage the sensitive data is most important work for the researcher because sensitive data may contain any confidential information which might harm the individual or a person.
These are the four steps to identify the sensitivity in data and determination of privacy:
- Determine if data has any confidential concern.
- also Determine how sensitive the data is (low, high, moderate).
- Prepare data access and dissemination policies and procedures upon sensitivity of the data which is under compulsion to know.
- Prepare data protection policies, mechanism, procedure based on sensitivity of the data.
Ways to manage sensitive data:
For developing a machine learning model, it is very important to manage our data, Decrease the uncertainty in the data. We cannot remove any sensitive data from our dataset because by the removal of sensitive data we would not be able to predict with high accuracy. so, For managing the sensitive data, we need to identify which data is sensitive and how much sensitive.
- Find the sensitivity in columns.
- observe sensitivity in unstructured text-based context dataset.
- Detect sensitivity in structured text-based dataset.
- note sensitivity in free form unstructured dataset.
- Find sensitivity in combination with the field.
6. Locality Management
Data Locality: This is a term that is always used in the context of Hadoop. Data Locality is the process of moving the computer near where the actual data resides rather than moving large data to computation. The overall network congestion is minimised by this whole process. This will also boost the system’s overall throughput and faster execution.
Data locality is a fundamental computing principle that assumes that to complete certain tasks, access to certain data is required. Instead of moving massive amounts of data to computation, the concept is to move the computation closer to where the data lives. An algorithm that optimises the data locality helps ensure that the computation is as close to the data as it can be.Data Locality Optimization is basically done for efficient data management.
Why do we have Data preparation in place ?
The digital transformation of business processes makes it compulsory for organisations to allow data to gain insights from many users. Many companies today see data preparation as the key to increasing their ability to use data efficiently in a dispersed manner to optimise business processes or to make it possible to be at the top of new, innovative business models. therefore, Achieving resourceful and agile data preparation is of extreme significance in the current scenario.
Thus, A complex business environment is created by increasingly unstable and saturated markets where the ability to differentiate by leveraging the power of analytics is strong. To gain insight into changing market scenarios, organizations struggle to keep up with the demand for data for analytics.

Conclusion
The right data preparation can lead to amazing results of good business information. Firms will quickly deal with data preparation challenges with enhanced technology and practises. Increasing data speed, variety, and volume require companies to revise the traditional sharing, reporting, and storage of information. Since data is the basis of analytics, the right data will also provide businesses with crucial information and help them to actually respond to industry changes.
Written by: Deepti Sardar
Reviewed By: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs