
Data pre-processing is a process of transforming raw data into a useful & efficient format so that it can be used for further analysis.
need of Data pre-processing
1) Incomplete:
The data is incomplete when some of the data entries are missing. Missing values are represented by “N/A”, “?”, 0 or just cell is kept blank.
For example,
The value of age attribute is blank for some employees in the company database
Age =” ”
2) Inconsistent:
The data extracted from different sources may have different conventions & units.
For example,
The unit used to measure height attribute varies in two different databases of athletes. So, combining the data from these two databases creates inconsistency.
Height = 163 cm
Height = 6 Feet
3) Noisy:
The data is said to be noisy when it contains outliers or errors.
For example,
The value of the age attribute is -3 for few employees in the company database.
Salary = -3
The four major steps involved in data pre-processing are,
- Data Cleaning.
- Data Integration.
- reduction of data or Data Reduction.
- Data Transformation.
1. Data Cleaning:
Data Cleaning is a process of filling up missing values, resolving inconsistencies in the data, detecting outliers & removing them for smoothing noisy data.
For example,
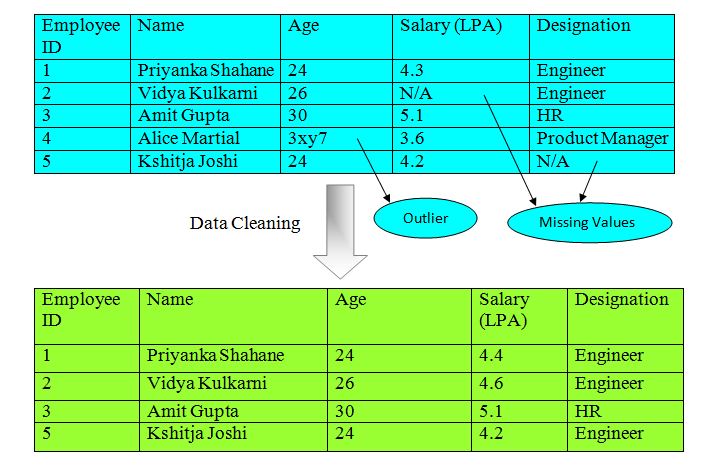
In the above example, columns represent attributes & rows represent data entries.
The various ways to deal with missing values are,
I) Recollecting the data:
The person who has gathered data can go back to the place where he has collected this data and try to find the actual value of the data.
II) Remove the missing data entries:
While removing missing data you can either remove the entire variable /attribute or you can just remove the single entry for which the data value is missing.
For instance, in the above example, we have removed the fourth row for which the value of the age attribute was missing.
Dropping a single data entry containing a missing value is beneficial when we don’t have more number of missing values for the particular attribute so that we don’t lose the high amount of good quality data.
In python, these missing values can be removed by the dropna method of the Pandas library. Using this method you can drop columns or rows containing the missing values. To drop columns you need to mention axis = 1 & to drop the rows you need to mention axis = 0.
For example,
df.dropna (subset=”Designation”, axis=0, inplace=True)
This operation will remove all the missing values in the Designation column.
III) Replacing data:
Even though the replacing data does not waste the data this is not a much accurate technique as we need to guess the values. One of the standard ways of replacing missing data entry is to replace it with the average value of the corresponding attribute for all data entries. For instance, in the above example, we can replace the missing value of salary attribute for Employee Id 2 by taking the average salary attribute for all other data entries i.e. (4.3 + 5.1 + 3.6 + 4.2)/4 = 4.3.
But for categorical values it is not possible to calculate the average, in that case, we can replace the missing value with the most common value of the corresponding attribute. For instance, in the above example, we have replaced the missing value for Employee Id 5 with the most common value of the Designation attribute i.e. Engineer.
Sometimes this missing data can be handled by other techniques as the person who collected this data knows some additional details about this data. For example, he may know that missing values Designation attribute tends to be HR.
In python, these missing values can be replaced by the replacement method of the Pandas library. Using this method you can replace missing values with the new values calculated by us.
For example,
df.replace(missing value, new value)
2. Data Integration:
Data integration is a process of merging data from different data stores such as multiple databases, files, or data cubes.
thus, it is collected by different people from different places so while integrating this data we may find that the attribute representing the same concept has different names in different databases which leads to inconsistency & redundancy. For example, attribute Designation may be represent it as Position & Job_title in different data stores.
Or we may find that the data is represented using different units in different databases for the same attribute. For example, in one database values of the height attribute represents in Centimetres & in the other database, it may be represented in feet.

To transform Cm to Feet we need to multiply each value in the Height(cm) column by 0.032808. Python provides the facility to perform this operation using a single line of code. You can select a column and multiply it by 0.032808.
df[“Height(Cm)”] = 0.032808* df[“Height(Cm)”]
Then rename the column name from “Height(Cm)” to “Height(Feet)
df.rename(columns{“Height(Cm)” : “Height(Feet)”}, inplace=True)
To integrate the data we need to bring data from different data stores into a single format.
Data Cleaning & integration is perform as a preprocessing step before loading the data to the data warehouse.
Careful integration helps us to avoid inconsistencies & redundancies in the resulting dataset.
3. Data Reduction:
Data Reduction is a process by which we find the reduced representation of the dataset which is comparatively smaller in volume but still produces the same or almost the same analytical results.
The strategies used to achieve reduced data are,
- Dimensionality Reduction
- Numerosity Reduction
1) Dimensionality Reduction:
Dimensionality reduction is a process by which we reduce the number of attributes under consideration.
Different dimensionality reduction methods are principal component analysis, wavelet transforms. These methods project or transform the original data on a smaller space. Attribute subset selection is a method of dimensionality reduction that detects & removes irrelevant, redundant or weakly relevant attributes.
2) Numerosity reduction:
Numerosity reduction is the process by which original data volume is replaced by alternatives or smaller forms of data representation.
These methods can be classified as
i) Parametric Methods:
In this method, data is estimated with the help of a model. Thus it needs to store only the data parameters & not the actual data. (Outliers can also be stored)
For example Log-Linear Model & Regression
4. Data Transformation:
Normalization, data discretization & concept hierarchy generalization are forms of data transformation.
Data transformation by normalization:
To understand the concept of normalization let us consider the example of an employee dataset containing details about age & income.

In the above example, we can observe that values of attribute age lie in the range of ‘0-100’ while the values of the attribute Income lies in the range of ‘0-500000’ or more.
Here the range of data values for the Income attribute is significantly higher than that of the age attribute. Due to its higher values, the attribute Income will weigh more in further analysis (for example, in the linear regression) which biases the results wrongly because the attribute is having a higher value doesn’t necessarily mean that it’s important as a predictor.
To avoid this we need to bring all the values in the range of 0 to 1.
Conclusion:
Thus, in this article, we discussed what is data pre-processing? why data pre-processing is required? and four major steps in data pre-processing i.e. Data Cleaning, Data Integration, Data Reduction & Data Transformation.
written by: Priyanka Shahane
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs