
Supervised Vs Unsupervised Learning:
In Supervised Learning, we have a clearly defined independent and dependent variables or the data is ‘labeled’ and it predicts a continuous response in case of regression and categorical response in case of classification.
On the other hand, Unsupervised Learning, the data is ‘unlabeled’ and emerging patterns are based on the similarity defined.
The important question then is: Is Clustering a Supervised or Unsupervised Learning? so The answer is it is Unsupervised Learning.
What does Clustering do?:
Clustering tries to identify the group of similar objects that are highly dissimilar between groups. In other words, there should be heterogeneity between groups and homogeneity within groups.
so, The objective is: To minimize the intra-cluster distances and maximize the inter-cluster distances.
Distance Measures:-
1. Euclidean Distance
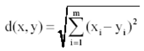
2. Manhattan Distance

3. Chebyshev Distance
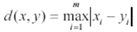
4. Haversine– so, This is mainly in use for latitudinal and longitudinal data.
5. Minkowski Distance

- If r = 1: Minkowski becomes Manhattan Distance
- If r = 2: It becomes Euclidean Distance
Types of Clustering:
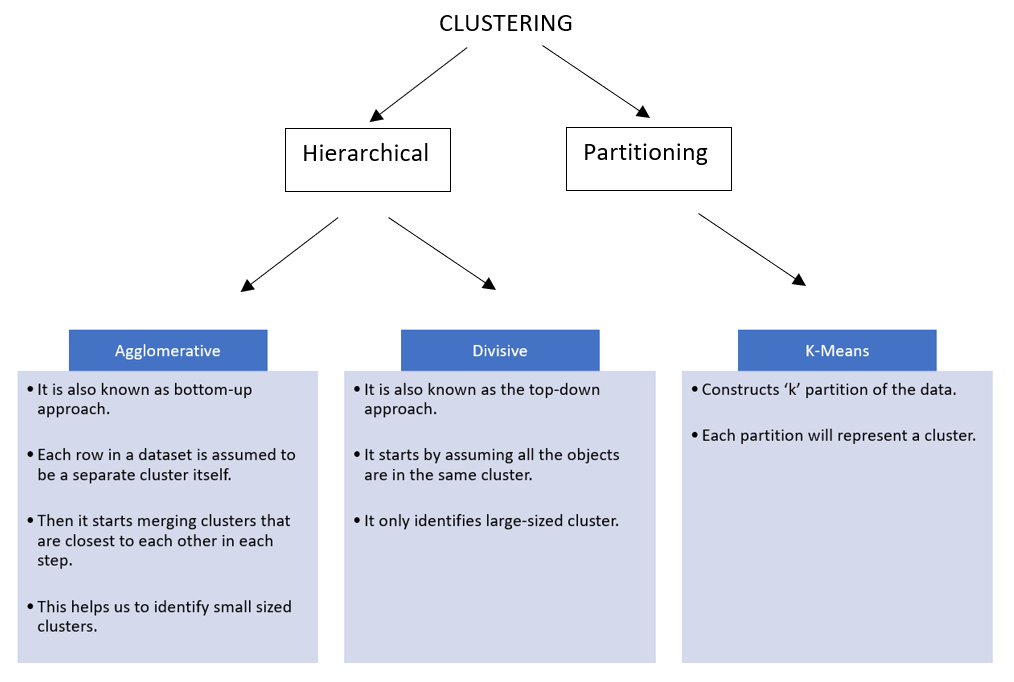
Hierarchical Clustering: Agglomerative
- Records are subsequently grouped to create clusters base upon distances between clusters and records.
- It also produces a useful graphical display of the clustering process and results, called Dendrogram.
Strengths of Hierarchical Clustering:
- There is no assumption on the number of clusters
- Desired number of clusters can be obtain by cutting the Dendrogram at the proper level
- Disadvantages:
i. This is not suitable for larger data sets
ii. Extremely sensitive to outliers
Steps in Hierarchical Clustering:
Step-1: Start with ‘n’ clusters where each record will be a cluster
Step-2: Two closest records are merge up into a cluster. This is ready using the distance measures. The default, however is, ‘Euclidean Distance’.
Step-3: At every step, the two closest clusters with the least distance are merge up i.e., either a single record is added to the existing cluster(s) or two existing clusters are combine then. This is repeat up till there is a single cluster that includes all the records.
- It is easier to calculate the distance between one cluster and the other if there is only one element in each cluster. But as we keep merging the clusters, one or more clusters consists of 2 or more observations, then we calculate the distance using ‘Linkage’ methods.
The various linkage methods are:
a. Single Linkage: Distance between the two clusters is define as the shortest distance between the two points in each cluster.
b. Complete Linkage: Distance between the two clusters is define as the longest distance between the two points in each cluster.
c. Average Linkage: Distance between the two clusters is define as the average distance between each point in one cluster to every point in the other cluster.
d. Centroid Linkage: Clusters represents their mean values for each variable which forms a vector of means. Distance between the two clusters is the distance between the two vectors in each cluster.
e. Ward’s Linkage: This method joins the records and clusters together progressively to produce larger and larger clusters but is slightly different from the general approach.
- Dendrograms: To find the optimal number of clusters. It is a tree-like diagram that summarizes the process of clustering. Here, similar records are joined by lines whose vertical length reflects the distance between the records. Greater the difference in height, the more the dissimilarity. The x-axis represents the Records or the rows of the data y-axis represents Height or Distance. By choosing a cut-off distance on the y-axis, a set of clusters are created.
Non-Hierarchical Clustering: k-Means
- Here, to form good clusters, we need to pre-specify the desired number of clusters (‘k’) unlike Hierarchical Clustering.
Steps in k-Means:
Step-1: Specify the value of ‘k’. Derive the number of clusters using Scree Plot.
Step-2: Partition the dataset into ‘k’ initial clusters where k centroids are randomly assign.
Step-3: Assign each record to cluster with the nearest centroid
Step-4: Recalculate centroids for losing and receiving clusters
Step-5: Check if the reassignments occur?
- If yes, go to Step-3.
- If no, go to the next step.
Step-6: Finalize the clusters.
Silhouette Score for k-Means Clustering:
Whether the observation is correctly cluster according to the distance measure or not is answer by Silhouette Score.

- If Silhouette Width is positive, mapping to its centroid is correct.
- If Silhouette Width is negative or b < a, mapping to its centroid is not correct.
The average of Silhouette Width for all the observations is called Silhouette Score for a dataset.
- If the Silhouette Score is close to 1, then on an average, clusters are well separated.
- or If the Silhouette Score is close to 0, then the clusters are not well separated.
- If the Silhouette Score is negative, the model is not efficient for clustering.
- WSS (Within Sum of Squares)/Distortion/Error Plot: The biggest challenge while performing k-means is to pre-define the number of clusters (k). To solve this problem, we can use WSS Plot.
Use Cases:
- Image Processing: Clustering images based on their visual content.
- Web: Cluster groups based on their access patterns on webpages and based on their content.
- Market Segmentation: Customer segmentation based on demographic and transaction history information to make marketing strategy basis this.
- Finance: Cluster analysis can be use for creating balance portfolios.
written by: Srinidhi Devan
reviewed by: Kothakota Viswanadh
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs