
The article is about Thera Bank. Most of these customers are depositors with different deposits. thus, The number of customers who are also borrowers is small, and the bank is interested in expanding this loan Modelling business rapidly and in the process
- The data set attach here for“Bank_Loan_Modelling”.
Libraries for Loan Modelling
This is the dataset on which I worked previously. Now, we are starting the Loan Modelling for the above dataset. Firstly, import all the necessary libraries. After importing those libraries, we will load the dataset.

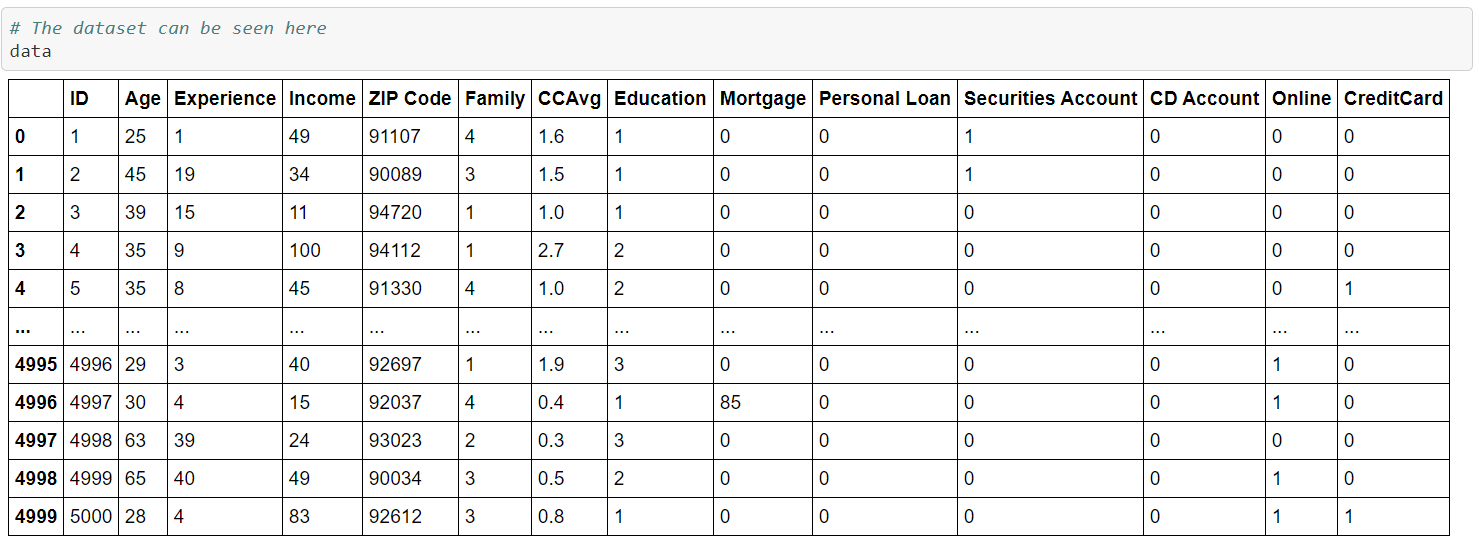
These are necessary libraries require for the analysis of the dataset. By using this word “data” we can see the dataset as we assigned the dataset with a variable named data. We can also see the data type of the dataset. We do this because we want to know about the dataset. These helps us to know the basic information about the dataset. By the below pictures, you will get an idea.
We can see the dataset’s data types using dtypes and information about the dataset using info keywords.


checking Missing Values
Now we are going to check whether the dataset contains missing values or not as we know null values too come under the outliers. So checking outliers in the dataset is very important.
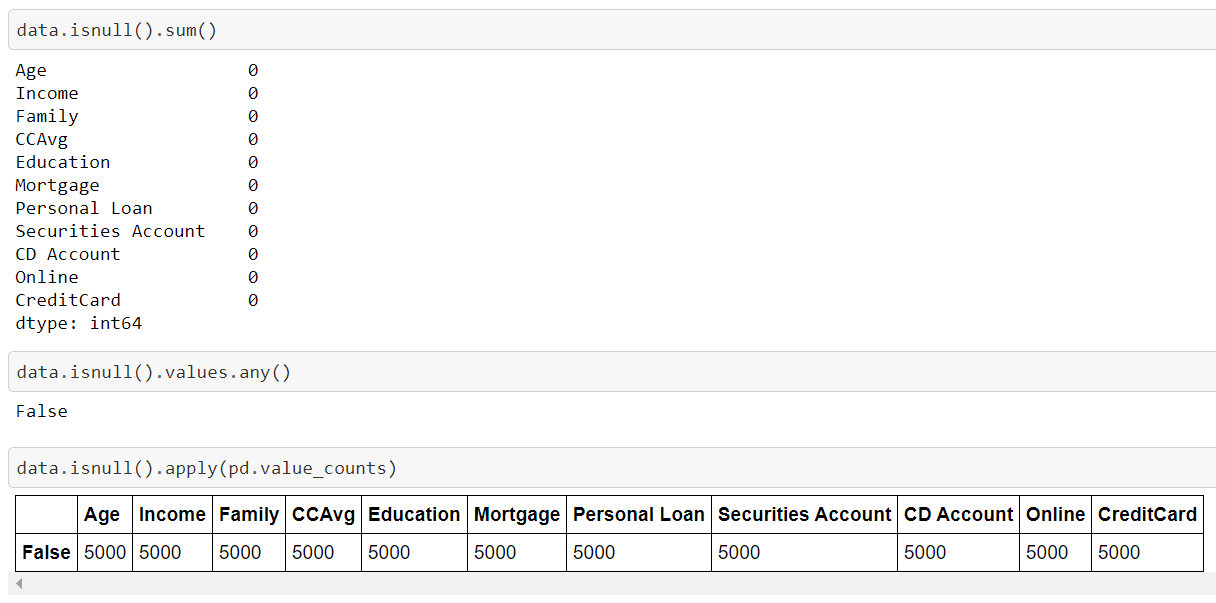
We can see there is no null value in the dataframe, False refers that the data does not contain any null values. So the observation is “No Missing Values in the dataset”.
Now we are checking whether the dataset contains invalid data or not i.e the data contains negative values or not. We use a function called any() , This helps to find whether the dataset contains invalid data or not.
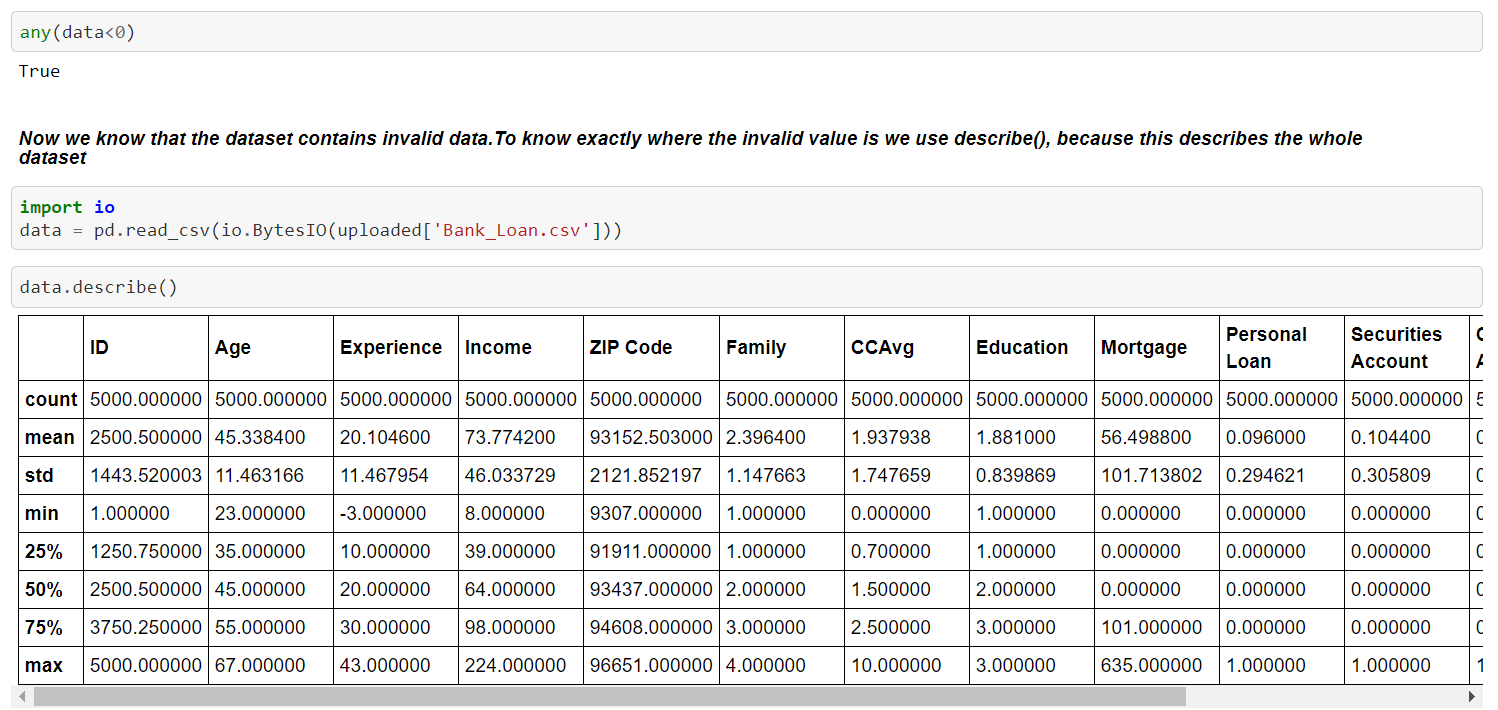
so, We can observe that Experience column have invalid values i.e negative value (-3.000000). We can verify the presence of the invalid values by code and it is verified below..,

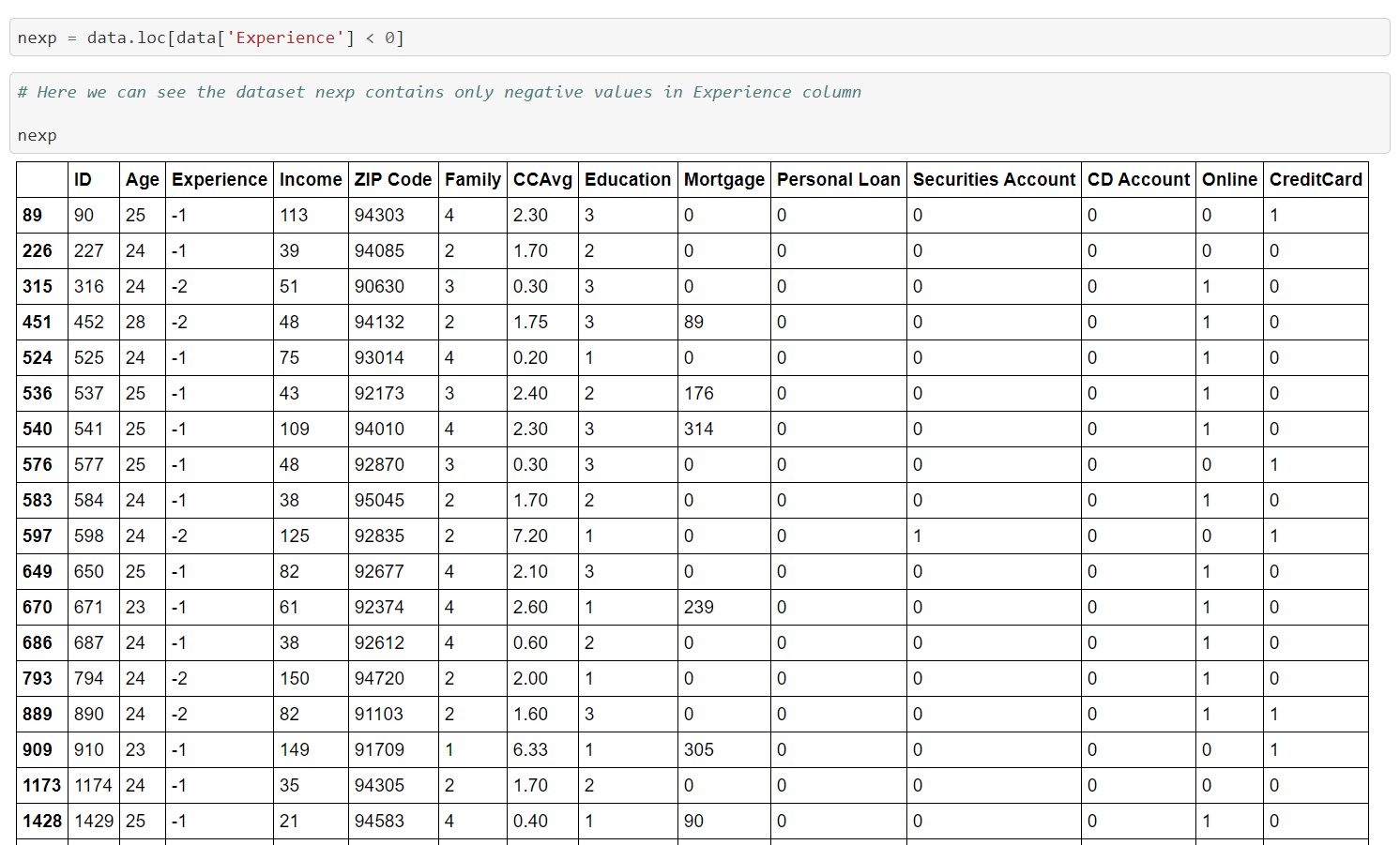
Here, we can see the dataset nexp contains only negative values in the experience column.

In the above code, we are thus replacing invalid values with valid values. After applying this code, the dataset does not contain any invalid entry in data any more.
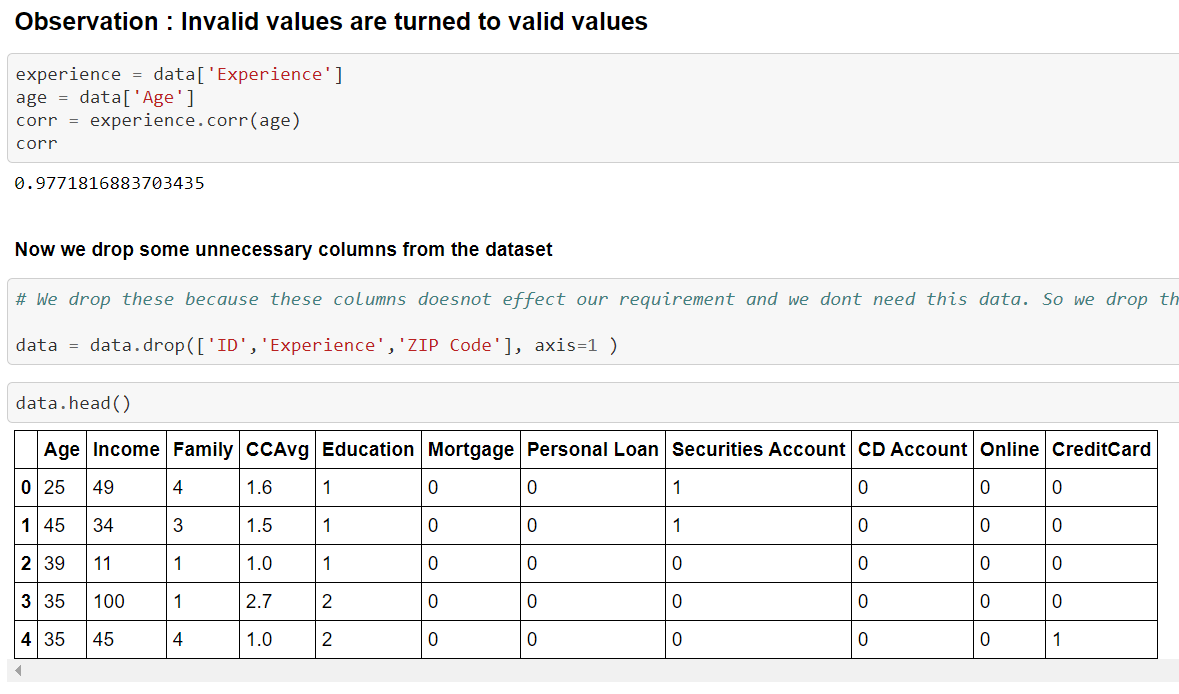
We drop some unnecessary columns from the dataset because these columns does not effect our requirement and we don’t need this data. So we drop this as it is of no use.
Exploratory Data Analysis
Now we are under going Exploratory Data Analysis part because this part is very important for data analysis. so Here univariate analysis and the data is skew or not? This type of answers can be find in this part.
We are doing univariate analysis. It is the easiest form of analyzing data.
We are plotting data using matplotlib for every column. We are analysing the data with bar plot , pie chart and all.
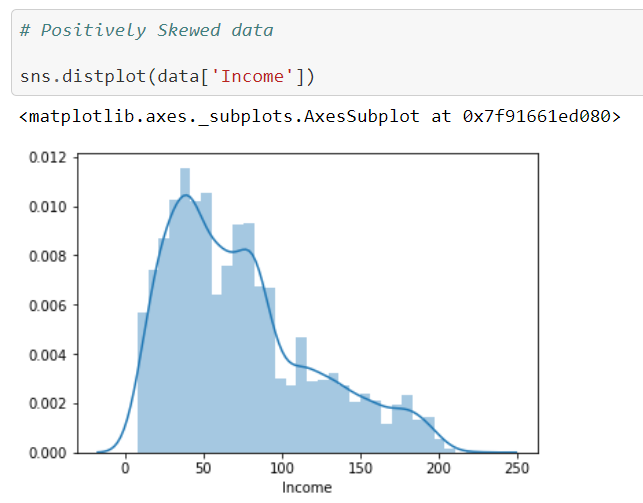
The data for the income column is positively skewed. Now we are doing analysis using Bivariate analysis.
Now again we are performing Multivariate analysis. Here in this analysis, the data will be examined as a multidimensional data as we are considering several data variable for the analysis. It is the extension of the Bivariate data analysis.

We can also plot the data using pairplot. Now we are going to count all the data in columns specifically.
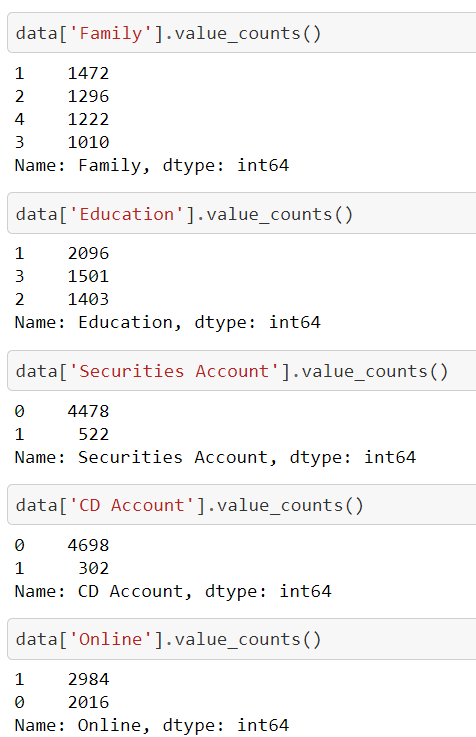
We use function value_counts(), for counting the data in the columns. We applied this function for the columns Family,
Education, Securities Account, CD Account, Online.
For transformation we are applying Z-Score as well as IQR,
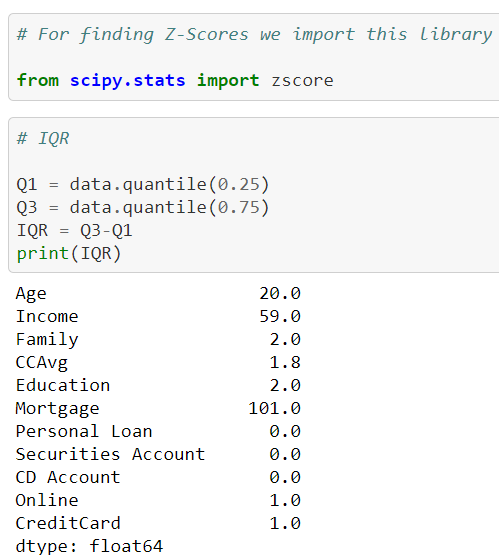
For finding Z-Score analysis and IQR we need to use this library named “ from scipy.stats import zscore “. with the help of this library we are getting the z-score and Interquartile range.
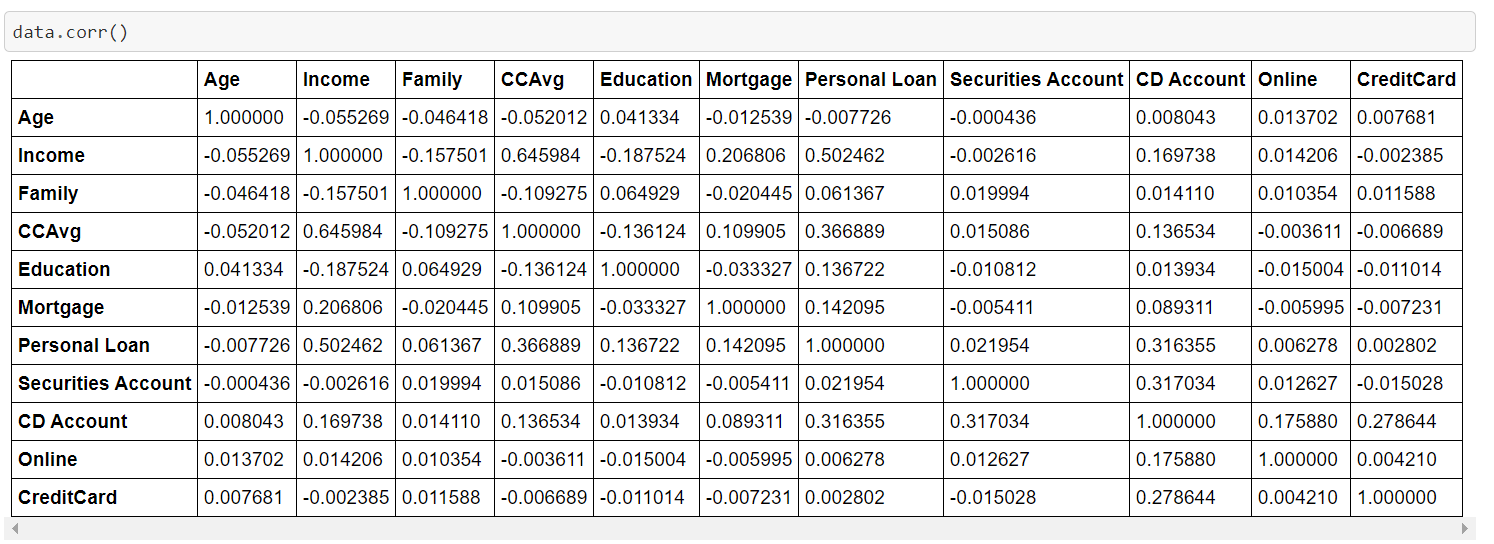
This is the heat map for the correlation of the data in the dataset.

Discovering Outliers
Now we are discovering Outliers with Mathematical functions, We are using Z-Score analysis here.
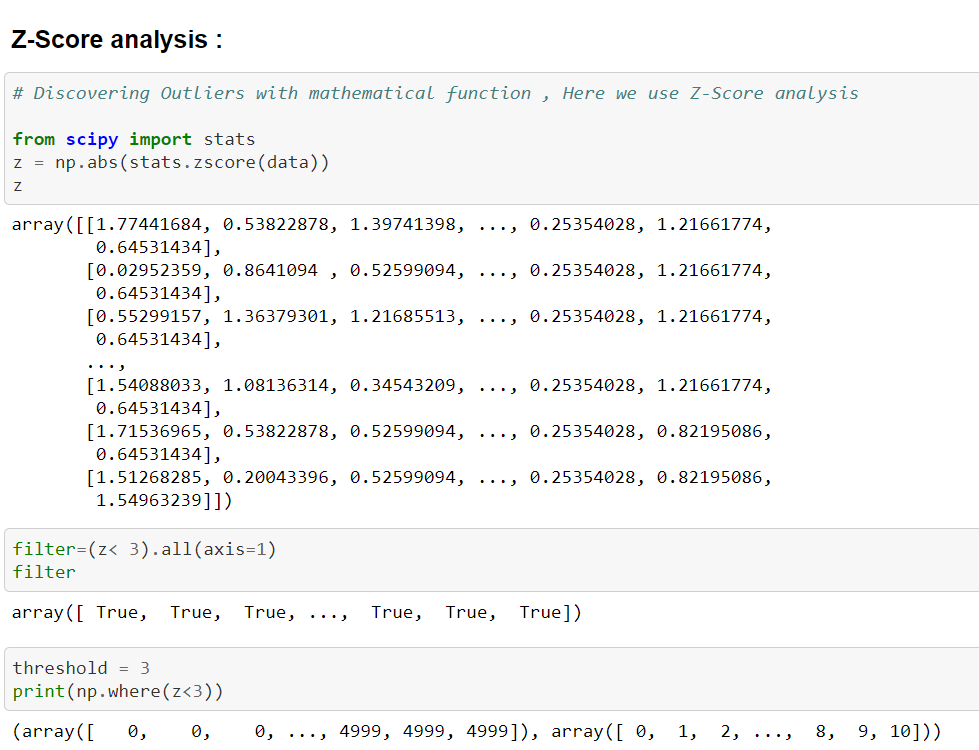
For Z-Score analysis, we have downloaded the required library i.e “from scipy import stats” and we assigned a variable “z” with “np.abs(stats.zscore(data))”. After that we are filtering the data by using threshold value.
To reduce the skewness of the data “log transform “ to apply..,
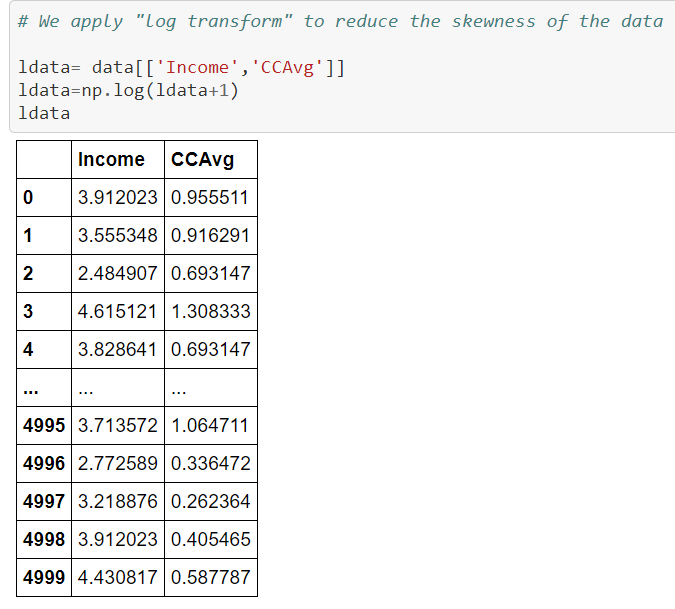
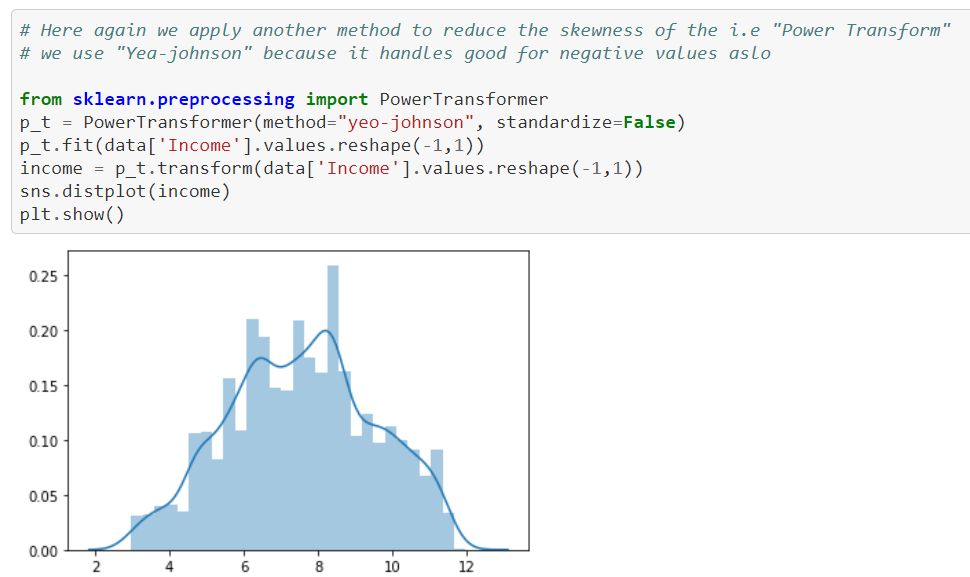
We apply another method to reduce the skewness i.e power transform.
We use Yea-Johnson because it handles good for the negative values also.
Here we use two types of transforms because PowerTransform design specifically to reduce the skewness of the given data but Log Transforms are also good in reducing the skewness. Hence we can use both the transforms for transformation.
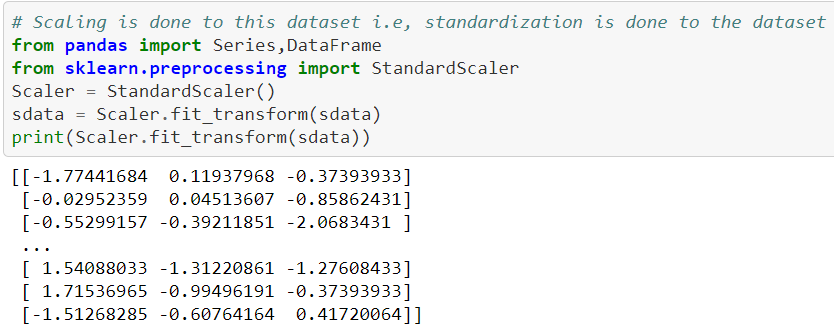
Scaling is done to this dataset i.e, standardization is complete to the dataset. data is split into x and y variables.

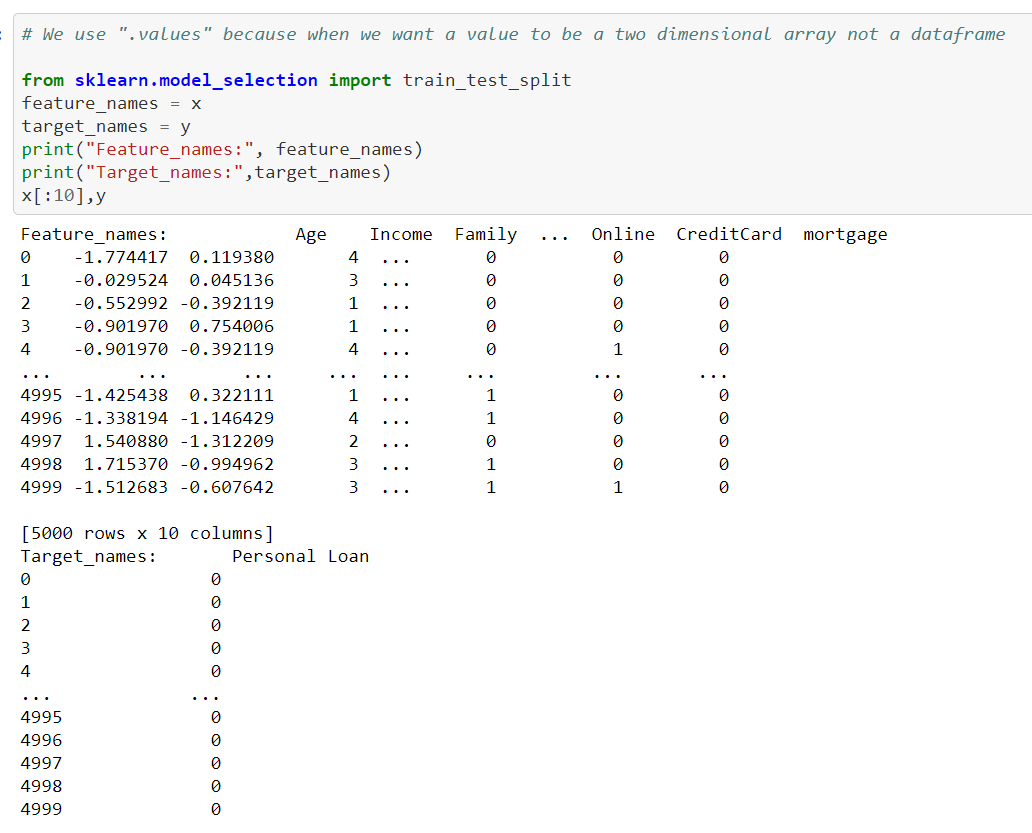
We use “values” because when we want a value to be a two dimensional array not a dataframe. Splitting data using Stratified Sampling.

Again data is splitted into x and y variables. Now we used stratified sampling to the given dataset inorder to satisfy our requirement.
We are applying classification Algorithms to the data.
Firstly we are applying Logistic Regression.
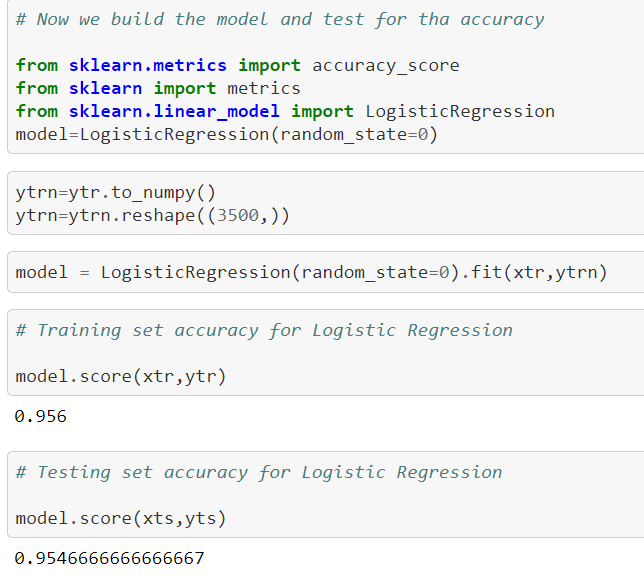
We imported all our necessary libraries required for performing logistic regression.
Here we achieve accuracy of 94 percent in both test and train set.
Now we are ready to evaluate metrics with a prediction set. In metrics we will be finding accuracy, confusion matrix, Recall score. We can also obtain classification report.
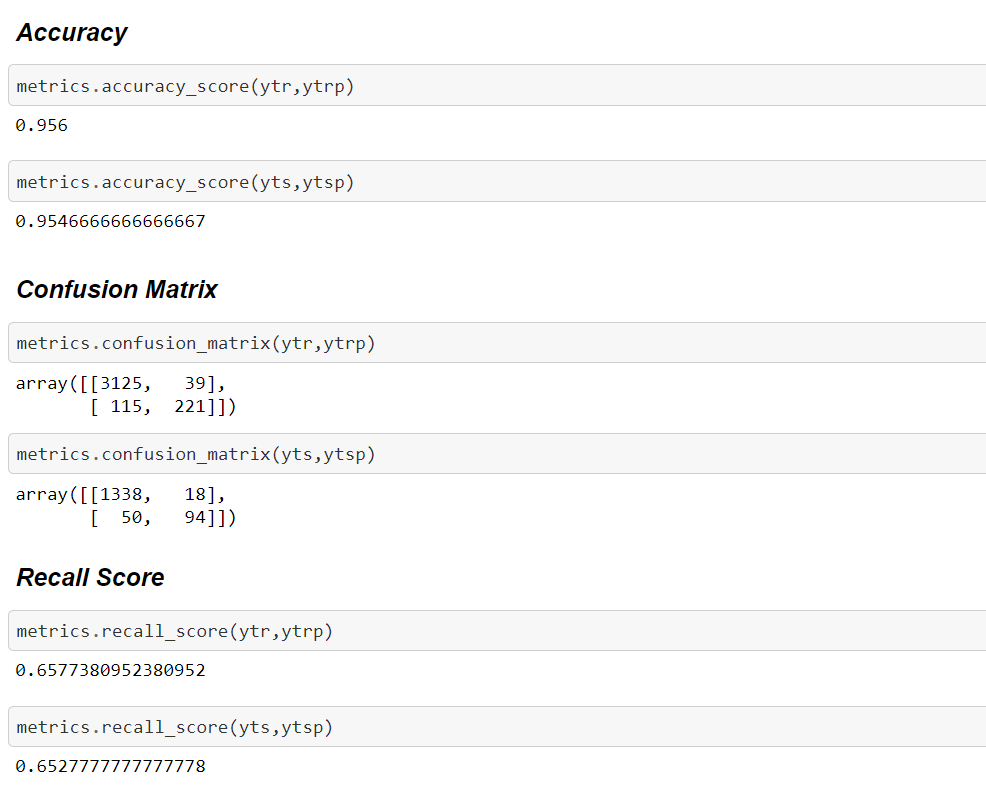
We got accuracy score for training data of 95.6 percentile and for training set we got 95.4 percentile. Recall Score for training set and testing set is 0.657 and 0.652. Now we will see the classification report for the training set and testing set.
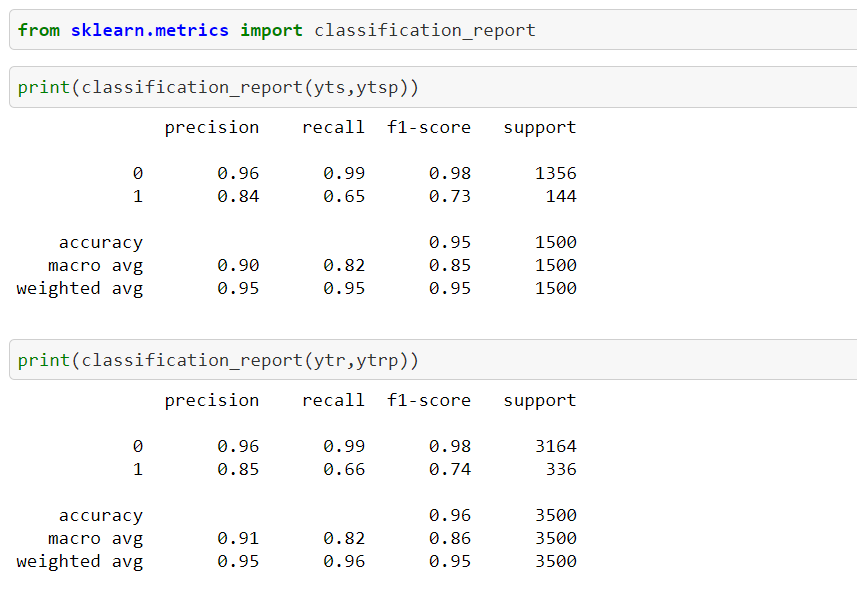
In the classification report, we can see the accuracy score, macro average and weighted average for Precision, recall, f1-Score, support for both the training set and the testing set.
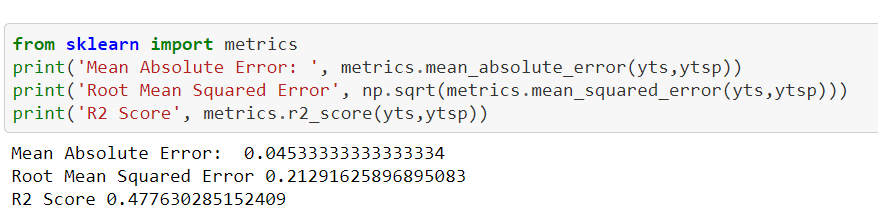
We are going to perform Support Vector Machines Algorithm to the data.

Support Vector machine is a representation of the training set. The training set accuracy for Support Vector machines is 0.976 and for testing set is 0.98 percentile.
We are using Decision tree algorithm :
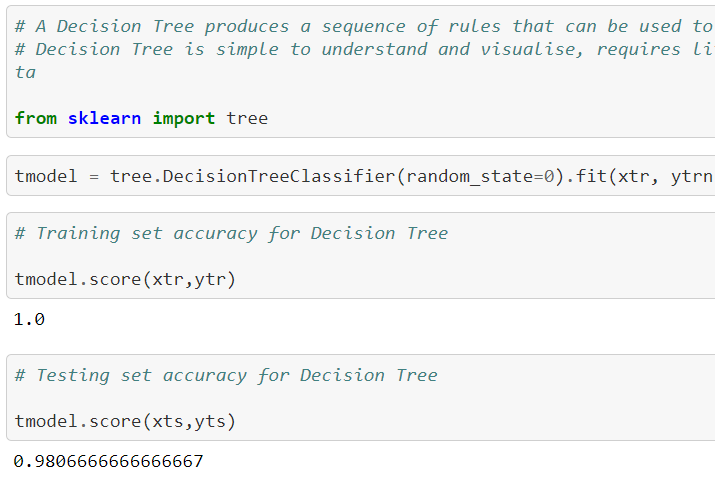
Training set accuracy for the decision tree is 1.0 and for the testing set is 0.98 percentile.
We are using Random Forest Algorithm :
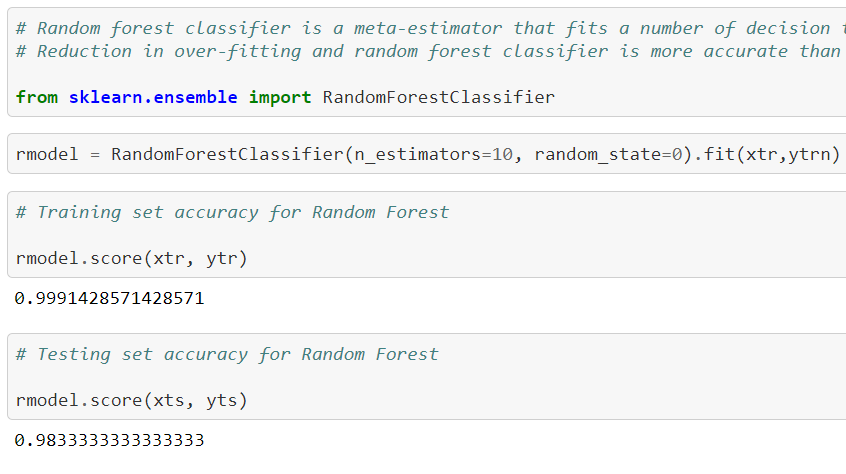
Training set accuracy for Random Forest Algorithm is 99 percentile and for testing set is 98 percentile.
We are using K-Nearest Neighbours :
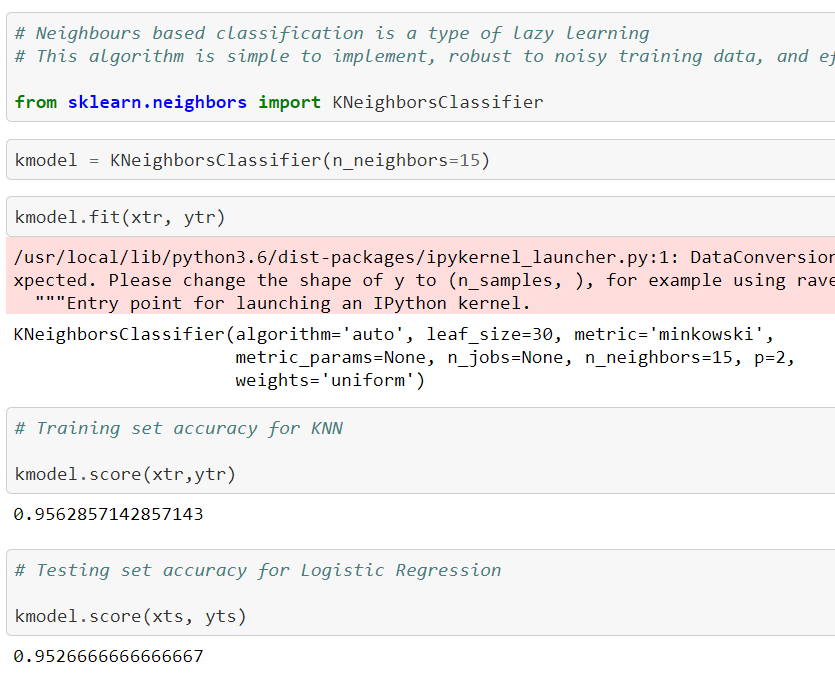
Training set accuracy for K-Nearest Neighbours is 95 percentile and for testing set is 95.2 percentile.
We are using Naive Bayes Algorithm :
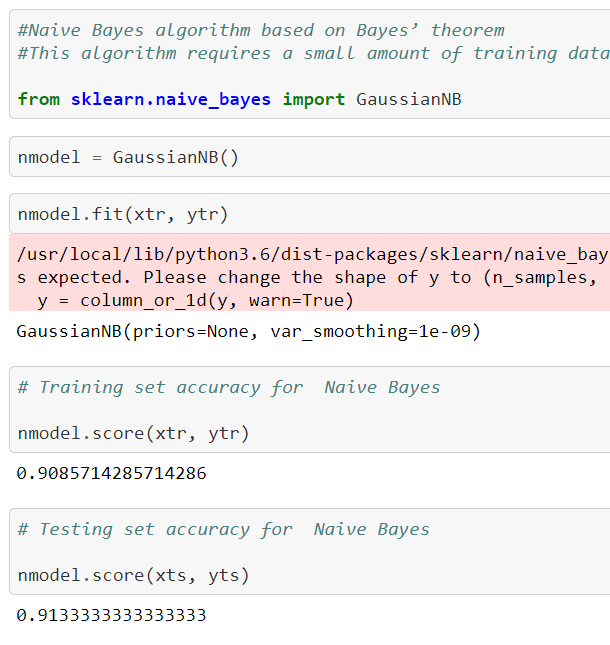
Training set accuracy for Naive Bayes is 90.8 percentile and for testing set is 91.3 percentile.
Conclusion and Business Understanding :
We check all the characteristics whether or not each of them has an association with the product been sold.We build a simple algorithm to make a subset of data.
Here some classification algorithms were used in this. From the above graph ,both Decision Tree and Random Forest Classifiers perform very well with our model.We choose Random Forest Classifier because it has slightly better accuracy than Decision Tree.. Random Forest algorithm have the highest accuracy and we can choose that as our final model.
Gradient Boosting classifer is stable in predicting even scaled or non-scaled data. It can reduce Computation cost. Random Forest predicted the personal loan acceptance more accurately than any other classifier model.
- Random Forest is our final model as it is very finite when compared to remaining algorithms.
For better understanding of the problem and detailed solution is available here, Bank_Loan_Modelling.
Thanks for reading ???…!
Written By: Sai Harsha Tamada
Reviewed By: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs