
In supervised machine learning models, we very often come across the term like bias and variance. The Model’s algorithms understand the pattern inside the training dataset and predict for the validation or test dataset. While prediction, it is quite common that the model encounters some error or we can say there is no perfect model and there is always an error component associated with the model outcome.
Consider the following model equation,
Y = F(x) + e
Where ‘Y’ is the output variable which is the function of the input variable ‘x’ and ‘e’ is the error term
Everyone intends to minimize the error so that we get the best-fitted model with maximum accuracy.
Now the error has three components namely:
- Bias error
- Variance error
- Irreducible error
The Irreducible error is not reducible as this error is cause due to some unknown variables which influence the relation of output and input variables. So, this error exists whatever the algorithms we use for training our model.
The Reducible error components are bias error and the variance error which we can control to minimize the error in the machine learning model.
In this blog, I will discuss what is bias error, what is variance error, and the bias and variance tradeoff.
The Bias Error:
The difference between the average of predicted values and the true value refer a bias error. The model with high bias error often leads to the underfitting scenario. The model fails to understand the pattern inside the data and oversimplifies the model. In turn, the model will show high train error as well as high test error. This type of error often observes in the case of the linear regression model.
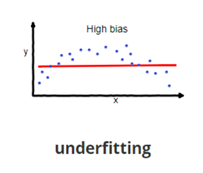
(Image Source Google Image)
In the above figure, the blue colored dots are the data points and the red color line indicates the fitted model. It can be observe that the model can not understand the pattern inside the data and underfits the model. Here the difference between the average predicted points and the true data points is quite high and leads to high bias error.
The Variance Error:
This error talks out about the spread in the data. It explains as the variation that is observed in our predicted values. The model with high variance error leads to an overfitting scenario. It tries to learn too much from the training dataset but fails to predict correctly on unseen data. In turn, the model will show low train error but high-test error. This type of error can be observe in the model like the decision tree.

(Image Source Google Image)
In the above figure, the blue colored dots are the data points and the red color line indicates the fitted model. It can be seen that the model understands the pattern so well that overfits the model. It could not generalize the model and will fail to predict for new data.
From the above discussion, it can understand that neither the underfitting nor the overfitting model is good. Both this model underperforms in case of unseen data. Any model that underperforms in unseen data is not of our use as it fails to predict correctly.
Now, the goal is to develop a generalized model that performs well with the training data as well as with the validation data.
Bias-Variance Tradeoff:
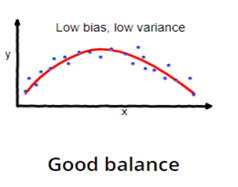
(Image Source Google Image)
In the above figure, the blue colored dots are the data points and the red colored line indicates the fitted model. It can be seen that the model understands the pattern and succeeds to achieve a generalized model. This model generalizes the data point and will be able to predict correctly for new data points. In this case, the model will have low training error as well as less test error. A model like the Random forest, the XG Boost will be the perfect example here.
The model shows low bias and low variance and that condition is called bias-variance tradeoff.
Bias And Variance Tradeoff
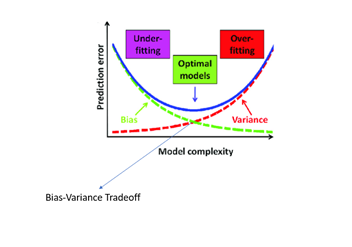
The above figure represents the optimal point for the bias-variance tradeoff. It is observed that when a model is less complex and high bias then it faces an underfitting scenario. On the other hand, if model complexity increases variance increases and the model encounters an overfitting scenario. The optimal model is at that point where there is low bias and low variance and balancing bias and variance is called bias-variance tradeoff.
Conclusion
In this post, I discussed bias error, variance error, and bias-variance tradeoff. I hope the concepts are clear. If you have any further queries please post them in the comment section. Thank you for reading. I am waiting for your suggestions and feedback. Happy Learning.
Written By: Nabanita Paul
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs