
If you think, there might be an error in your model, these are some troubleshooters to find the errors and what’s wrong with your machine learning problem !!
- Getting more training examples.
- Trying smaller sets of features.
- or Trying additional features.
- Trying polynomial features.
- Increasing or decreasing λ.
We are not going to pick any such method at random but instead we are going to pick the method according to our certain problem. Like we are not going to take a pyrexia tablet(medicine) for stomach ache problem !!
Analysing the hypothesis
A hypothesis may have low error for the training examples but still be inaccurate (because of overfitting).
With a given dataset of training examples, we can split up the data into two sets: a training set and a test set.
The new procedure using these two sets is then:
- So, we are going to find our optimum parameters by minimizing the cost function Jtrain using the training set.
- And compute the test set error Jtest
So, this gives the performance of our model for the unseen data and we are able to figure out the performance and then contribute any corrections or some changes for our machine learning model for better performance.
Train/Validation/Test:
In order to settle on the model of your hypothesis, you’ll test each degree of polynomial and appearance at the error result.
- Without the Validation Set (note: this is often a nasty method – don’t use it)
- Optimize the parameters in Θ using the training set for every polynomial degree.
- Find the polynomial degreed with the smallest amount of error using the test set.
- Estimate the generalization error also using the test set with Jtest(Θ(d))
In this case, we’ve trained one variable, d, or the degree of the polynomial, using the test set. This may cause our error value to be greater for the other set of knowledge.

Use of the CV set
To solve this, we will introduce a 3rd set, the Cross-Validation Set, to function as an intermediate set that we will train d with. Then our test set will give us an accurate, non-optimistic error.
One example thanks to breaking down our dataset into the three sets is:
Training set: 60%
Cross validation set: 20%
Test set: 20%
We can now calculate three separate error values for the three different sets.
With the Validation Set
Optimize the parameters in Θ using the training set for every polynomial degree.
Find the polynomial degreed with the smallest amount of error using the cross-validation set.
Estimate the generalization error using the test set with Jtest(Θ(d)).
This way, the degree of the polynomial d has not been trained using the test set.
- Just because a learning algorithm fits a training set well, that does not mean it is a good hypothesis.
- The error of your hypothesis as measured on the data set with which you trained the parameters will be lower than any other data set.
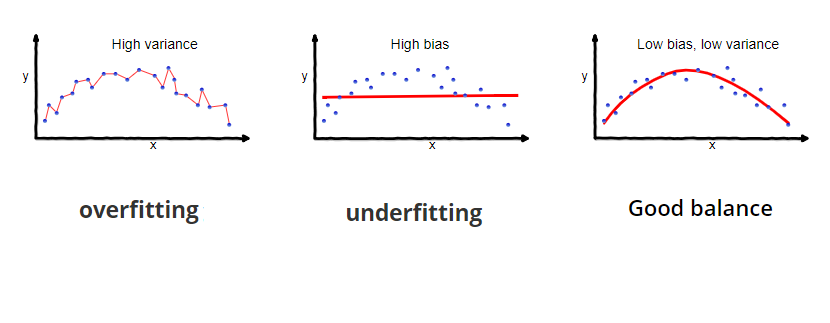
Contrast b/w Bias vs Variance
In this section we examine the relationship between the degree of the polynomial d and the underfitting or overfitting of our hypothesis.
We need to distinguish whether bias or variance is the problem contributing to bad predictions.
High bias is underfitting and high variance is overfitting. We need to find a golden mean between these two.
The training error will tend to decrease as we increase the degree d of the polynomial.
At the same time, the cross validation error will tend to decrease as we increase d up to a point, and then it will increase as d is increased, forming a convex curve.

The is represented in the figure below:
What to Do Next:
Our decision process can be broken down as follows:
- Getting more training examples
Fixes high variance
- Trying smaller sets of features
Fixes high variance
- Adding features
Fixes high bias
- Adding polynomial features
Fixes high bias
- Decreasing λ
Fixes high bias
- Increasing λ
Fixes high variance
Data for Machine Learning:
How much data should we train?
In certain cases, an “inferior algorithm,” if given enough data, can outperform a superior algorithm with fewer data.
We must choose our features to possess enough information. A useful test is: Given input x, would a person’s expert be ready to confidently predict y?
So, this can be used as an insight for how much data should we train on.
Summary
So in this article we have seen an analysis of hypothesis, (Train, Validation, Test sets), the contrast between bias and variance and how to figure out them, Many problems and many solutions to those problems, and how much data is required for a model to train on and these been a far insightful article to read and hope you have fun while reading this article.
Written By: Naveen Reddy
Reviewed By: Krishna Heroor
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs