The word transformer might be familiar to you as you have heard it before in the movies or learned about it in the physics class but here in machine learning it has a whole different meaning. Transformers are in use areas of machine learning such as natural language processing(NLP) where the model needs to remember the significance of input data. Let’s start by understanding why we use transformers in the first place when we have RNN’s?
Why should we use Transformers?
Have you ever wondered how alexa or siri is able to respond to your instructions and even give a reply? This is all possible due to natural language processing(NLP) where we train a model by giving information such as text speech and it is able to learn and give the desired output. The model consists of recurrent neural networks(RNN) which is in use to train words sequentially.
The speciality of RNN is that it is able to predict the next words based on previous words and this is possible by feeding the network current input data as well as output data of previous network and it will wholesome make a look enabling the model to remember its previous data.
but when the sentences are long it won’t be able to predict to the next word as it is in use to predicting the adjacent words but when the word to predict depends on the first word of the sentence it is unable to do so. This problem to some extent is solve by long short term memory (LSTM).
LSTM
In LSTM we use the concept of cells to remember the data , the cell is continuation of memory block which extends throughout the recurrent neural network in which information regarding each word is inserted into the cells which can carry that information to different lengths. so that far away neural networks can also gain access to those words and be able to predict the next word based on information of past few words.
but this model fails when the sentences were too long for even the cell state to remember. The other drawback of RNN and LSTM is that they are sequentially feeding the neural network which instead can be complete Parallel to speed up the process.
To summarise we can say that the problems in RNN and LSTM are:
- They are unable to predict next words when the sentences are too long
- Sequential input of input data
- The distance between input and output is linear and is equal to length of the recurrent neural network
In order to solve the functional dependency of the words on previous words which are far behind in the sentence we use the concept of ‘attention’.
For example when we are writing information on white into our notes we focus our attention on each word we are writing. The same analogy can be applies to attention in neural networks , when we focus on each word instead of focusing on the whole sentence like we did previously in RNN and LSTM.
Here in attention each word carries its own state which contains the significance of that word and also attributes such as ‘query’, ’key’ and ‘value’.
Where each attribute has its own significance, in that way we can add value to our model which can predict the next word which depends on information from a word which is far behind it. This solves the problem of functional dependency but it does not solve the problem of linear distance between input and output for which we use convolutional neural networks.
Convolutional neural networks are in use to convert the distance which is linear say ‘ n’ to convert it into ‘log(n)’ which is non-linear as the convolutional neural networks can also describe as a tree with input node being the root node and that solve the problem linear distance.
Now lets learn about working of a transformer which is a combination of both.
What are Transformers?
Transformers are a combination of attention and convolutional neural networks.Since each of the concept is in need of another concept the best way is to combine them, for example convolutional neural cannot translate words but recurrent neural network can and recurrent neural network has a linear distance but a convolutional neural network has a non-linear distance and by combining both of them we can attain both the features. Basically the Transformer can be divide up into two parts :
- Encoders
- Decoders
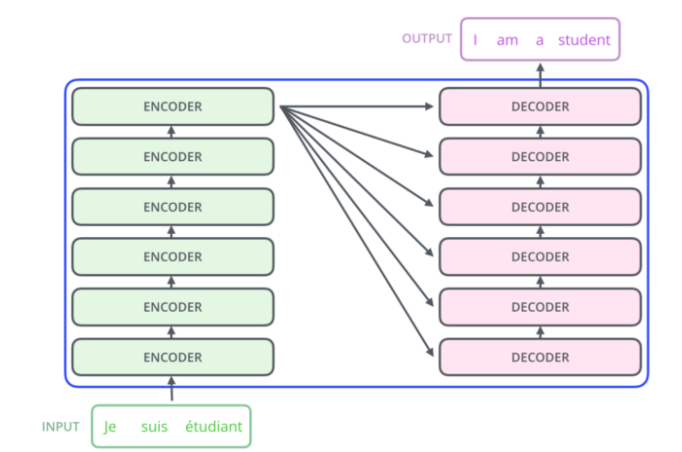
There are a total of six encoders and six decoders where each encoder connects up to each other and the final encoder is connects to all of the decoders. Decoder is the same as encoder except for one additional layer refer as encoder-decoder attention which helps the decoder focus on other parts of the input sentences. Each encoder consist of :
- Self-attention layer
- Feed forward layer
The self-attention layer helps in parallel computation of words where each word is process parallelly. It also helps encoder remember the significance of other words.
Let’s take look at self-attention layer in a step by step approach:
- The first step uses the concept of word embedding which uses vectors to cluster similar words together . For example happy, good , nice are clustered together whereas words such as bad, worse,boring are clustered together.
- As we have discussed earlier about ‘query’, ‘key’ and ‘value’ vectors, here we take the dot product of query and key vector in order to calculate the score of the word which represents the importance of the word.
- The next step is to divide the number obtained in the above step by 8 which is the square root of the size of vector i.e 64 and it may vary depending on the needs and then after dividing we apply the softmax function in order to compare the value with other values.
- The next step is to multiply the softmax value with the respective value vectors in order to eliminate words with least significance such as 0.0001 which leaves us with only the significant words.
The output is then calculated from the value vector and then fed into the fast forward neural network where each word is processed parallely. The same continues for all the encoders and then the last encoder value is fed into all the decoders which translates the input data.
source code:



Written By: Junaid Khan
Reviewed By: Vikas Bhardwaj
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs