
In this blog-post, we would be going through the process of creating a machine learning model based on the famous Titanic dataset. this gives the Titanic Survival Prediction, taking into account multiple factors such as- economic status (class), sex, age, etc.
The model predicts whether a passenger would survive on the titanic taking into account and comparing and finding relations amongst various features.
You can download the official Titanic dataset from https://www.kaggle.com/c/titanic/data
We start by importing all the important packages /libraries that would be required for building our model as well as to analyze the given datasets.

The next step would be to load the given training and testing datasets.

Data Analysis and Visualization | Titanic Survival Prediction
The next step is to start analyzing the given test and train datasets to find out patterns between the features and finding relations of essential features with the target feature (Survived or not).

We observe that the training dataset contains approx 891 rows and 12 columns (features) on the other hand the testing dataset contains 418 rows and 11 columns (since the target feature of Survived has been excluded for us to predict analyzing the training dataset).
Now we could further check for the null values present in the datasets.

You would find that in the training dataset the Age column contains 177 null values and the Embarked column contains about 2 null values whereas for the test dataset the Age column contains 86 null values and the cabin column contains about 327 null values. The rest of the columns have values properly filled (We would handle the null values later on, for now just analyze and note them down).
You could also check the entire description of the dataset at once to get a better understanding of the dataset.

Now we could start comparing individual features with the target feature and find out the effect of individual features on the target label i.e. how individual features determine whether the person survived or not.
thus, we would be comparing and visualizing certain important labels of the dataset and dropping less important ones to find patterns for our prediction. however, Now to make the model more accurate you could study all the labels without dropping any certain one. So, let’s start then,
1. Survival based on Passenger Class (P-class)-

Output:-

2. Survival based on Age:-
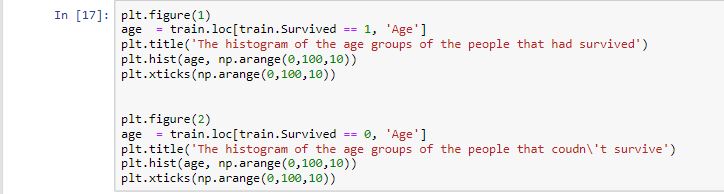
Output:-

3. Survival based upon Embarked label:-

Here we visualized about three important labels such as Age, Passenger class, and Embarked to see their effect on the survival of the passengers. Now you could even try the same considering other labels as you wish (There’s always a great field to explore on your own and further improve your model that’s a great aspect of machine learning).
Now we could even find the survival rate dependency comparing with individual labels without plotting them like above:-
1. Considering Passenger Class (P-class):-

2. Considering the SibSp label:-

3. Considering the Embarked label:-

Feature Selection | Titanic Survival Prediction:-
Now we saw that there were approx 12 different feature columns provided in the dataset. Now not all features have an impact on the required target feature (Survival in our case ). So it would be better to select the features of major importance and drop certain features that have a minor impact on our target column. This process is referred to as feature selection in machine learning.
First, let us drop some of the less important features of our datasets
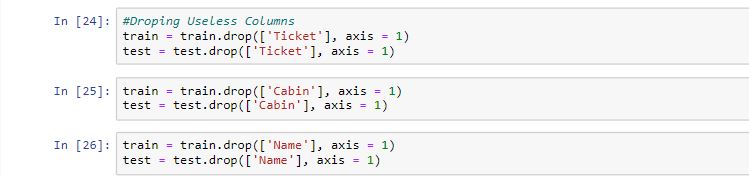
As you saw we dropped the (‘Ticket’,’Cabin’,’Name’) columns from our datasets.
Note:- There is no hard rule to drop or select a specific column. You do that according to your choice and you could even take it all for improving accuracy(All depends on you).
Here we select some important labels/features for our model training.

Handling data randomness and making it suitable for model training:-
During our data analysis phase, we saw that some features had null values and some had categorical data that needed to be encoded to be used efficiently.
First, handle all the null values by filling the null positions with either a mean or median value.

Also, there are features like – Sex and Embarked that are categorical in nature and could be more efficiently used if we encode them into integer values. You can use the get_dummies function of pandas library, create a lambda function, or any encoding technique you find suitable.

Next comes the step of building and training a model.
Model Building and Training:-
Firstly import the train_test_split from the sklearn library and then split the dataset into train and test specifying a test_size.

Now comes the part of selecting an algorithm for training our model. I prefer taking various algorithms and comparing their accuracy score and then selecting the best fit model having the maximum score.
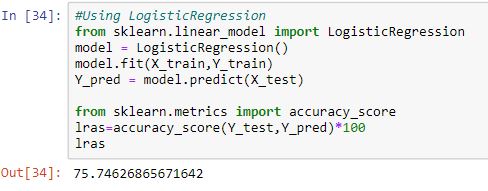
1. Logistic regression model:-
2. SVM model:-

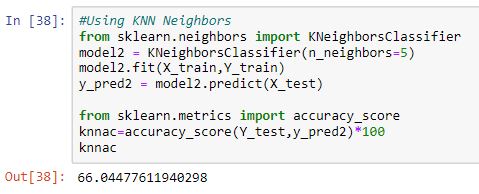
3. KNN model:-
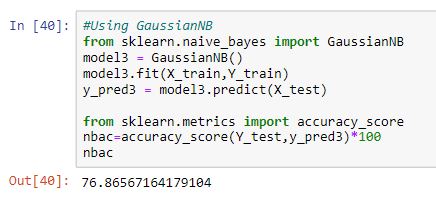
4. Gaussian naive_bayes model:-
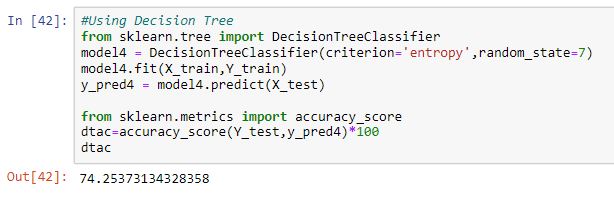
5. Decision Tree model:-
Now, let’s compare their scores to find the most suitable model for our problem.
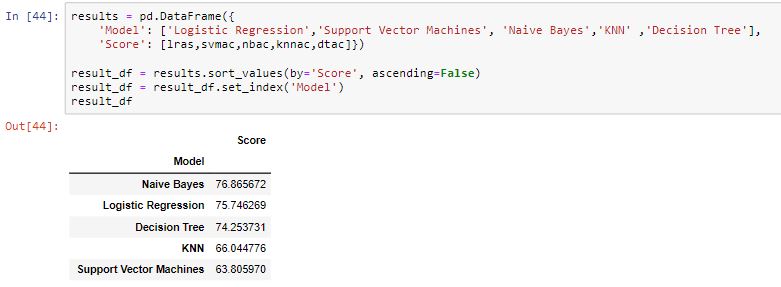
In our case, the maximum score was obtained from the Naive Bayes model hence we would be using it to train our model and predict the survival chances of the passengers.
conclusion
( The scores obtained can be further improved by hyperparameter tuning. As they say, there’s always a massive scope for improvement just keep on experimenting till you build your perfect model … ! ).
Hope this blog helped you to understand the basic concepts of building a model for solving the Titanic Survival Prediction problem statement.
written By: Rohit Kumar Mandal
reviewed by: Rushikesh Lavate
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs