Probability is the science of data mining. A Naïve Bayes classifier- a simple probability-based algorithm, use for the purpose of classification. It uses Bayes theorem but assumes that instances are independent of each other. However, Naive Bayes is consider one of the fastest algorithms for classification task when a large volume of data is hand over with few features in the data set.
The ‘Naive Bayes’ algorithm can be trained very efficiently in a supervised learning setting. It offers fast model building and scoring both for binary and multiclass situations for relatively low volumes of data. The algorithm makes a prediction using Bayes theorem which incorporates evidence or prior knowledge in its prediction.
Bayes Theorem
Bayes theorem relates the conditional and marginal probabilities of stochastic events C and A, which is mathematically shown as
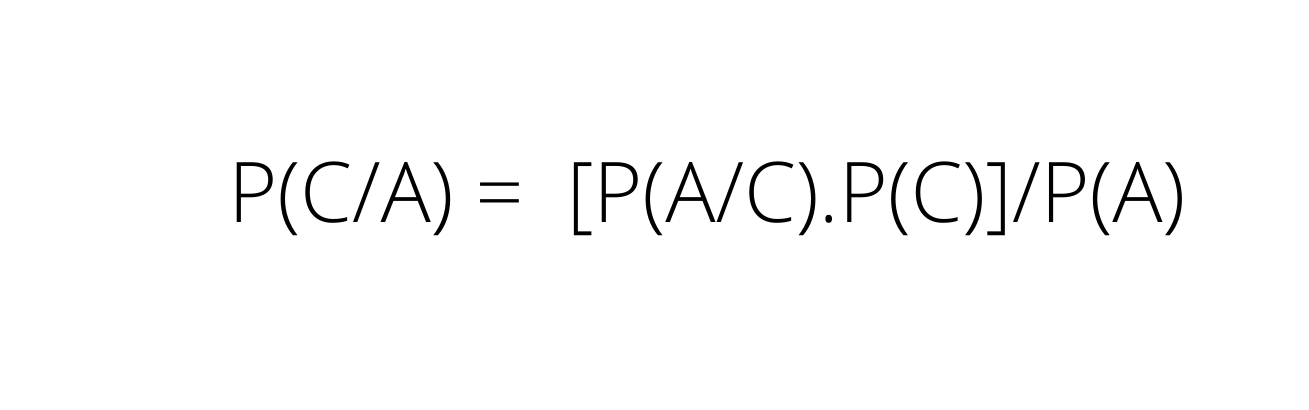
P(C) = marginal probability of C.
P(C/A) = conditional probability of C, given A. It is the posterior probability. because it has already incorporate the outcome of A.
P(A/C) = conditional probability of A, given C.
P(A) = marginal probability of A.
What is the classification?
According to the definition of machine learning, this labelled training data is the experience or prior knowledge or belief. It is called supervised learning because the process of learning from the training data by a machine can be related to a teacher supervising the learning process of a student who is new to the subject.
Training data is the past information with the known value of class field or ’label’. Hence we say that the training data is labelled in case of supervised learning. In today world classification is use in for various purposes like spam email filtering.
Popular variants of Naïve Bayes algorithm
There are three types of Naïve Bayes algorithm types: –
1. Gaussian – When working with continuous data, an assumption often is taken is that the continuous values associate with each class distribute according to a normal (or Gaussian) distribution. It supports continuous-valued features and models.
2. Bernoulli – The binomial model is useful if your feature vectors are binary (i.e. zeros and ones). One application of this model which is widely in use would be text classification with ‘bag of words’ model where the 1s & 0s are “word occurs in the document” and “word does not occur in the document” respectively which helps to classify the text accordingly.
3. Multinomial – It uses term frequency i.e. the number of times a given term appears in a document. After normalization, term frequency can be in use to compute maximum likelihood estimates based on the training data to estimate the conditional probability.
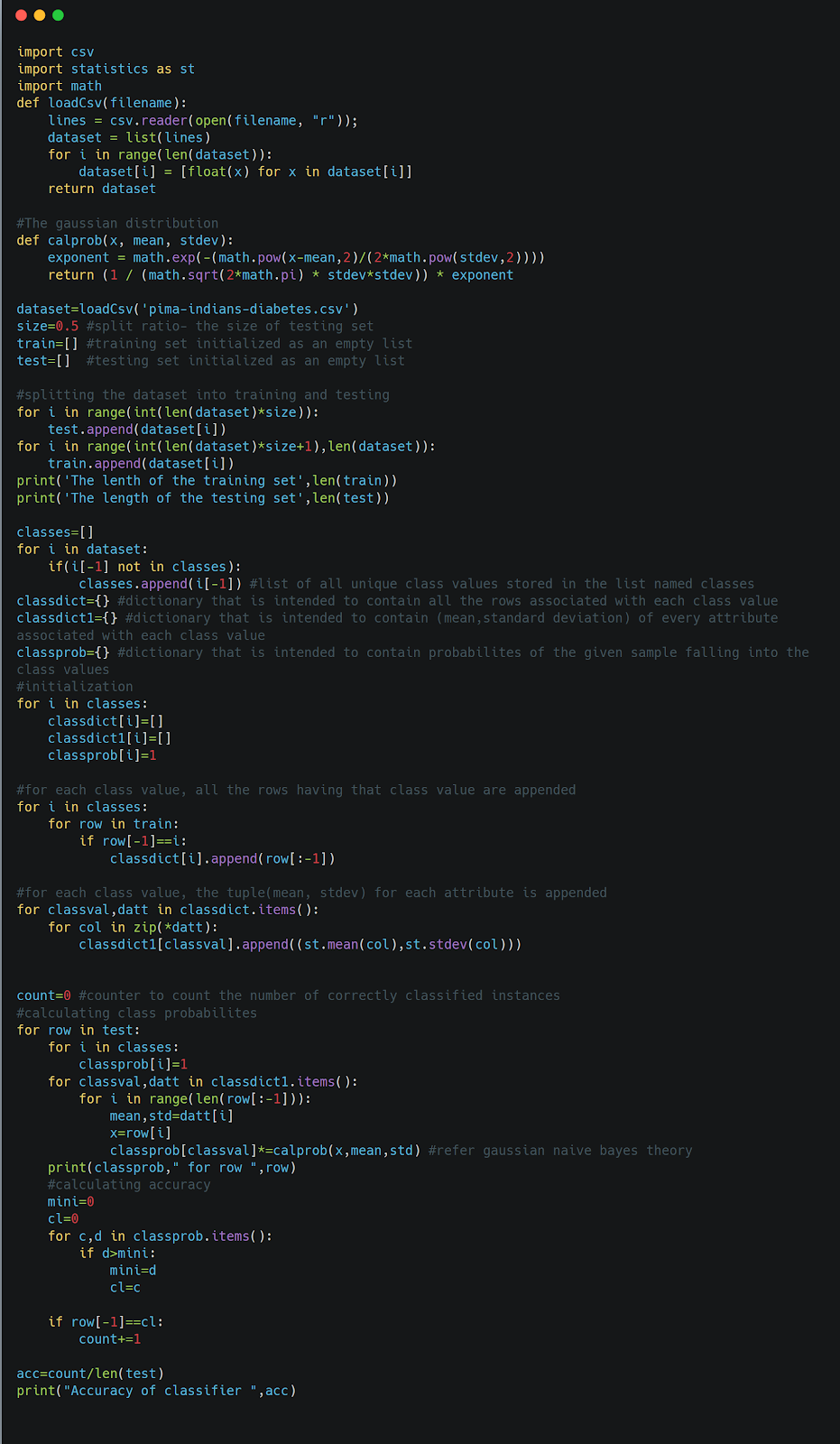
Naïve Bayes example code
The below example code is to predict whether the person has diabetes or not. In order to predict that we have made use of Gaussian Naïve Bayes algorithm and also to detect the accuracy of our model.
Strength and weakness of the Naïve Bayes algorithm
Strengths:-
1. Simplicity – The algorithm is very simple to implement. Its interpretation is also simple and computation there is no numerical optimization, no matrix algebra and calculation.
2. Efficiency – The algorithm is efficient to train and use. It can be easily update upon if new data is share with the model. Since the algorithm is equivalent to the linear classifier, it is fast.
3. Supportive – Unlabelled data can be in use in parameter estimation for other application. The algorithm has demonstrated relatively good effectiveness with small training sets.
4. Convenience – Independence allows parameters to estimate on the different database, for instance, from one dataset we can estimate content features from messages without header and in other datasets we can estimate header features of the message with content missing.
Weakness:-
1. Fine Tunning – The threshold or boundaries between classes have to be tuned and can’t be set analytically.
2. Assumptions – The independence assumptions is a very strong inference and untrue for a most real-world problem.
However, this assumption is common with a probability distribution and it has been successfully applied in many real-world situations.
Applications of Naïve Bayes algorithm
Document classification
As it uses Bayes theorem of implementation is performs well in classifying different types of documents. Determining whether a given document corresponds to one or more type of categories. In the text case, the features used might be the presence or absence of keywords in the document.
Medical Diagnosis
Naïve Bayes algorithm has been successfully in use and found very useful for a various medical diagnosis like localization of the primary tumour, prognostic of recurrence of breast cancer, diagnosis of thyroid diseases.
Recommendation System
Recommendation System will provide a recommendation of different movies, songs etc. depending upon the past watches. So, Naïve Bayes is use for building such kind of system.
Spam mail filter
It one of the most widely used implementations of this algorithm is to do determine whether the email is spam or not. It detects the relation the use of tokens in spam and non-spam emails to detect whether the new email is spam or not.
Conclusion
Naïve Bayes uses probability to make an assumption so that all features are independent. It has much application and performs decently in various applications.
Written By: Prateek Sharma
Reviewed By: Savya Sachi
If you are Interested In Machine Learning You Can Check Machine Learning Internship Program
Also Check Other Technical And Non Technical Internship Programs