
XGBoost is a fast and powerful machine learning algorithm, which has become a popular choice for online machine learning competitions due to its high efficacy. Its complete moniker is Extreme Gradient Boosting. XGBoost is an enhanced implementation of Gradient Boosting in terms of both speed and performance.
XGBoost is a high-performance decision-tree-based ensemble learning method usually used for supervised learning. In Ensemble Learning, results from different individual models are combine in order to make an optimize prediction. Instead of depending on a single model’s outcome, the Ensemble learning method makes a decision by aggregating results from different models to put forth a model with better accuracy.
TYPES OF ENSEMBLE METHODS
- Bagging — In bootstrap aggregating(BAGGing), numerous models are Use Up parallel using randomly training data subsets. These models are then combine based on majority votes of their decisions.
- Boosting — Similar to bagging but instead of parallel, the models are use up in series. For each successive model, the weights are adjust by depending on the performance of previous models.
XGBoost
XGBoost is an optimized enhancement of Gradient Boosting. In boosting, weights are added to the model based on the residuals. However, in gradient boosted the loss function is optimized to correct errors made by previous models. XGBoost introduces new features to gradient boosting like regularization, tree pruning, and parallel processing. To clearly understand the XGboost algorithm let’s take a look at XGboost in regression as well as classification, with examples.
1. REGRESSION
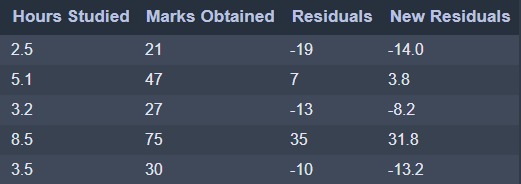
For regression, let’s try to predict the marks of students based on the number of hours studied. Initially, let us consider the average Marks to find the residuals. The average of the five marks is 40, which will be the prediction of the base model. Consequently, the residuals for the first five readings are -19, 7, -13, 35 and -10, respectively.

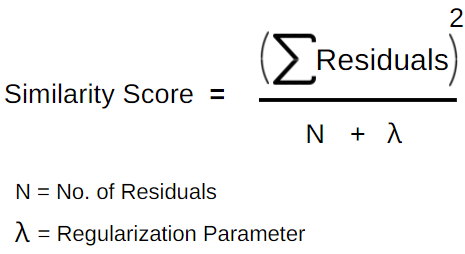
We use the residuals to construct the decision tree with splitting criteria say Hours studied greater than 3.3, then calculate the similarity scores for the root and leaf nodes. λ in the equation is the regularization parameter.
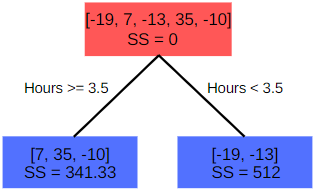
To begin with, let λ=0. The similarity score for the root is calculate to be 0. For the two nodes, the similarity scores are 341.33 and 512.
We then calculate the gain which in this case is 853.33.

After the gain is calculate, the auto tree pruning is complete. For this purpose, we use the gamma parameter in XGboost regression. If the gain is less than the gamma value then the branch is cut and no further splitting takes place else splitting continues. If the value of gamma is more, more pruning takes place. The learning rate in XGboost is in use to know the convergence of the model. For this algorithm, it is refer to as eta and the default value is set to 0.3.
Now we find the new prediction for the data.

For first reading, new prediction = 40 + ( 0.3 x -16 ) = 35.2
The new residual for this reading becomes, 21 – 35.2 = -14
Similarly, we continue to do so for all readings. We then use these values for the next model and so on, the loss will keep on optimizing.
2. CLASSIFICATION
For classification, let’s try to predict if students pass or fail based on the number of hours studied. For binary classification, the probability for the base model is 0.5, meaning there is a fifty percent chance that a student will either pass or fail. Consequently, the residuals for the first five readings are -0.5, 0.5, -0.5, 0.5 and 0.5, respectively.

Similar to regression, we construct the decision tree for Hours greater than 3.5 and then calculate the similarity scores. The difference between the similarity score formula for regression and classification is the loss function. λ remains the same.
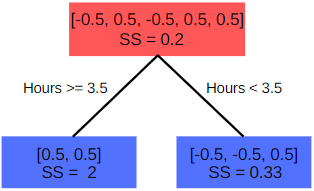

With λ = 0, the similarity scores for the root and nodes are 0.2, 0.33 and 2, respectively. The gain is 2.13 which is calculated similarly as we calculate for regression part.
Pruning in classification is complete differently than in regression. In classification, we calculate the cover value of each branch. If the gain is greater than the cover value only then further splitting is ready else the branch is cut. In this case, both branches can split. This is how pruning is done in XGboost classification.
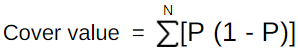
For the new predictions, we first find the new probability using the log(odds) function. Using the log(odds) formula, the log(odds) value for the base model is 0 (p=0.5).
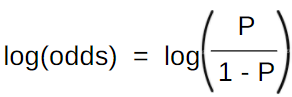
For the first reading, we calculate the log(odds) prediction value as..
0 + (0.3 x -0.66) = -0.198
Where 0.3 is the learning rate(eta) like in XGboost regression and -0.66 is the output value is..
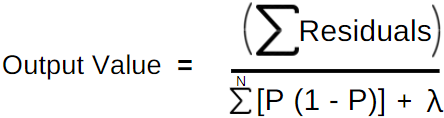
We then need to convert this log(odds) value into probability. For this, we use the logistic function.

Plugging in log(odds) = -0.198 in the above formula, we get a probability of ≈0.45.
The new residual for this reading becomes -0.45. Just like in regression we continue the process to optimize the loss until the residuals become very small or have reached the maximum number.

For both XGboost classification and regression, as the value of λ increases, more pruning takes place due to a decrease in the similarity score and smaller output values. An increase in the value of the regularization parameter reduces the sensitivity of the model towards individual observations. As a result, the regularization parameter takes care of outliers to an extent and reduces overfitting.
PYTHON IMPLEMENTATION
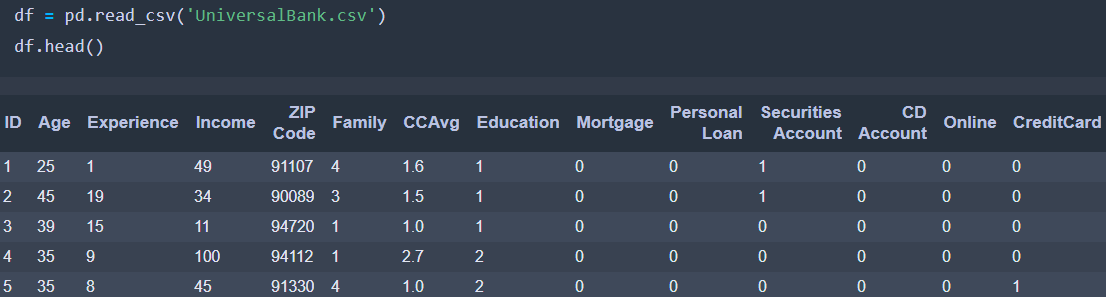
Let’s take a look at the implementation of XGBClassifier() in python.
- Import Libraries

- Load Data
- Train-Test Split

- Train model
- Cross-Validation

- Prediction
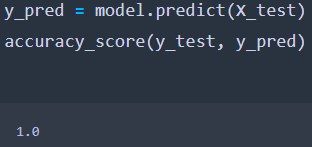
Our model in this case performs extremely well to give 100% accuracy. However, this will not always be the case, and we will need to work around it accordingly.
CONCLUSION
XGBoost is one of the most popular high-performance algorithms out there. Hopefully, this article gives you a brief introduction to XGBoost in machine learning, it’s functioning and execution, giving you a foundation to explore further. Try using it in projects and competitions, XGBoost might just end up putting you on top of the leaderboard.
Written by: Vishva Desai
Reviewed By: Vikas Bhardwaj