
In this blog we will discuss what Recurrent Neural Network is and why do we need it. We will also discuss in depth Architecture of LSTM and GRU. so let’s dive in.
What is Recurrent Neural Network?
Basically RNN is a combination of weights or learnable parameters which passes the words in sequence one by one. You can think of it as a Dense Layer with for loop. All the words in sequence share the same parameters .

Here, in this Image h indicates the RNN layer (combination of weight matrix) and x in the entire sequence, if we unfold this image we can see that each word x<t> is passed through RNN layer (h) and then RNN layer Produces 2 vectors :
- Output Vector
- Hidden State Vector
The first output vector given to the next layer and the hidden vector passed into RNN itself so that it can connect one word to another. So in other words we can say that every output of a word depends on the previous word in any sequence. So we can not parallelize this architecture , it is one of the major drawbacks of RNN.
Recurrent neural networks (RNNs) square measure a category of neural networks that square measure naturally suited to process time-series information and different sequent information. Here we have a tendency to introduce repeated neural networks as associate degree extension to feedforward networks, so as to permit the process of variable-length (or even infinite-length) sequences, and a few of the foremost widespread repeated architectures in use, together with long memory (LSTM) and gated repeated units (GRUs). Additionally, numerous aspects encompassing RNNs square measure mentioned intimately, together with numerous probabilistic models that square measure usually Realized victimization RNNs and numerous applications of RNNs that have appeared inside the MICCAI community.
More About Recurrent Neural Network
RNN – a neural network designed for analyzing streams of information by suggesting that of hidden units. In a number of the applications like text process, speech recognition and deoxyribonucleic acid sequences, the output depends on the previous computations.
Since RNNs contend with sequent information, {they square Measure They’re} well matched for the health information {processing|IP|science|scientific discipline} domain. wherever monumental amounts of sequent information are obtainable to process.
RNN or feedback neural network – the second quite ANN model, within which the outputs from neurons square measure used as feedback to the neurons of the previous layer. In different words, this output – taken into account as associate degree input for the following output. RNN (Fig. 4) is principally used for dynamic scientific discipline like statistical prediction, process management, and so on. Hopfield network and perceptron with feedback square measure the favored sorts of this network. Generalized delta rule and energy step-down operate square measure main coaching algorithms used for RNN.
Why We Need Recurrent Neural Network?
As we know in any english sentence every word is dependent on its previous context. so for sequences we can not use Dense Layers because neurons in those layers are independent and this is contradiction to what we have said about sequences.
Types of RNN Layers
As of now there are generally 3 Types of RNN Layers available , you can find these in Tensorflow Library.
- Basic RNN Block
- GRU Layer
- LSTM Layer
The pros and cons of a typical RNN architecture are summed up in the table below:
| Advantages | Drawbacks |
| • Possibility of processing input of any length• Model size not increasing with size of input• Computation takes into account historical information• Weights are shared across time | • Computation being slow• Difficulty of accessing information from a long time ago• Cannot consider any future input for the current state |
Architecture of Basic RNN Block
Basic RNN Block contains 3 Weight Matrices which are used to calculate hidden state and output of the block.
Some Symbolic Notation ( Common for all layers ) :
- a : Hidden state Vector
- g : activation function
- y : output vector
- w : weight matrix ( different for each time )
The initial Hidden state vector or a<0> will be all zero.

So, we follow these equations to calculate hidden state and output for each time,

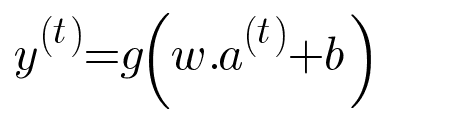
Architecture of GRU Layer
The drawback of Basic RNN Block is that it can not capture long range sequences correctly.
this problem is known as vanishing gradient problem.
So in GRU Layer we only update hidden state when required and then it can carry longer sequences.
We represent “h” as the hidden state of GRU instead of “a” (in Basic RNN).
Moreover GRU contains two gates: –
- Relative Gate
- Update Gate

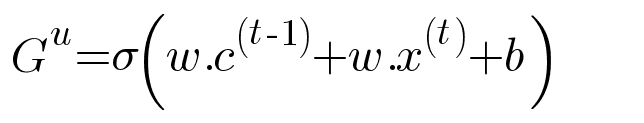



Architecture of LSTM Layer
The LSTM layer is the complex version of GRU Layer and so resolves the problem known as vanishing gradient problem much accurately.
Basically it has 3 Gates and two carry components, one is hidden state and another is carry or conveyer belt.
The equations of LSTM layer are as follows :



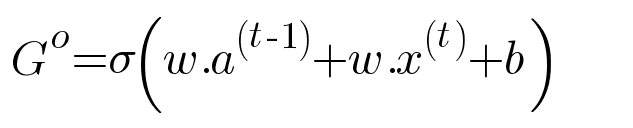



CONCLUSION
So this was the Introduction to Recurrent Neural Network, Now you can implement these formulas to use RNN in your project and You can also use Tensorflow’s API , which provides all of this implementation, you just need to import them.